When Hunting BeEF, Yara rules (Part 2)
This is a Guest Diary submitted by Pasquale Stirparo.
In my previous diary [https://isc.sans.edu/forums/diary/When+Hunting+BeEF+Yara+rules/20395], we had a look at a phishing attack scenario, where we were using BeEF to abuse the user’s browser, steal his credentials and deliver a successful attack that would give remote access. As mentioned, at an initial analysis, BeEF appeared to be pretty stealthy and main artifacts were retrievable only in memory. This is where Yara came into help. For your information, if would like to test/check the rules, you can find all the Yara rules mentioned in this diary on my github page [https://github.com/pstirparo/yara_rules].
BeEF has one main javascript that is used to hook the browser, hook.js, and then 3 files in each module: [https://github.com/beefproject/beef/wiki/Module-creation]:
- config.yaml, the YAML configuration file which describes properties of the module
- module.rb, integrates the module into the BeEF web interface
- command.js, the javascript "payload" which will be executed on the hooked browser
I wrote the following Yara rule, taking strings from the hook.js source, and confirmed that it correctly detects artefacts of hook.js in memory.
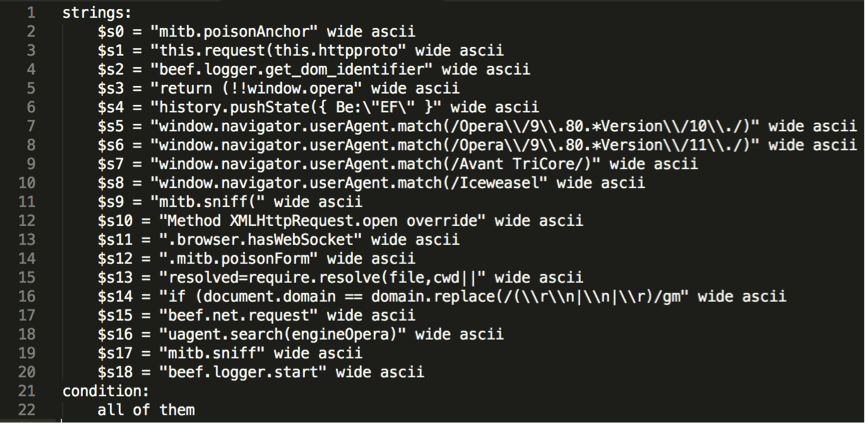
In a second step, I used yarGen [https://github.com/Neo23x0/yarGen] to automatically generate two other Yara signatures, one for hook.js and one for command.js, for the “Pretty Theft” module (see below).
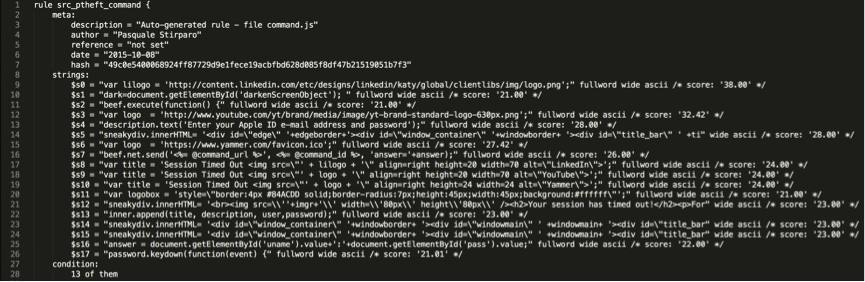
Talking about yarGen, one of the awesome features is that it ships with a huge (literally) string database of common and benign software, generated from Windows system folder files of Windows 2003, Windows 7 and Windows 2008 R2 server, typical software like Microsoft Office, 7zip, Firefox, Chrome, etc. and various AV solution. Of course, such database can also be enhanced and customized by the user. Pointing yarGen to the target sample (hook.js or command.js in this case), it extracts all ASCII and UNICODE strings from the sample, removing those that do also appear in the goodware string database. Then it evaluates and scores every string by using fuzzy regular expressions and the “Gibberish Detector” that allows yarGen to detect and prefer real language over character chains without meaning. The top 20 of the strings will be integrated in the resulting rule.
The power of yara is already well known, and its potential when applied to memory is even greater. Here are some take aways from these tests that I would like to share:
- when hunting memory with yara, always put both “wide ascii” attributes to your strings, because you never know how they are represented (see code snippet below).
- Matching conditions need to be tuned properly. Unlike when using yara against a binary, where you have the full file content, in memory you may only get remnants of what you are looking for. Making all 20 signatures returned by yarGen mandatory might make you miss partial matches. Requiring ~15 matches turned out to be a good trade-off between catching real artefacts and avoiding false positives.
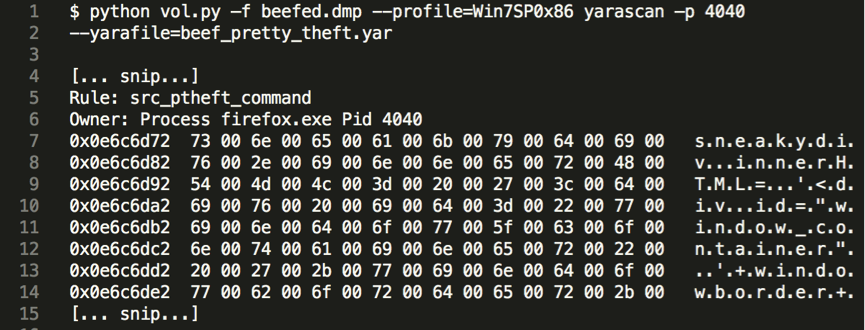
To conclude, all the three rules mentioned matched on the memory dump of the infected machine, confirming therefore that BeEF and the specific module were used in the attack. Since it is not difficult to obfuscate the BeEF modules, the yara rules still need some further development to accurately match also in such situations.
For those using Yara (beginners and more experienced users alike), I would suggest to read “How to Write Simple but Sound Yara Rules” [https://www.bsk-consulting.de/2015/10/17/how-to-write-simple-but-sound-yara-rules-part-2/] by Florian Roth, author of yarGen, which gives plenty of advice on how to write very effective rules.
Happy Hunting,
Pasquale


Comments