Analyzing Office Documents Embedded Inside PPT (PowerPoint) Files
I was asked how to analyze Office Documents that are embedded inside PPT files. PPT is the "standard" binary format for PowerPoint, it's an olefile. You can analyze it with oledump.py:

All embedded content is found inside stream "PowerPoint Document". For VBA, I already wrote a blog post a couple years ago: "Analyzing PowerPoint Maldocs with oledump Plugin plugin_ppt".
The analysis process for embedded files is quite similar. We use plugin plugin_ppt:
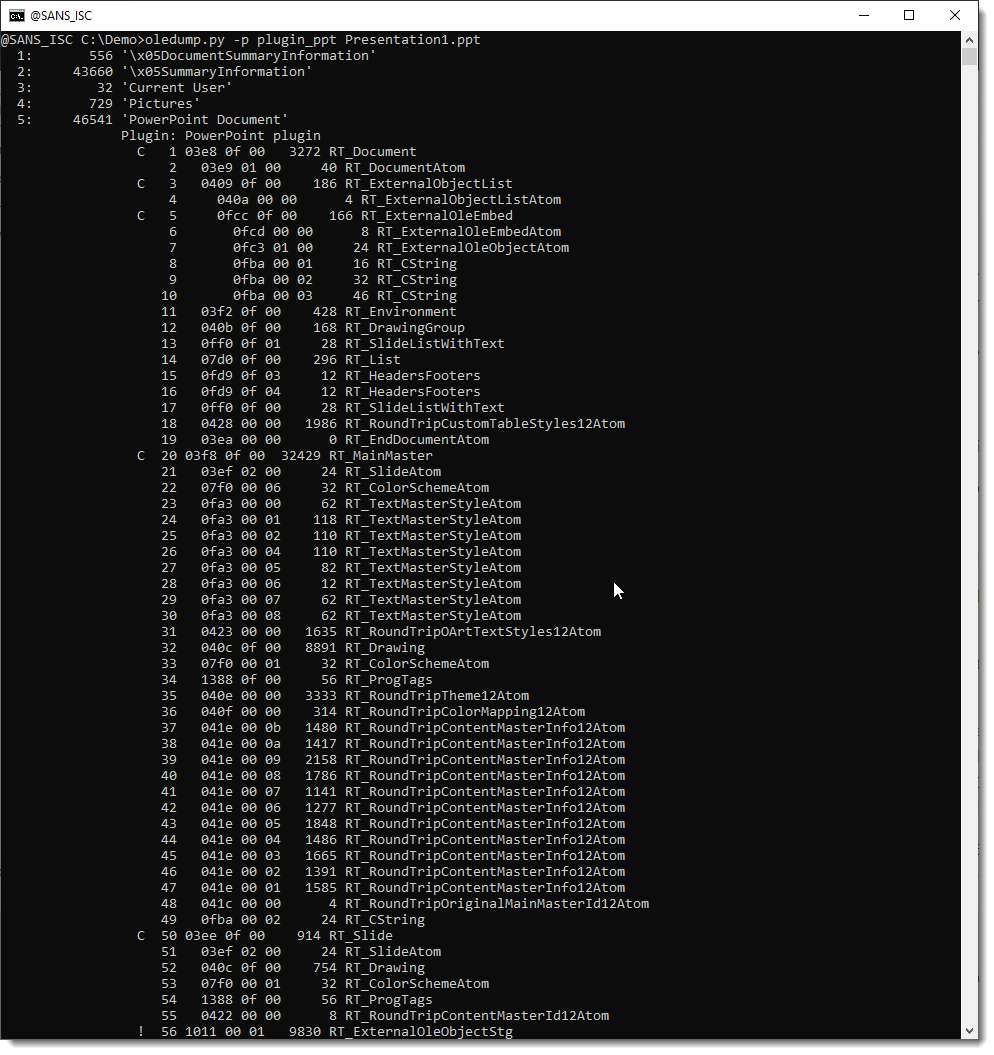
A PowerPoint Document stream is a list of records. Plugin plugin_ppt parses these records.
Record 56 is marked with an exclamation mark: !. That tells us that this record contains embedded content.
