Baselining Servers to Detect Outliers
Introduction
This week I came across an interesting incident response scenario that was more likely a blind hunt. The starting point was the suspicion that a breach may have occurred in one or more of ~500 web servers of a big company on a given date range, even though there was no evidence of leaked data or any other IOC to guide the investigation. To overcome time and environment restrictions, we ended up with a simple quick start approach that allowed us to collect some “low-hanging fruits” by writing a tool, now available at GitHub [1], to automate the process, detailed in today’s diary.
Scenario
When it comes to hunting activities like this one, approaches may vary, but they usually pass through log and traffic analysis and running anti-malware and root kit detection tools to identify compromised systems. Our case is a little different; let me give you an overview of our requirements and restrictions:
- The servers were hosted on a cloud provider with no network or security solution that could easily give visibility over the servers’ network traffic. With some effort, one could barely have a view of the network flows with limitations to export them to a log manager or a SIEM. There was a SIEM, but it was collecting just the application layer logs;
- A Host Intrusion Detection System (HIDS) could be very useful as violations on the hosts could be easily identifiable, but there was none;
- As we were dealing with a production environment, deploying new packages on the servers would require approvals, that would take long to obtain. So, quick results from tools like lynis, chkrootkit and rkhunter were out of question;
- Finally, as any other incident response, answers had to be given ASAP.
Another interesting characteristic of the environment was that, despite the number of servers, they could be classified into a limited number of groups based on their tasks. That is, there was a group of servers responsible for the APIs, other responsible for the frontend of the application A, other of B, and so on in a manner that each server group shared a quite similar operating system and applications as they were dynamically instantiated from the same baseline image.
Looking for anomalies
While we were waiting for the authorization and deployment of the host analysis tools mentioned above and part of the team was analyzing and correlating logs into SIEM, we started brainstorming strategies that could allow us to analyze the hosts for indications of compromise. The similarities between servers was the key.
So, if we could compare servers in terms of system characteristics among groups, those that do not follow “the pattern” should be considered suspect. In other words, if someone has deployed a web shell on a pivot server, for example, this server would be distinguishable within the group and, thus, would appear on the comparison.
Following this approach, three system characteristics were selected to look for anomalies: list of files, list of listening services and list of processes. To automate the task, a python tool was written, as detailed on the next section.
Distinct.py
After testing the approach by issuing isolated remote “find” and “grep” commands, and validating that uncommon characteristics would pop up, it was time to put all the pieces together.
First, Distinct, as we named the tool, receives a list of servers as input and performs the following information gathering tasks through remote SSH command execution:
- With “find”, it lists file paths to be compared. It supports a time range filter based on creation and modification file time;
- With “ps”, it lists all running applications and its parameters;
- With “netstat”, it lists all listening network ports on the server;
- As “find”, “ps” and “netstat” commands may have been modified by an attacker, there is another option to compare the tools hashes among servers – following the same approach;
- Additionally, the user may give a whitelist parameter with a list of words that should be excluded from comparison. It is useful to avoid file names naturally different among servers (i.e.: access.log.2017100301.gz into the /var/log path).
Then, it basically compares the results by sorting the lists and counting the items (file paths, listening services and running applications) repetitions. The items with a repetition count smaller them the number of compared servers, indicates that a given item is anomalous and, thus, must be investigated. For example, a file like /var/www/a.php present in one of, let’s say, 100 servers will have a count of 1 and, therefore, will appear on the output. The same will occur for uncommon listening services and processes.
Usage
See below distinct.py first version’s supported parameters:
$ python distinct.py -h
usage: distinct [-h] -f F [-k K] -u U [-o O] [--files] [--path PATH]
[--startDate STARTDATE] [--endDate ENDDATE] [--listening]
[--proc] [--criticalbin] [--whitelist WHITELIST] [--sudo]
Where:
-f <F>: F is path of the file with the list of servers to be analyzed;
-k <K>: K is the path of the private key for the SSH public key authentication;
-u <U>: U is the username to be used on the SSH connection;
-o <O>: Optional output path. The default is “output”;
--files: switch to enable file list comparison. It supports these option additional arguments:
--path: specify the find path (i.e: /var/www);
-- startDate and --endDate: accepts the time range filter based on the file time modification time;
--listening: switch to enable listening services comparison;
--proc: switch to enable proc list comparison;
--criticalbin: switch to enable critical binaries (find, ps and netstat) MD5 hash comparison;
--whitelist: a file with a wordlist (one per line) to be excluded from the comparisons.
--sudo: Use 'sudo' while executing commands on remote servers
Example:
Looking for uncommon files on a given path, created or modified on a given period, on a group of servers:
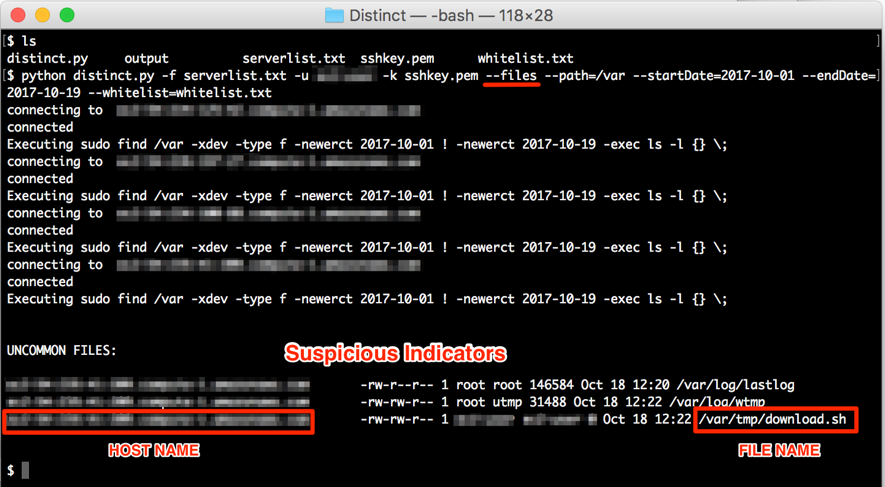
Figure 1: Looking for uncommon files among servers
Final words
The approach to use a group of similar servers as a baseline to detect outliers may be very useful (and was in our case) as a primary source of suspicious indicators to be considered while responding to an incident, especially when there isn’t a file integrity monitor or other HIDS features in place. However, it is important mentioning that having no indication of anomalous files or processes detected, does not mean that there is no breached server. An attacker may delete its track and/or use kernel level rootkits to hide processes from tools like “ps” and “netstat”– even the legitimate ones. There is another case where there are no outliers: all servers have been compromised the same way.
Aside those tricky scenarios, I hope the tool may be useful for other people within similar hunting scenarios or even for system administrators willing to find configuration errors on a bunch of servers.
Finally, the tool may be extended to support other comparisons, like system users and, who knows, a version to support analyzing Windows Servers.
References
[1] https://github.com/morphuslabs/distinct
--
Renato Marinho
Morphus Labs| LinkedIn|Twitter


Comments