It is a resume - Part 3
In this short series of diary entries, I show how I try to conclude that a PDF file (a resume) is not malicious, but benign. This is the last part. Thanks to Xavier for letting me post this during his shift.
The PDF file itself is not large, in part 1 we were able to analyze and understand all elements of the PDF document, and know for sure that it does not contain malicious code.
The document contains one image (JPEG), and in part 2, we scanned the image for (malicious) code, but found nothing. The fact that our scans turned up clean, does not prove that the image does not contain malicious code, it merely shows that we were not able to find such code (whether such code is present or not).
In part 3, we will try to dissect the JPEG image, and try to understand all elements of its structure, hoping to find anomalies.
I did a small intermezzo on the analysis of JPEG files, and armed with that knowledge, we will dig deeper into the image of the PDF.
With pdf-parser.py, I extract the image from object 3 and pipe it into jpegdump.py:
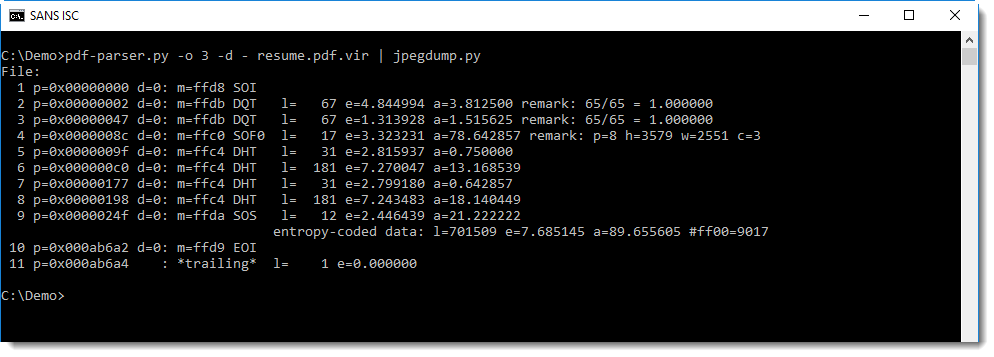
First of all, we see that all markers are present, that the Start Of Image marker starts at position 0, and that the End Of Image marker is the last marker. There is one trailing byte (entry 11, length 1) but that is an artefact from the PDF extraction. When we dump it, you can see that it is a newline character:

There are not unexpected bytes between the markers and their data (all d= values are 0), and the data also has entropy values (e=) that can be expected for that type of data (compare this with other JPEG images).
The value of a= is the average difference between 2 consecutive bytes, it is a measure for the rate of change in a sequence of bytes.This value is low for quantization tables (DQT), which is normal, and also normal for Hufmman tables (DHT) when we compare this we other examples of JPEG images.
When we dump the data of the different markers (except the SOI marker), we find no anomalies:
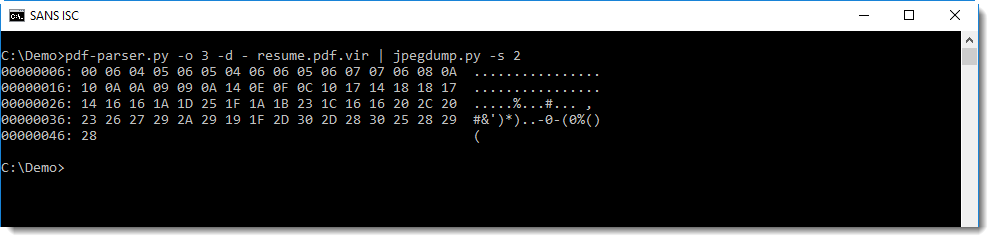
This is the data of the first quantization table. You can see that the byte values do not change much, which produces low e= end a= values.
With this method, and also with 010 Editor, I was able to inspect the data of all markers, except the SOS marker. I found no anomalies, and no indication of a place where shellcode, ROP chains, ... could have been stored.
