
Analysis of a Defective Phishing PDF
A reader submitted a suspicious PDF file. TLDR: it's a defective phishing PDF.
Taking a look with pdfid.py, I see nothing special, but it contains stream objects:
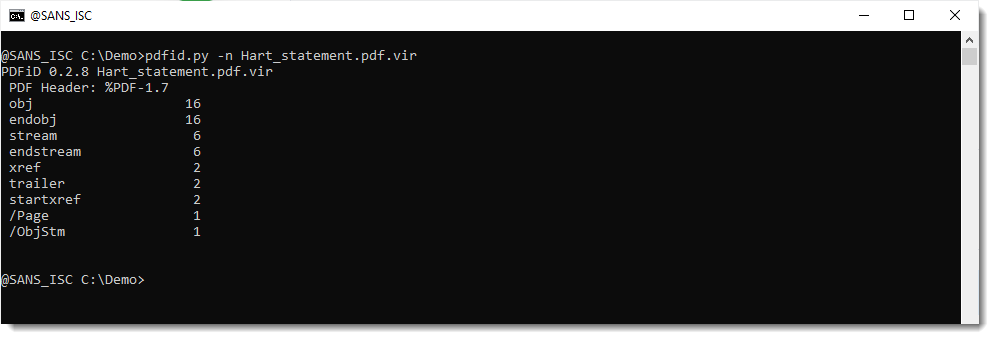
With the recent PDF/ActiveMime polyglots in mind, I also use option -e to get some extra information:
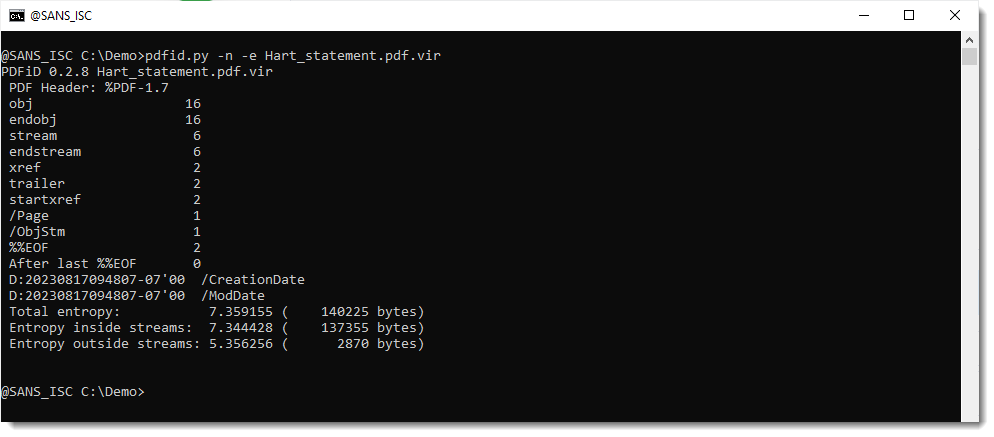
This looks normal: the file is mostly composed of data inside streams, and the entropy of data inside streams is high (compressed), and outside streams is low. Plus, there's very little data outside streams.
Notice that the datetimes indicate that this file was created August 18th (mind that this can be spoofed, but that this date is likely reliable since the file was first submitted to VT on August 22nd).