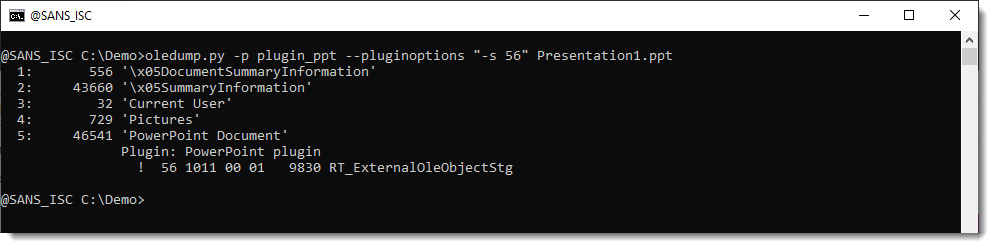
We can select this record for further analysis. Since the parsing is done by the plugin, we need to instruct the plugin to select this record with the appropriate option (-s). Options for plugins are passed via oledump's option pluginoptions. Like this:
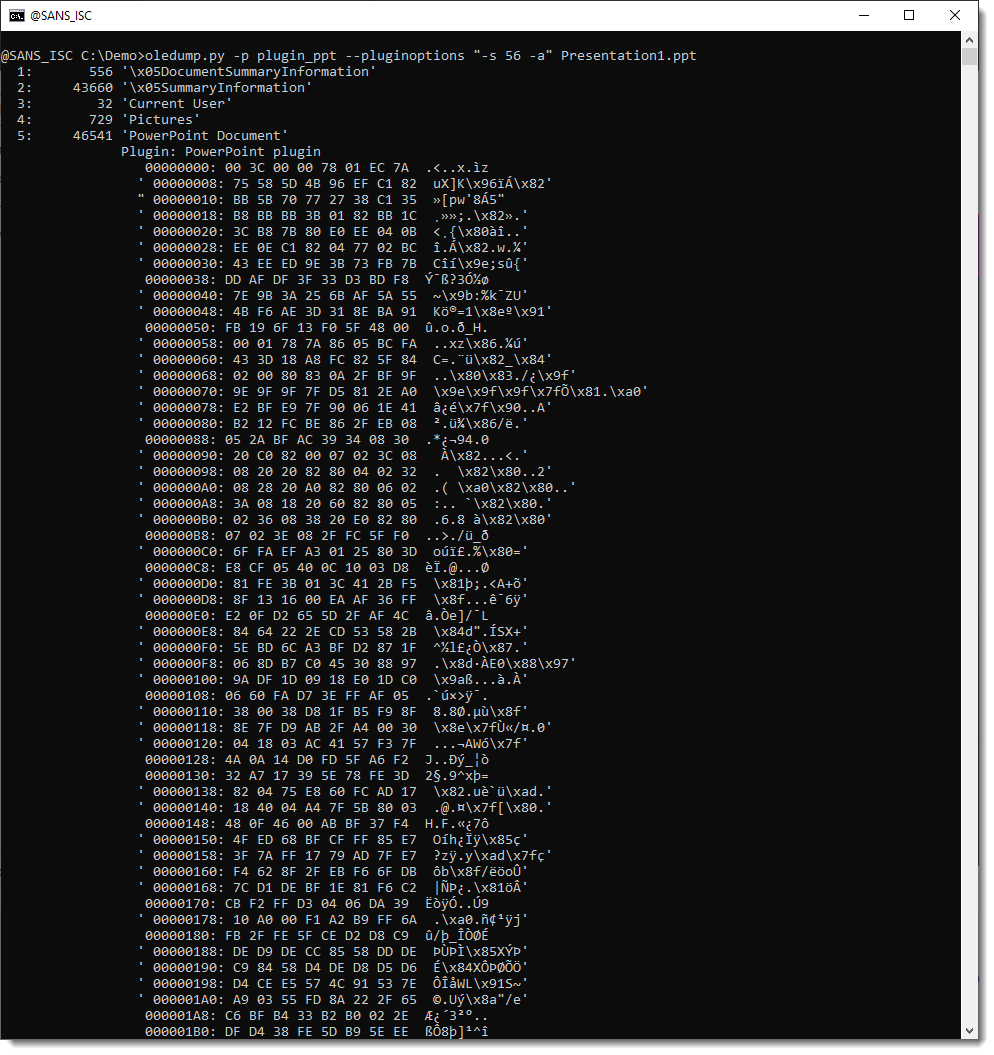
We can do an HEX/ASCII dump with options -a, to take a peek at the content:
