It is a resume - Part 1
I received a resume (a PDF) via email. It was not malicious, it was a real resume, and it's a good opportunity to show how to determine if a PDF contains nothing malicious.
First, I analyzed the PDF with pdfid.py:
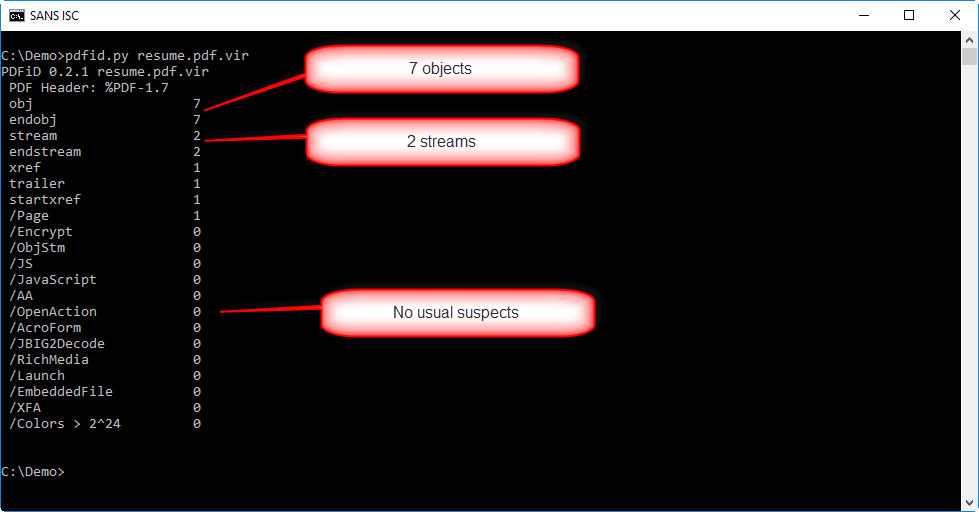
The PDF has not a lot of objects (7) neither streams (2). And there's no other warning from pdfid.py. That doesn't mean the pdf is not malicious, it could still contain an exploit for a (un)known vulnerability.
In such a case, I like to use option -e from pdfid to get more info:
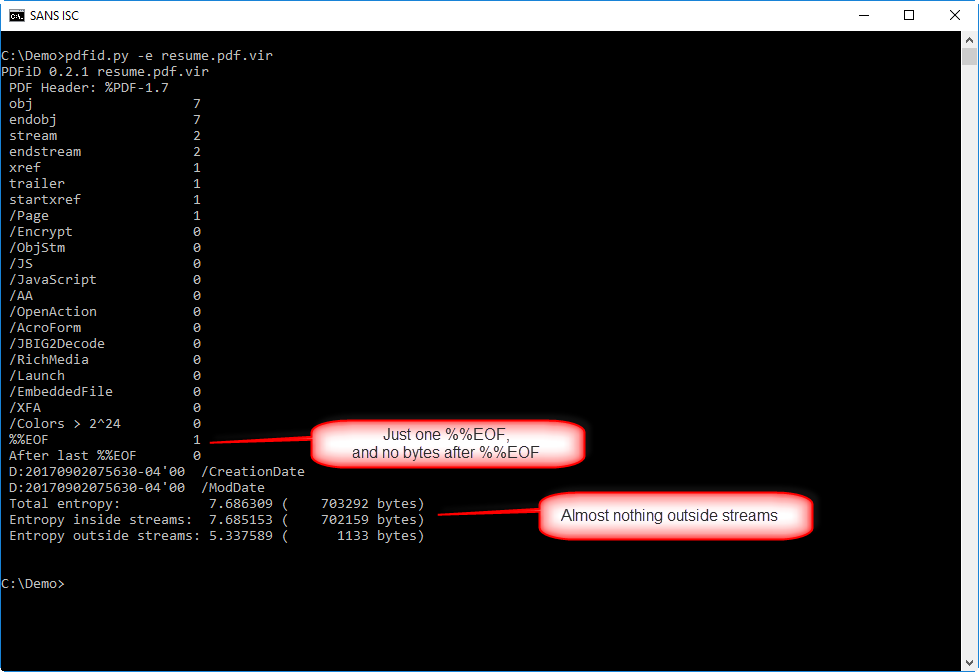
This info helps to determine if there is something hiding in this PDF outside the normal objects.
There's just one end-of-file marker (%%EOF), and there are no more bytes following that marker, so nothing was appended to this PDF.
And there are very few bytes outside streams (1133), so it's unlikely something was hidden there.
Lately, we've seen several PDFs campaings with just a URL in the document pointing to malware.
Let's check this with pdf-parser.py:

Nothing!
So this PDF has a lot of indications that it is not malicious.
