sed and awk will always rock
Fresh off our discussion regarding PowerShell, now for something completely different. In order to bring balance to the force I felt I should share with you my recent use of sed, "the ultimate stream editor" and awk, "an extremely versatile programming language for working on files" to solve one of fourteen challenges in a recent CTF exercise I participated in.
The challenge included only a legitimate bitmap file (BMP) that had been modified via least siginficant bit (LSB) steganography and the following details. The BMP was modified to carry a message starting at the 101st byte and only in every 3rd byte thereafter. The challenge was therefore to recover the message and paste it as the answer for glory and prizes (not really, but pride points count). What was cool about this CTF is that while a number of my associates participated not one of us approached the challenge the same way. One used Excel with VB, another used AutoIT, and yet another wrote his own C#. Since I'm not as smart as any of these guys, I opted to trust the force and use our good and faithful servants sed and awk on my SIFT 3.0 VM along with a couple of my preferred editors (010 and TextPad) on my Windows host. I know, I know, "WTF, Russ, just do it on one system." I can say only that I am fixed in my ways and like to do certain things with certain tools, so I'm actually faster bouncing back and forth between systems. Here's what I did in seven short steps, with some details and screenshots. Note: I share this because it worked and I enjoyed it, not because I'm saying it's an optimal or elegant method.
1) I opened the .bmp in 010 Editor and first deleted bytes 1 through 100 given that the message starts at the 101st byte. Remember, if you choose to do this by offset the first byte is offset 0 and the 101st is the 100th offset. This critical point will be pounded (literally) into your head by Mike Poor when taking the GCIA track, which I can't recommend enough. Then under View chose Edit As and switched from Hex to Binary (remember we're working with the least significant bit). I then selected all binary, chose Copy As, and selected Copy As Binary Text which I saved as challenge13binaryRaw.txt.
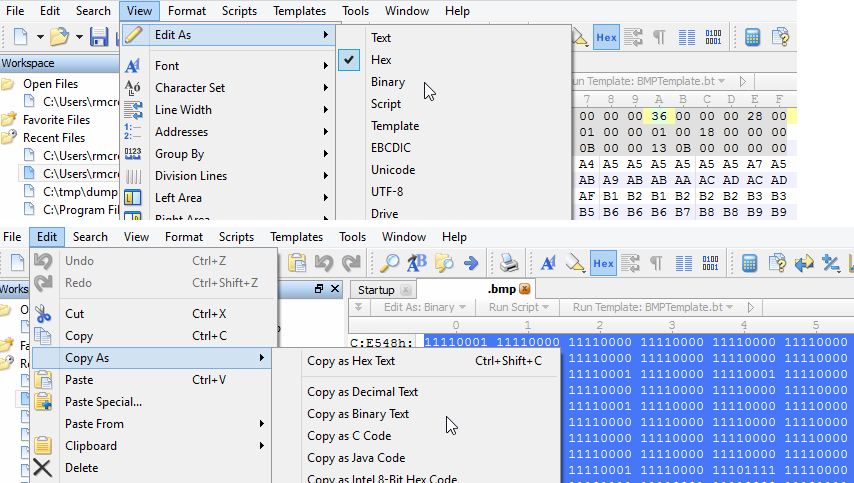
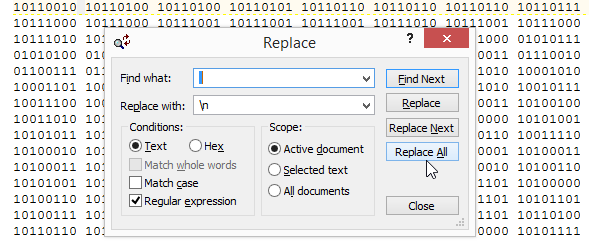
2) I opened challenge13binaryRaw.txt in TextPad because I love its replace functionality. The binary text output from 010 Editor is separated by a space every 8 bits/1 byte. In TextPad I used a regular expression replacement to convert the text to a single column (replaced every space with a newline \n), which I saved as challenge13binaryRaw-column.txt.
3) I then used sed on challenge13binaryRaw-column.txt to print only every third byte, described in the challenge description as those containing the message, and saved it to every3rd.txt as follows: sed -n '1~3p' challenge13binaryRaw-column.txt > every3rd.txt. In this syntax, sed simply starts at the 1st line then prints every 3rd ('1~3p').
4) To then grab the least significant bit from each line of every3rd.txt I used awk as follows: awk '{print substr($0,8)}' every3rd.txt > lsb.txt. This tells awk to grab the 8th character of each line and print it out to lsb.txt, the 8th character representing the least significant bit in each 8 bit byte.
5) lsb.txt now contains only the message but I need to format it back into machine readable binary for translation to human readable text. Back to TextPad where I used another regex replacement to convert a long column of single bits back to one line and save it as lsb-oneline.txt. Replacing a carriage return (\r) with nothing will do exactly that.

6) In order for machine translation to successfully read the newly compiled message traffic, we now need to reintroduce a space between every 8 bits/ 1 byte which we can again accomplish with sed and save it to finalBinary.txt as follows: sed 's/\(.\{8\}\)/\1 /g' lsb-oneline.txt > finalBinary.txt
7) I then copied the content from finalBinary.txt into a binary translator and out popped the message.
It was actually the same short message looped many times through the BMP but I went for overkill extracting it not knowing the parameters other than those defined by the challenge description (no mention of how long the message was). A bit clunky to be sure but for you forensicators looking for ways to pull out messages or content embedded via LSB steganography, this approach might be useful. And no, I'm not telling you what the message was or sharing the BMP file in case the CTF administrators wish to use it again. :-) You'll want to brush up on your regex; one of my favorite resources is here.
Cheers and enjoy.


Comments
To replace the blank spaces with carriage returns
in vi - :%s/ /\r/g
in sed - s/ /\r/g
And to put them back, just reverse the regex. And then buy the shirt! https://xkcd.com/208/
Anonymous
May 19th 2014
1 decade ago
Anonymous
May 20th 2014
1 decade ago
xxd -p -c3 -s+100 steg.bmp | sed '/^....//' | xxd -r -p -c1 - hidden-file.bin
-p don't print indexes on the hexdump
-c3 print three columns
-s+100 skip the first 100 bytes
sed remove the first four columns, removing the first two bytes
xxd -r reassemble a binary from hex
-p there are no indexes
-c1 only one column/byte of hex
An alternative method to get same hexdump, without reassembly uses od:
od -t x1 -v -w3 steg.bmp -j 100 | grep -v "^[0-9a-f]*$" | cut -d' ' -f4
-t x1 format as a hexdump
-v don't skip zeros
-w3 make three columns(three bytes per line)
-j 100 skip first 100 bytes
grep -v remove lines with just an index but no bytes
cut choose the fourth column/every third byte
Unfortunately, od doesn't do re-assembly, so the first method is the most simple. One can used sed, awk, and other text-utils (fmt, cut) to re-arrange the hex as needed to suit your pattern.
Anonymous
May 22nd 2014
1 decade ago