Let's focus on the Start Of Scan marker and its data. The SOS marker is a marker that is followed by entropy-encoded data (the actual image)
When we select marker 9, the data for this marker is dumped. This is just 10 bytes long:

To dump the data of the image (e.g. the entropy-code data), select 9d (d stands for data):
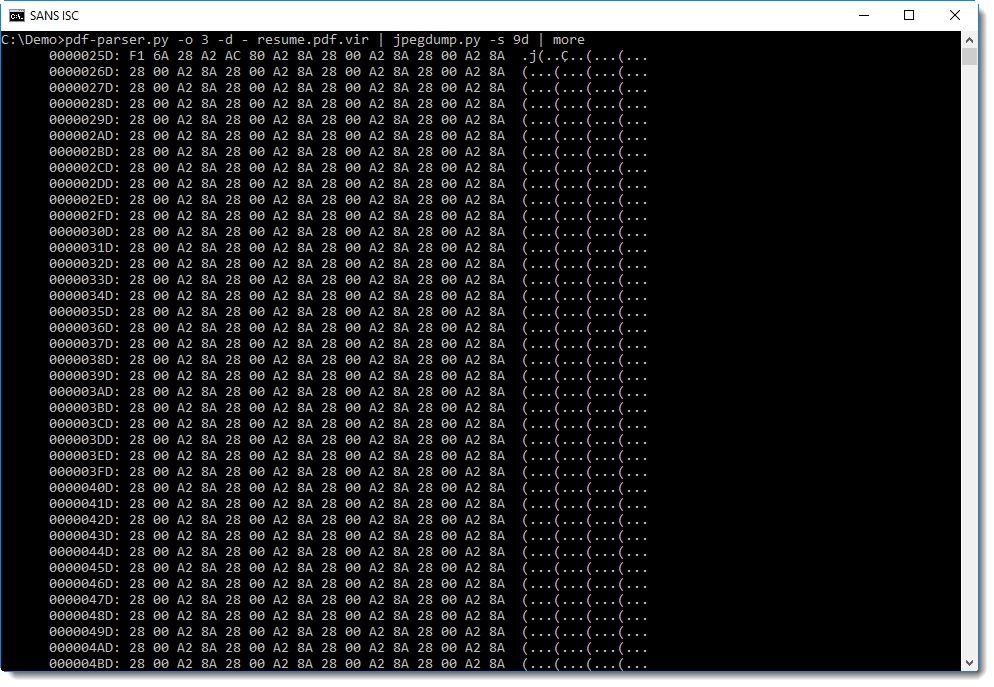
Although we see a lot of repeating bytes here, this data segment is much longer (l=701509 bytes, as can be read from the line after marker 9) and with a high entropy (=7.68...) and a high average of byte differences (a=89....).
Entropy-coded data can also contain (some) markers. All JPEG markers start with byte 0xFF, so image data represented by 0xFF could be mistaken for a marker. To prevent this, byte-stuffing is applied: every entropy-coded data byte with value 0xFF is followed by value 0x00, to distinguish it from a marker. jpegdump.py counts these stuffed bytes too: in this image, there are 9017 such cases.
