Another PDF Streams Example: Extracting JPEGs
In my diary entry "Analyzing PDF Streams" I showed how to use my tools file-magic.py and myjson-filter.py together with my PDF analysis tool pdf-parser.py to analyze PDF streams en masse.
In this diary entry, I will show how file-magic.py can augment JSON data produced by pdf-parser.py with file-type information that an then be used by myjson-filter.py to filter out files you are interested in. As an example, I will extract all JPEGs from a PDF document.
First, let's produce statistics with pdf-parser.py's option -a:
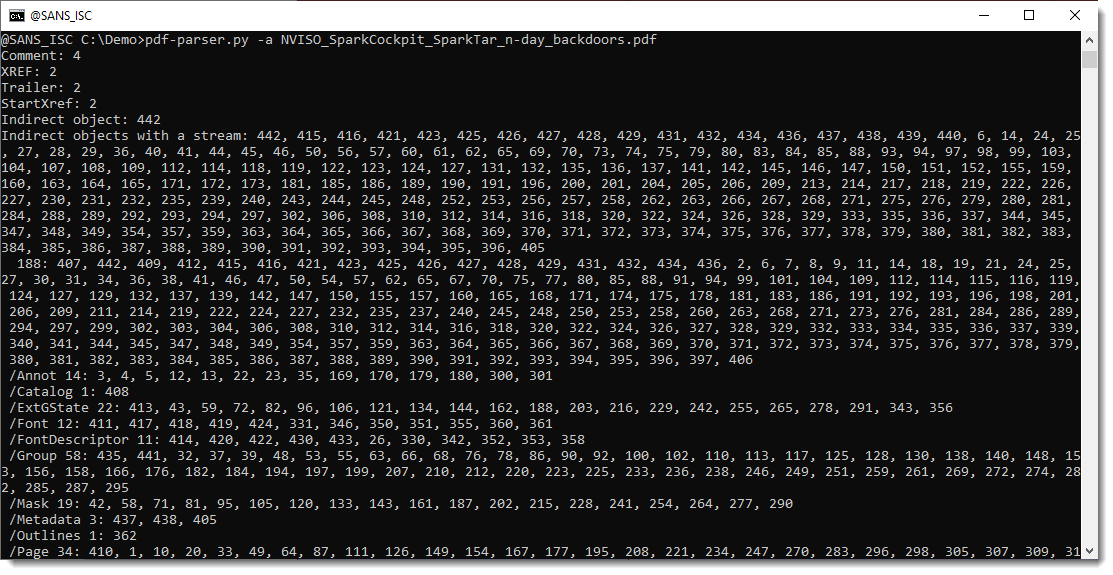
This confirms that there are many "Indirect objects with a stream" in this document.
