Sophisticated, targeted malicious PDF documents exploiting CVE-2009-4324
Couple of days ago one of our readers, Ric, submitted a suspicious PDF document to us. As you know, malicious PDF documents are not rare these days, especially when the exploit for a yet unpatched vulnerability is wide spread.
Quick analysis of the document confirmed that it is exploiting this vulnerability (CVE-2009-4324 – the doc.media.newPlayer vulnerability). This can be easily seen in the included JavaScript in the PDF document, despite horrible detection (only 6 out of 40 AV vendors detected this when I initially submitted it here).
After extracting the included JavaScript code, the shellcode that it uses looked quite a bit different than what we can usually see in such exploits: this shellcode was only 38 bytes long! Initially I even thought that it does not work, but after studying it a little bit, I found that this particular PDF document has some very interesting, sophisticated characteristics.
The exploit for this vulnerability is similar to most other exploits: it uses heap spraying in order to redirect the execution to shellcode. The NOP sled in this case actually consists of SBB AL,0x1C and SBB AL,0x0C instructions which do nothing (SBB is Subtract with borrow, from the register AL, so it keeps subtracting two values until it reaches the shellcode). The 38 bytes shellcode can be seen below:
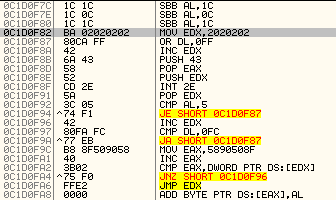
Now comes the interesting part. This is an egg-hunting shellcode: it starts at the memory address ((0x02020200 OR 0xFF) + 0x01) = 0x02020300) and compares content of every 4 bytes with 0x58905090. You can see that initially the attacker moves 0x5890508F into the EAX register, which then gets increased by one – this was probably done to evade detection.
This pattern (0x58905090) corresponds to instructions POP EAX, NOP, PUSH EAX, NOP. Now, once this pattern has been identified in memory, the egg-hunting shellcode passes execution to this, second stage shellcode.
What is interesting about this approach is that the second stage shellcode is included as a different object in the PDF document. While the object is marked as a color object and its contents are inflated, it looks as if it is corrupted: it does not contain any inflated streams. You can see the object and the deflation error printed by pdf-parser, an excellent tool by Didier Stevens whom I wish to thank for useful discussion while I was analyzing this malicious PDF document:
$ pdf-parser.py --object 3 --raw --filter Requset.pdf
obj 3 0
Type:
Referencing:
Contains stream
<</BitsPerComponent 8/ColorSpace/DeviceRGB/Filter/FlateDecode/Height 90/Length 13136/Subtype/Image/Width 60>>
<<
/BitsPerComponent 8
/ColorSpace /DeviceRGB
/Filter /FlateDecode
/Height 90
/Length 13136
/Subtype /Image
/Width 60
>>
FlateDecode decompress failed
The fact that the decompression fails does not matter – Adobe Reader will open the whole document (mmap it) into memory, including this "corrupted" object so the first stage shellcode will be able to find it and pass execution to it!
The advantage for the attacker is obvious: first, he can modify this object (what the exploit actually does) without having to modify the first stage shellcode. Additionally, this will make automatic analysis impossible for any tool that will use a JavaScript interpreter on the included JavaScript code (such as Wepawet) – the first phase shellcode will work only if the document is loaded in the memory. Sneaky, but that was not all!
The second stage shellcode does something interesting as well. It parses the document name from the command line arguments and opens the PDF document directly. The reason for this is that the PDF document carries two embedded binaries! The first binary (SUCHOST.EXE, b0eeca383a7477ee689ec807b775ebbb) contains a PoisonIvy client which tries to connect to the host cecon.flower-show.org which was down when I analyzed the document. Luckily, this binary has a bit better (but still not good, some major AV vendors missing it!) detection on VT (here). This binary is embedded in the PDF document – we can see it at offset 0x0e65c:
$ hexdump -C -v ../Requset.pdf |less
00000000 25 50 44 46 2d 31 2e 36 0d 25 e2 e3 cf d3 0d 0a |%PDF-1.6.%......|
00000010 32 34 20 30 20 6f 62 6a 0d 3c 3c 2f 4c 69 6e 65 |24 0 obj.<</Line|
00000020 61 72 69 7a 65 64 20 31 2f 4c 20 39 34 37 32 33 |arized 1/L 94723|
00000030 32 2f 4f 20 32 36 2f 45 20 31 37 38 31 2f 4e 20 |2/O 26/E 1781/N |
...
0000e650 b4 b4 b3 88 8f a0 a0 c0 ca c3 88 8f c8 df 00 00 |................|
0000e660 84 00 00 00 87 00 00 00 7a 7a 00 00 c5 00 00 00 |........zz......|
0000e670 00 00 00 00 c5 00 00 00 00 84 00 00 8b 9a 31 8c |..............1.|
The binary is XORed with value of 0x85 so the first two highlighted bytes are actually MZ, which is where the executable starts.
The second binary (temp.exe, 980e40cacbc9f898bc08cb453fa2d6bb) was even more surprising. This binary drops a benign PDF document on the machine, called baby.pdf. This PDF document is then opened with Adobe Reader – it just shows a table and, according to the metadata in the document, has been built from an Excel document. This was done by the attackers to make the victim believe as if nothing happened, because the original exploit will crash Adobe Reader and this might make the victim suspicious about what happened.
Additionally, the PDF document contains everything it needs to fully exploit the victim's machine – it does not have to download anything off the net.
Lessons learned
Not only was this a very interesting example of a malicious PDF document carrying a sophisticated "war head", but it also showed the length attackers are willing to go to in order to make their malware as hard to detect as possible, not only for the AV vendors, but also for victims.
Since this exploit has not been patched yet, I would like to urge you all to, at least, disable JavaScript in your Adobe Reader applications. We are getting more reports about PDF documents exploiting this vulnerability, and it certainly appears that the attackers are willing to customize them to get as many victims to open them as possible. Also keep in mind that such malicious PDF documents can go to a great length when used in targeted attacks – the fake PDF that gets opened can easily fool any user into thinking it was just a mistakenly sent document.
If we are to judge the new year by sophistication the attackers started using, it does not look too good.
--
Bojan
INFIGO IS


Comments
http://extraexploit.blogspot.com/search/label/CVE-2009-4324
Anthony Lai
Jan 5th 2010
1 decade ago
Patrick W. Barnes
Jan 5th 2010
1 decade ago