This content is zlib compressed. To decompress it an dump it, we use option -e. But we also need to use oledump's option -q (quiet) so that oledump does not produce any output, and that the sole output comes from the plugin. Like this:
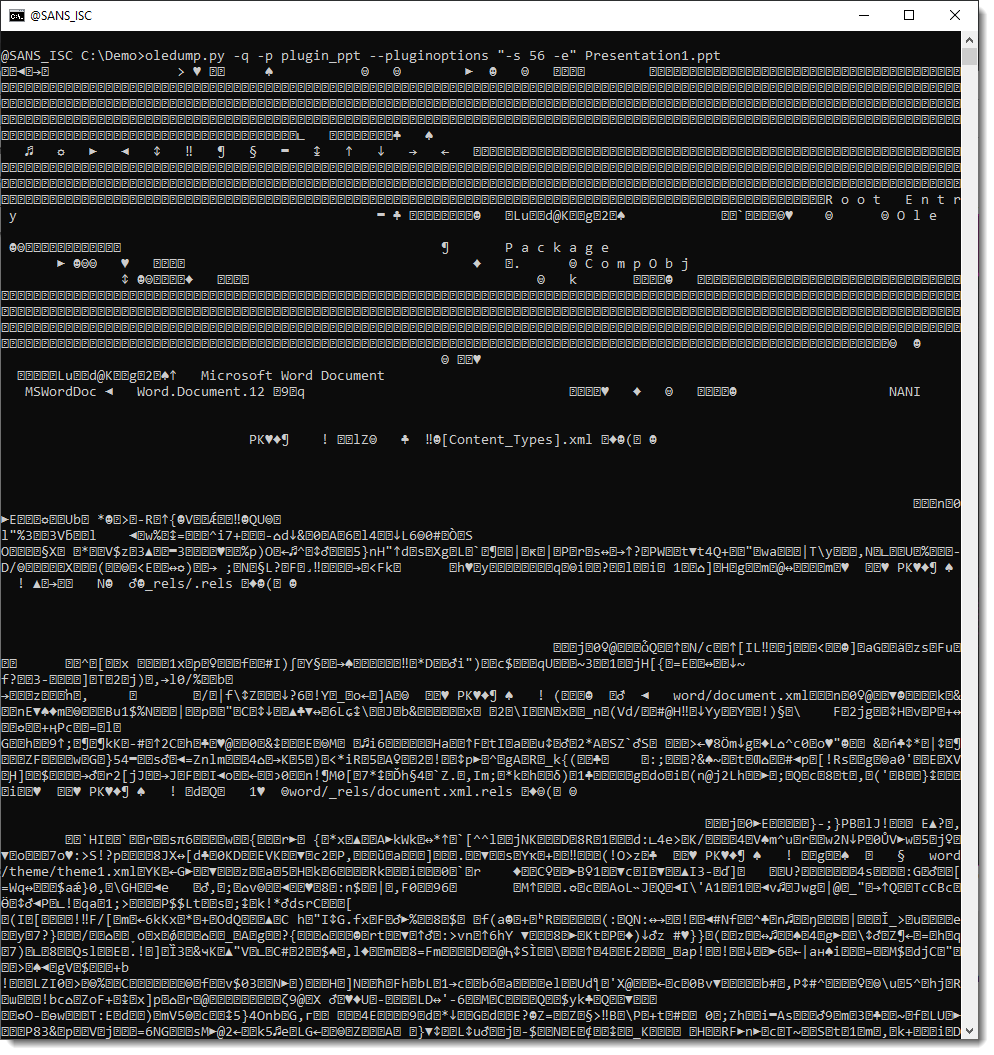
We can pass this to file-magic.py to identify the decompressed content:

It is a "Composite Document File V2 Document", or ..., an ole file. So we can just parse this with another instance of oledump.py:
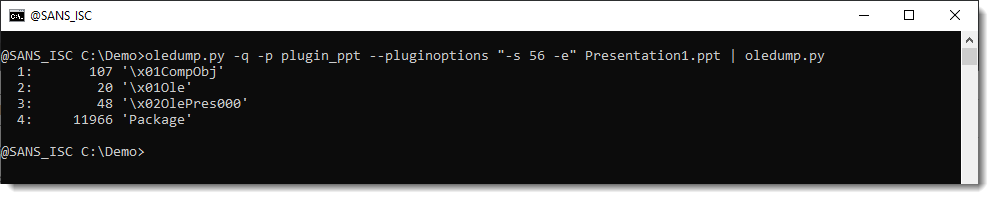
The embedded file is contained inside the Package stream, the other streams contain metadata. That can be parsed with plugin plugin_olestreams:
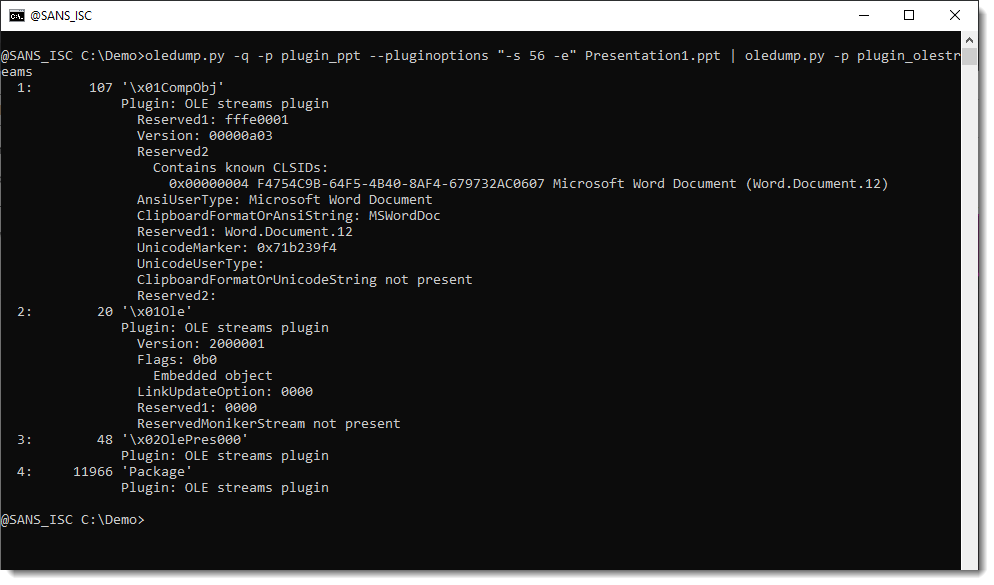
The metadata tells us that the embedded file is a Word document.
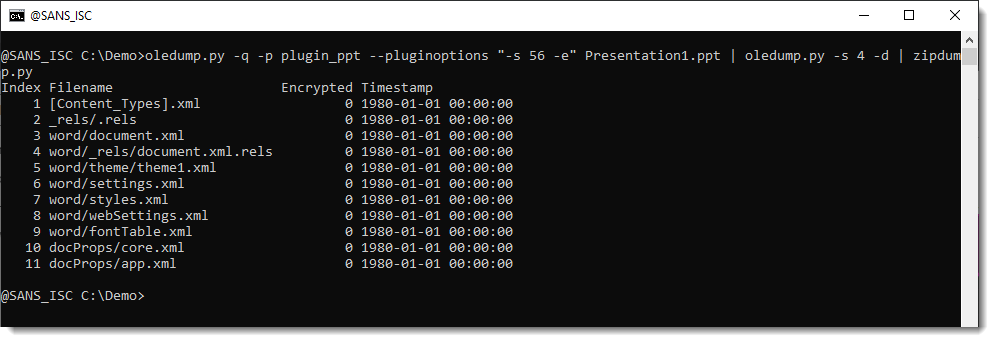
Let's check:

Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com


Comments