Next, I let pdf-parser.py produce JSON output (--jsonoutput) with the content of the unfiltered streams, and I let file-magic.py consume this JSON output (--jsoninput) to try to identify the file type of each stream based on its content (since streams don't have a filename, there is no filename extension and we need to look at the content):
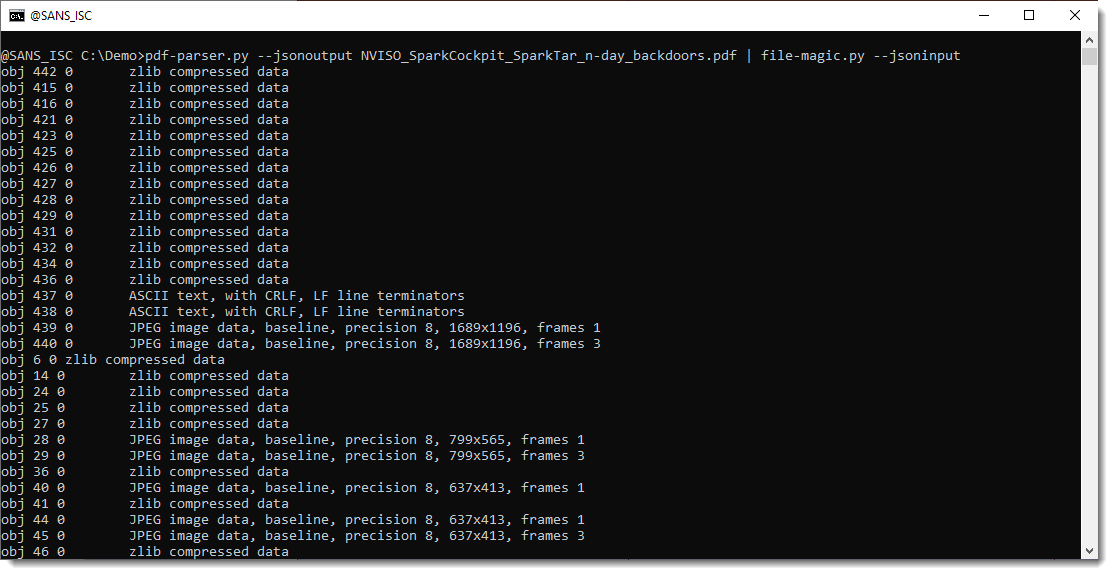
If we use option -t to let file-magic.py just output the file type (and not the file/stream name), we can make statistics with my tool count.py and see that the PDF document contains many JPEG files:

Now we want to write all of these JPEG images to disk. We use file-magic.py again in JSON mode, but let it also output the same JSON data augmented with file-type information (--jsonoutput):

