Steganography Challenge: My Solution
When I tried to solve "Steganography Challenge" with the same method as I used in "Steganography Analysis With pngdump.py: Bitstreams", I couldn't recover the text message.
So I looked into the source code of the encoding function EncodeNRGBA, and noticed this:

To encode each of the pixels, there are 2 nested for loops: "for x" and "for y". This means that first the column is processed (y).
While a raw bitmap is one line after the other (and not one column after the other). Thus we need to transpose the raw bitmap (rows and columns need to be swapped):

And as 8-bit RGB encoding is used for pixels, each pixel is encoded with 3 bytes, that need to be transposed correctly:

This transposition can be done with my tool translate.py and the necessary Python function. I wrote this one to do the transposition:
def Transpose(data, size, width, height):
result = []
for x in range(width):
for y in range(height):
i = y * width + x
result.append(data[i*size:(i + 1)*size])
return b''.join(result)
So let's decode this.
First we need the dimensions of the image:
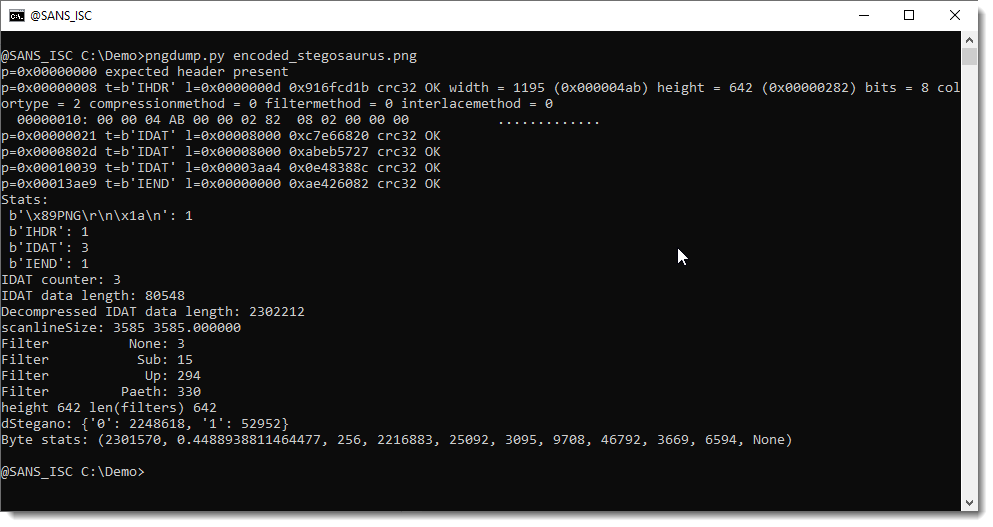
1195 pixels wide and 642 pixels high.
With this information, I can do the transposition with translate.py (3 is the number of bytes per pixel): Transpose(data, 3, 1195, 642)
Then I use the following command to decode the size of the message. It's the same command as I used in diary entry "Steganography Analysis With pngdump.py: Bitstreams", except that this time there's an extra step (translate) to do the transposition:
pngdump.py -R -d encoded_stegosaurus.png | translate.py -f -s transpose.py "lambda data: Transpose(data, 3, 1195, 642)" | cut-bytes.py 0:32l | format-bytes.py -d -f "bitstream=f:B,b:0,j:>" | format-bytes.py