If needed, we can go deeper in our analysis. In such a case, I like to use pdf-parser.py to pull some statistics on the objects inside the PDF:

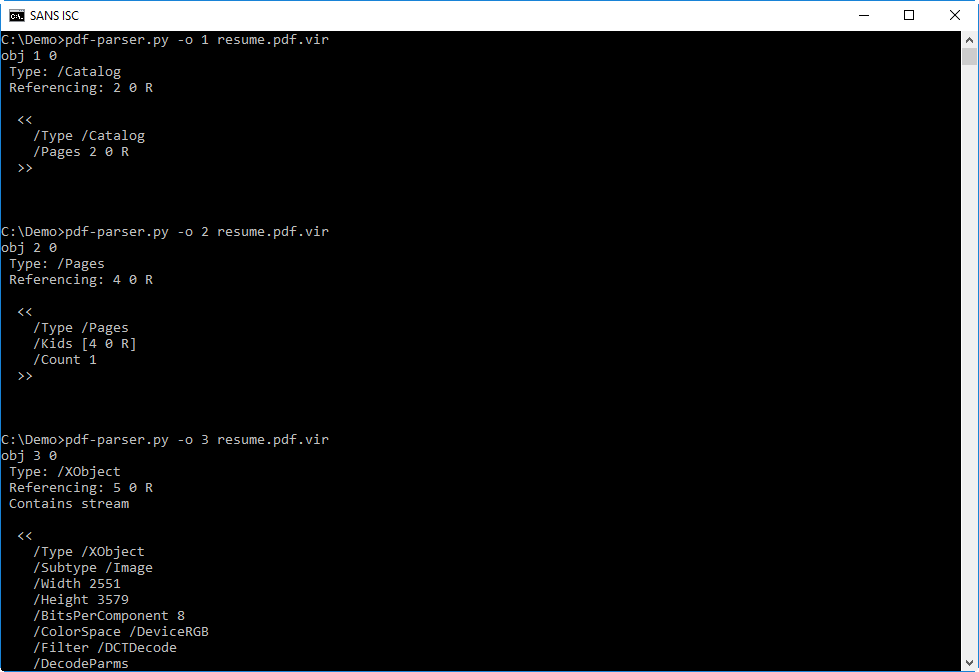
This is a very simple PDF, with only 7 objects:
- 1 catalog object (object 1)
- 1 pages object (object 2)
- 1 page object (object 4)
- 1 XObject object (object 3)
- and 3 objects without a type (objects 5, 6 and 7)
PDF with objects like these are usually just a document with an image like a JPEG (object XObject) inside it.
When I look at the different objects, there is noting that stands out:
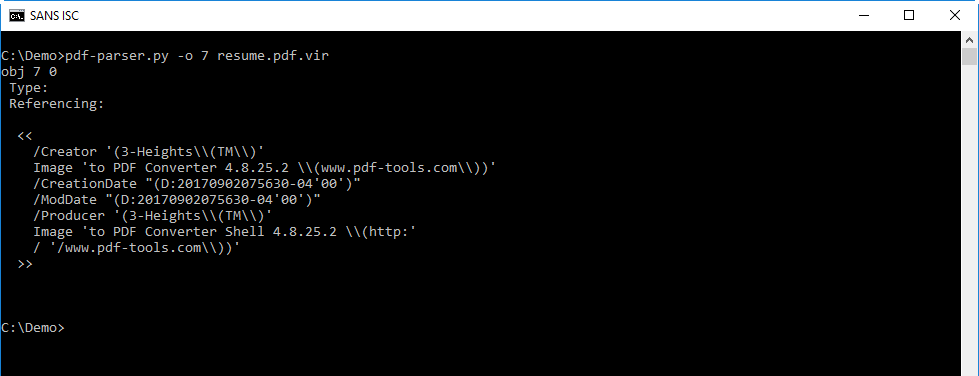
Object 7, with the metadata, gives me a clue as to the origin of this PDF:
So there is not malicious to find. The only remaining place where something could be hiding, is in the streams of objects 3 and 6.
The stream of object 6 is deflated (/FlateDecode), and can thus be decompressed with option -f:
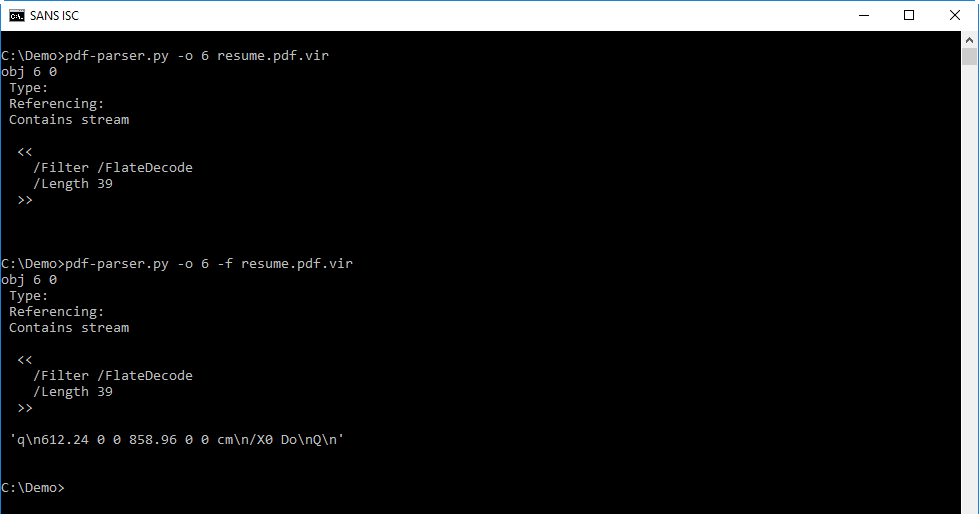
You will probably not recognize the code in the decompressed stream, but this isa description of a page (defining it's size and displaying an image). So nothing malicious here.
What remains, is the image in object 3. There could be an exploit hiding in there, and in part 2, we will see if we can find one.
Didier Stevens
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments
Anonymous
Sep 21st 2017
8 years ago