Next, this JSON data is consumed by myjson-filter.py and filtered with regular expression (case sensitive) JPEG on the file type: -t JPEG.
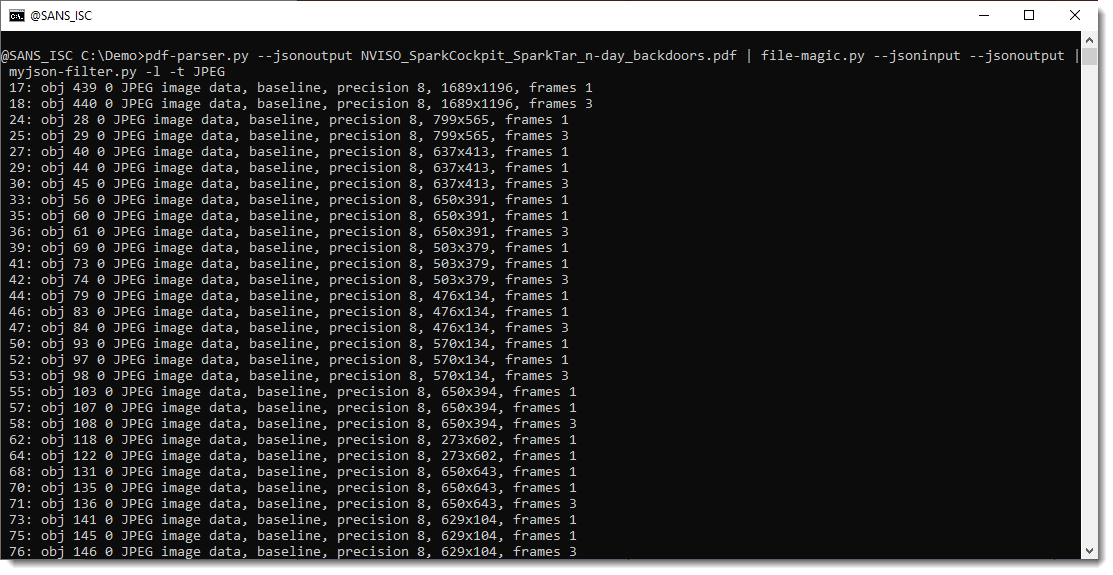
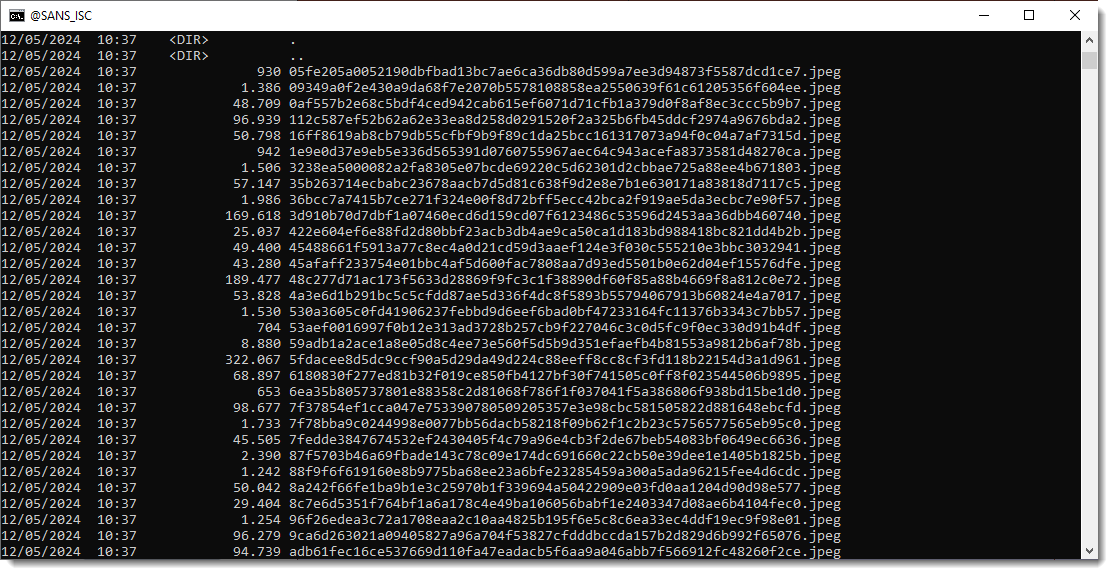
Finally, we write the JPEG images to disk with -W hashext:jpeg: this writes each JPEG stream to disk with a filename consisting of the sha256 of the file's content and extension .jpeg.
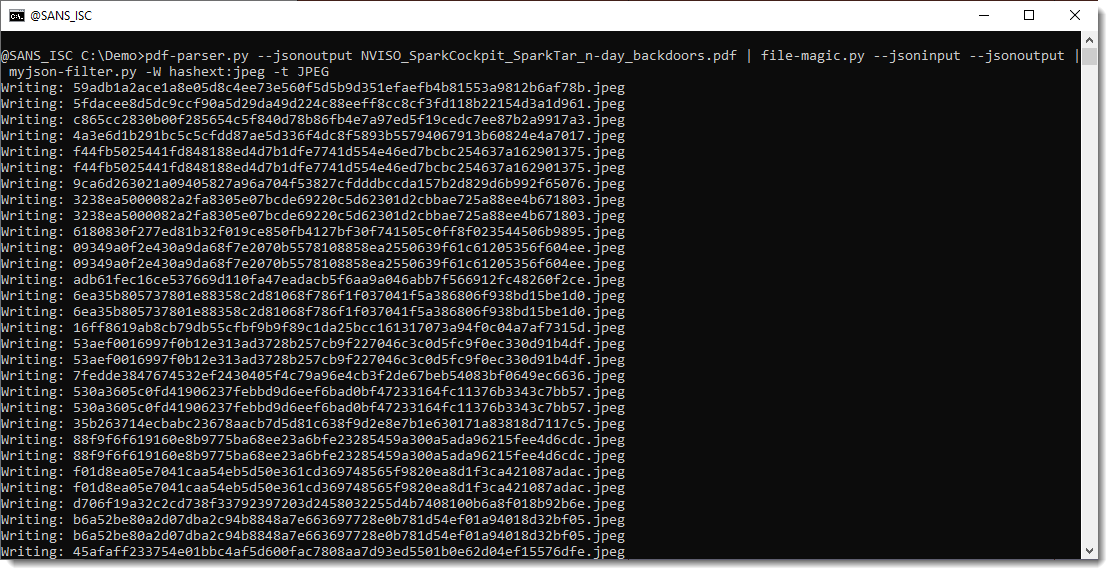
By using the hash of the content as filename, there are no duplicate pictures:
Should you want to reproduce the commands in these diary entries with the exact same PDF files I used, my old ebook on PDF analysis can be found here and the analysis on TLS backdoors done by a colleague can be found here.
Didier Stevens
Senior handler
blog.DidierStevens.com


Comments