As the file contains stream objects (/ObjStm, these are objects that contain other objects inside their compressed stream), it's best to generate statistics for this PDF file using pdf-parser.py using option -a and -O:
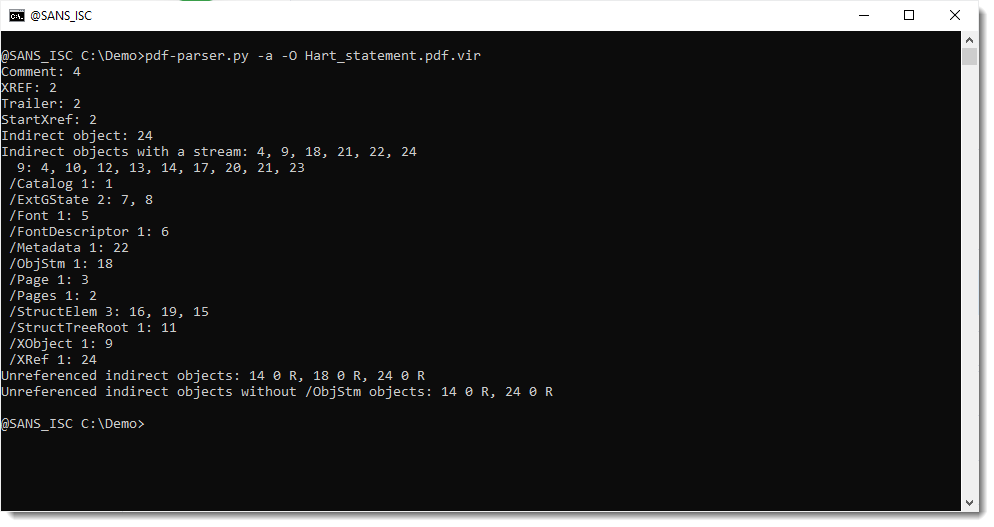
So this file contains no keywords that are typical for a phishing PDF (like /URI).
It does contain unreferenced objects, like 18 and 24, but that's normal (they are, respectively, /ObjStm and /XRef objects).
But object 14 could be something different:
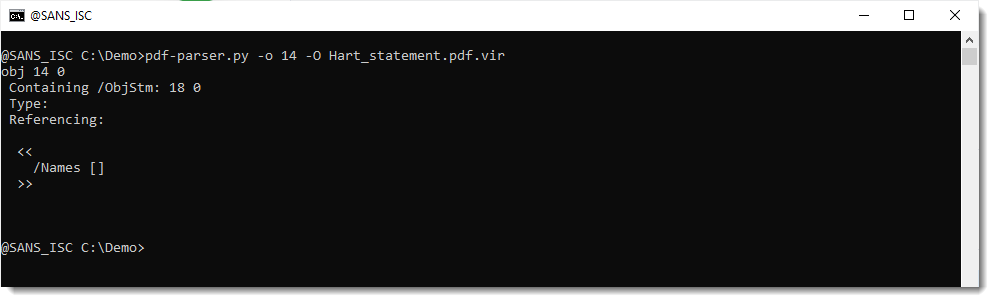
It's a typeless object, without stream, and just a dictonary with a key /Names that is an empty list. This could be an indication of defectiveness (something missing), or it could be an artifact of the PDF library used to create this document.
Let's take a look at object 9 (/XObject), this is likely an image:
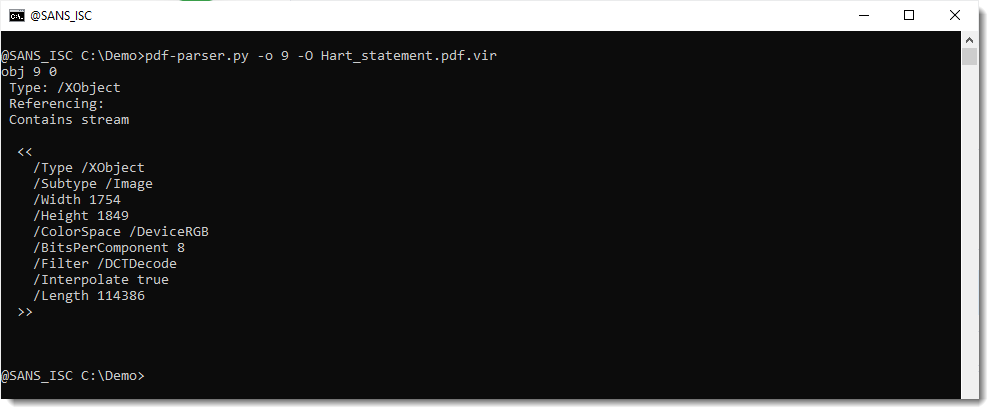
It is indeed a JPEG image (DCTDecode).