The fact that the entropy-coded data of the SOS marker has no 0xFF values not followed by 0x00, is another indication that this data is normal.
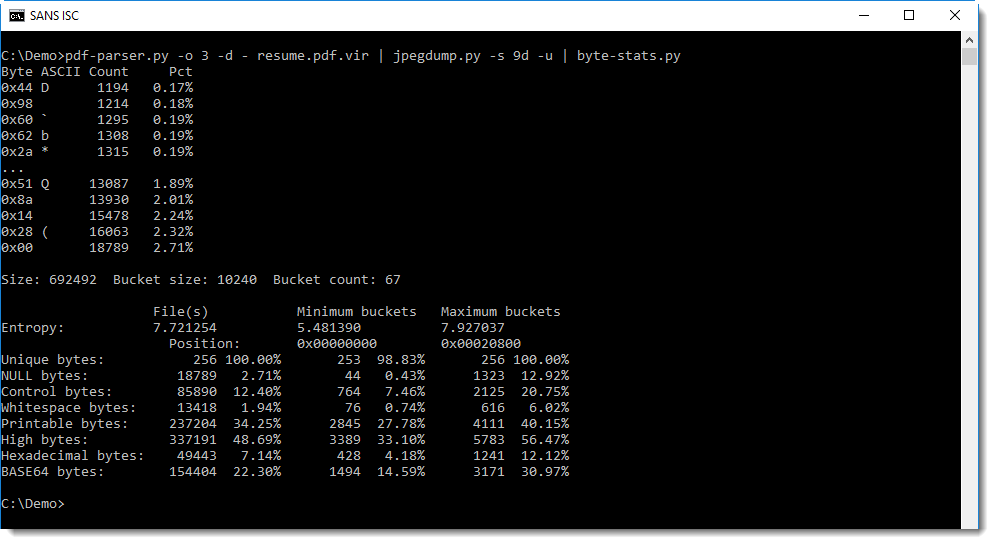
When we calculate statistics for the byte in the entropy-coded data, we see that there are more 0x00 bytes than other values (27806 bytes):
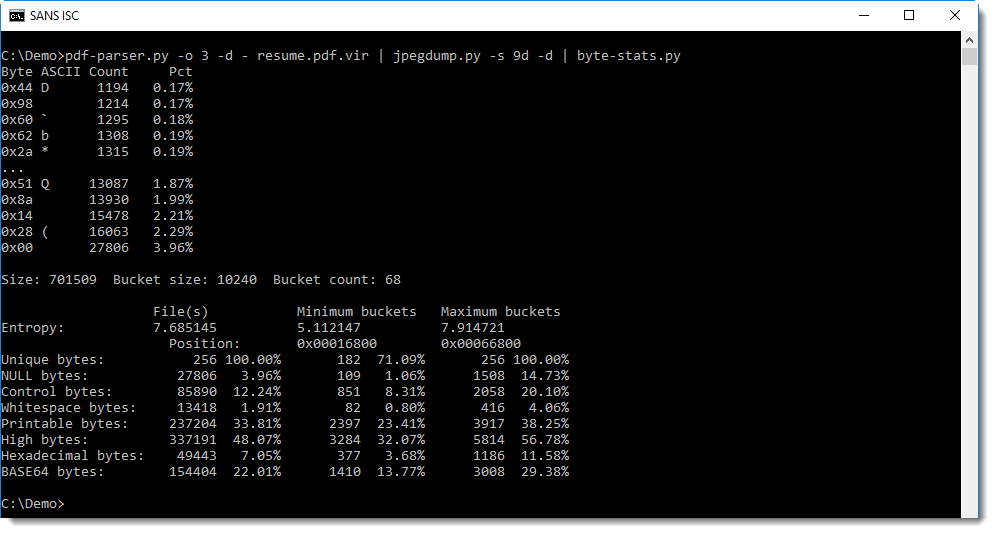
One could think that this is an indication for the presence of byte sequences with lower entropy in the data stream, like code or payload data, but it is actually an artifact of the byte-stuffing process.
We can remove this byte-stuffing by using option -u in stead of -d to dump the entropy-coded data. Option -u will dump data like -d, but it will replace all occurences of 0xFF00 by 0xFF (e.g. undo the byte-stuffing).
This produces normal values for 0x00 prevalence:
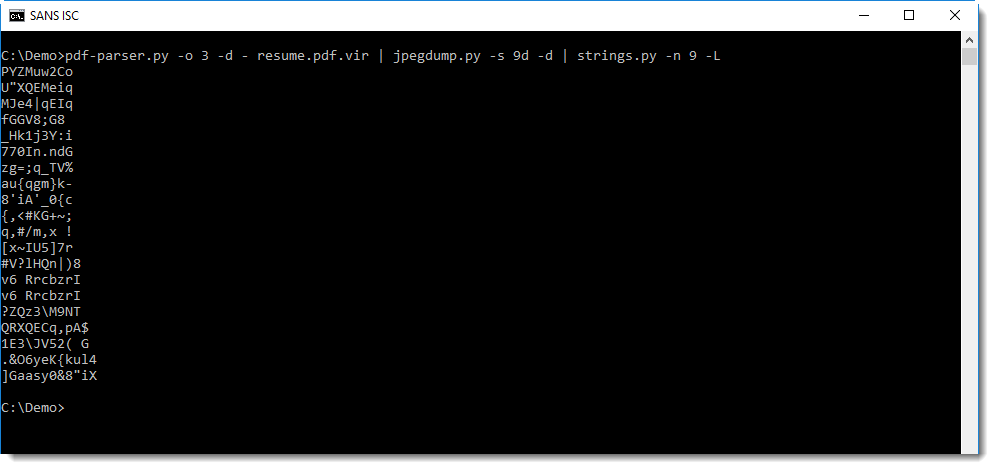
700 Kbytes is too much to search through manually, so we will try a few detections.
Like looking for strings:
Or looking for sequences of bytes with the same difference:
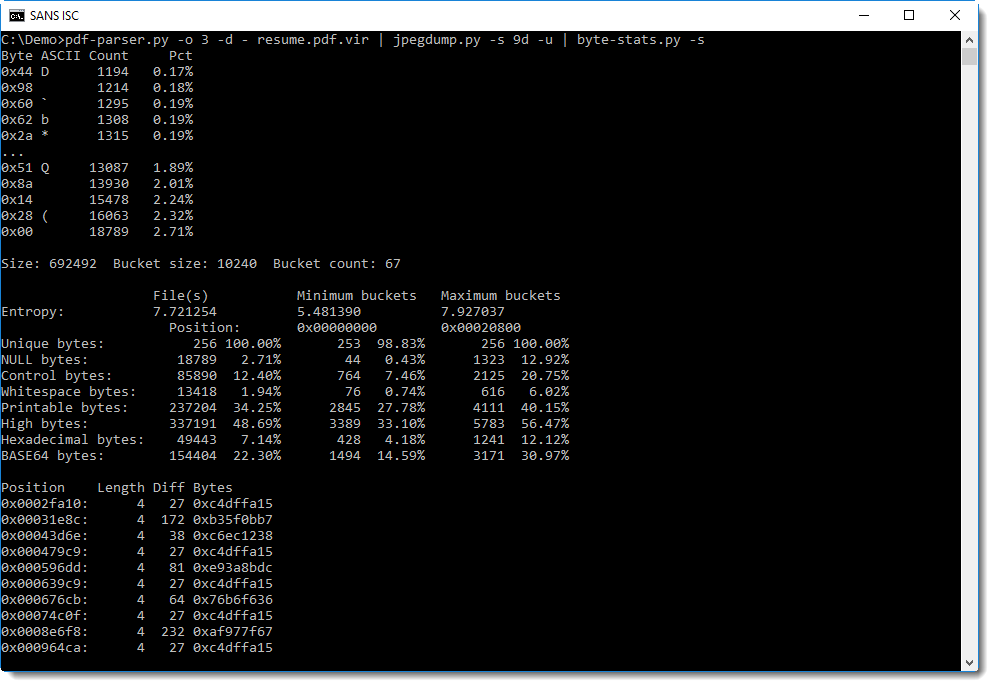
But both methods yield nothing.
As a last resort, we can chart the entropy:
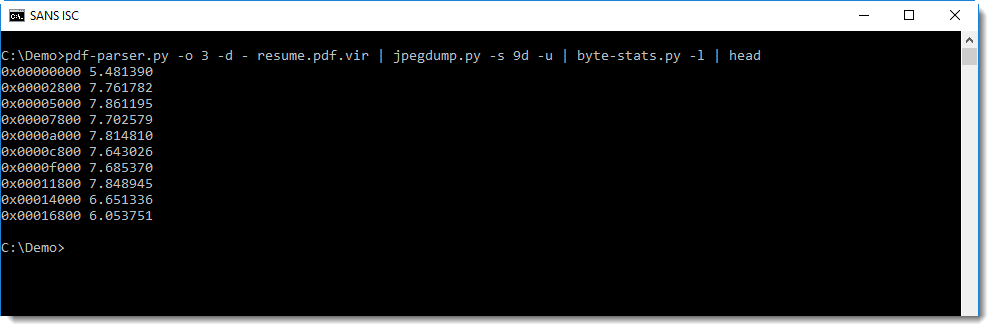
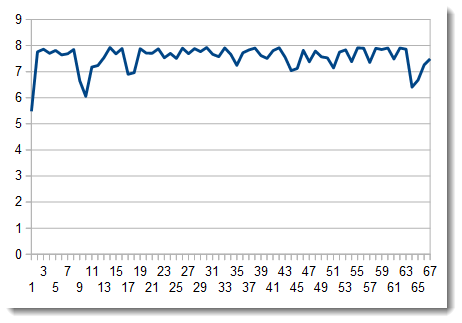
There are a couple of dips in the entropy, but when we take a closer look at those sequences, they turn out to be short repeating sequences, like the ones at the beginning of the entropy-coded data. These sequences correspond to larger regions in the image with uniform colors.
I don't know (yet) how to decompress the entropy-coded data with the Huffman tables, so my search for anomalies has to stop here.
Conclusion
I know that there is no malicious code in the PDF, and neither in the data of the markers of the JPEG image (except for the SOS marker), because I was able to decode and validate all data. It is still possible however that there is data there that would trigger a bug, but there is no code to exploit it.
As for the entropy-encoded data, there could be malicious code there, but if it is, then it blends in with the entropy-coded data because simple statistical methods do not find code.
I'm confident that this PDF does not contain malicious code, and I can show it to some extend, but I can not be 100% sure. And this will often be the case, especially with more complex documents.
Finally, I did open the image inside a VM, and it is indeed a resume. As a last test, I changed some bytes at the end of the entropy-coded data, and displayed the image again: there was some corruption at the bottom-right corner of the image. This is an indication that there is no payload appended to the end of the entropy-coded data.
Didier Stevens
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments
Anonymous
Sep 27th 2017
8 years ago