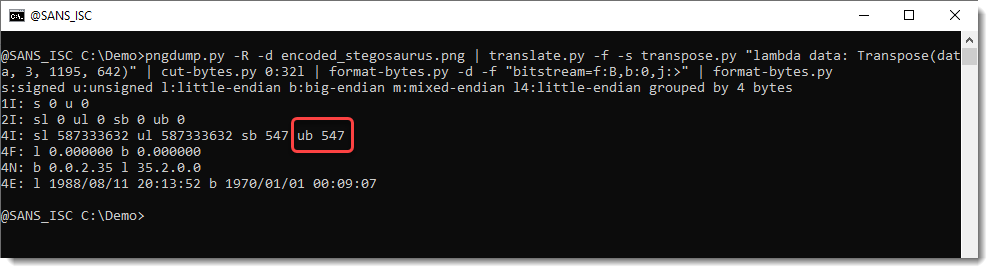
The message is 547 bytes long. Let's decode this:
pngdump.py -R -d encoded_stegosaurus.png | translate.py -f -s transpose.py "lambda data: Transpose(data, 3, 1195, 642)" | cut-bytes.py 32:4376l | format-bytes.py -d -f "bitstream=f:B,b:0,j:>"
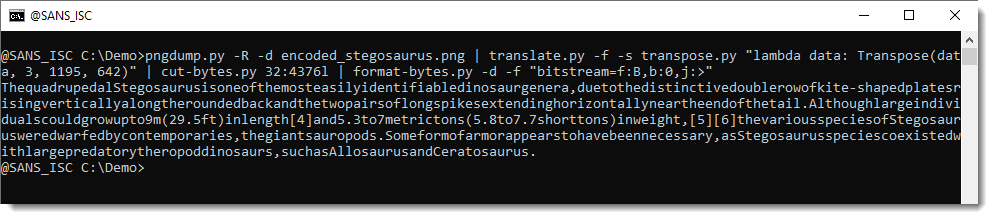
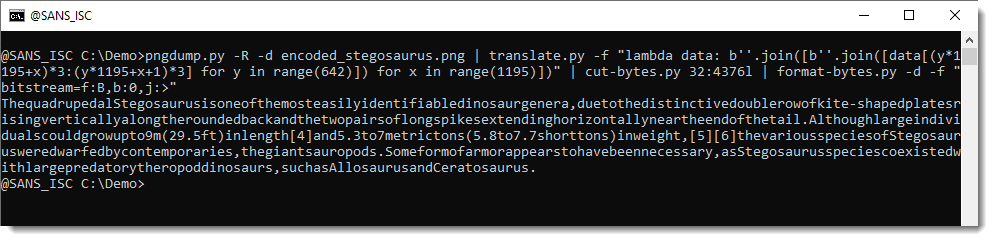
We were able to extract the text message (a partial copy from the Wikipedia article on Stegosaurus).
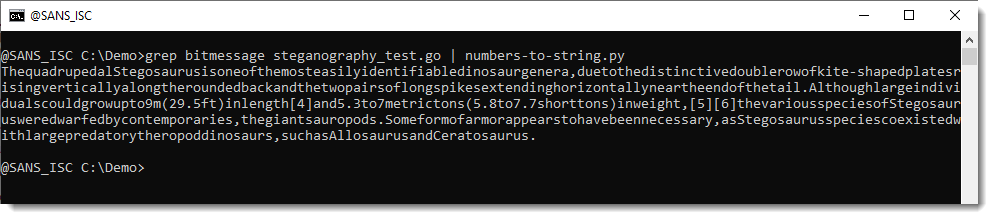
But what surprised me is the lack of space characters ... I though that this could hardly be due to an error in the decoding, so I took a look at the test encoder source code. Line 19 contains the message encoded as decimal bytes, and I noticed that there are no values equal to 32 (that's the space character). Decoding this line with numbers-to-string.py does indeed reveal that there are no space characters in the source code:
The solution to this challenge is identical to the one described in diary entry "Steganography Analysis With pngdump.py: Bitstreams", with one important difference: we need to transpose lines and columns.
Finally, if you would want to write this command as a one-liner without a file containing the source code for the Transpose Python function, you can to this with nested list comprehensions, but it's less readable:
pngdump.py -R -d encoded_stegosaurus.png | translate.py -f "lambda data: b''.join([b''.join([data[(y*1195+x)*3:(y*1195+x+1)*3] for y in range(642)]) for x in range(1195)])" | cut-bytes.py 32:4376l | format-bytes.py -d -f "bitstream=f:B,b:0,j:>"
Didier Stevens
Senior handler
blog.DidierStevens.com


Comments