Let's dump this to disk to view it:
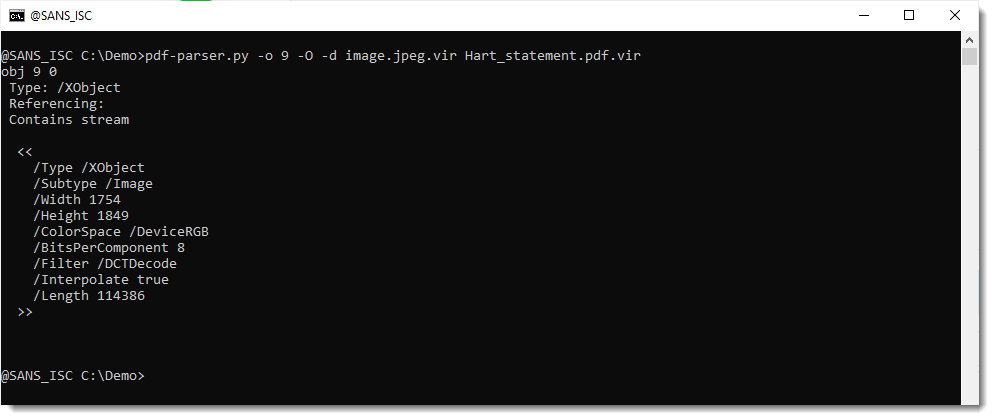
Before I open the file (inside a VM) to view the picture, I check with my jpegdump.py tool to verify that this is indeed a JPEG file:
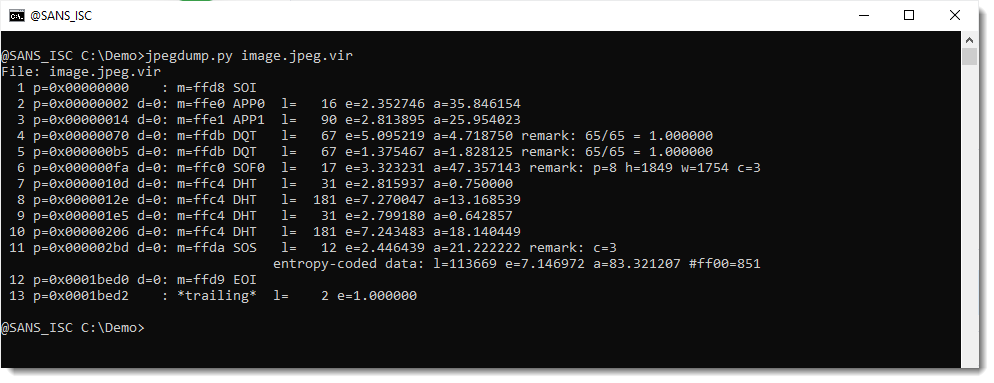
It looks indeed like a valid JPEG file. Except for the 2 bytes at the end:

That's a CR & NL character, and is an artifact of the extraction with pdf-parser: pdf-parser does not take the /Lenght value into account, and just extracts everything up to the endstream keyword. The /Length value is 114386 and the extracted file is 114388 in size.
I can finally take a view at the image:

And that is indeed a typical phishing image.
I do open the PDF inside a VM to see if there is no clickable object that my tools missed, but there is none: this is a defective phishing PDF (the link is missing).
It requires far more work if you need to be absolutely sure that there is no malicious content in a PDF file, like I showed years ago in this diary entry series: "It is a resume".
I'm not going to repeat this for this document, I feel confident that this is a defective phishing PDF.
Last thing I did, was to take a look for indications of the recently reported PDF/ActiveMime polyglots:

No indicators.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com


Comments