Extracting 'HTTP CONNECT' Requests with Python
Seeing abnormal Suricata alerts isn’t too unusual in my home environment. In many cases it may be a TLD being resolved that at one point in time was very suspicious. With the increased legitimate adoption of some of these domains, these alerts have been less useful, although still interesting to investigate. I ran into a few of these alerts one night and when diving deeper there was an unusual amount, frequency, and source of the alerts.
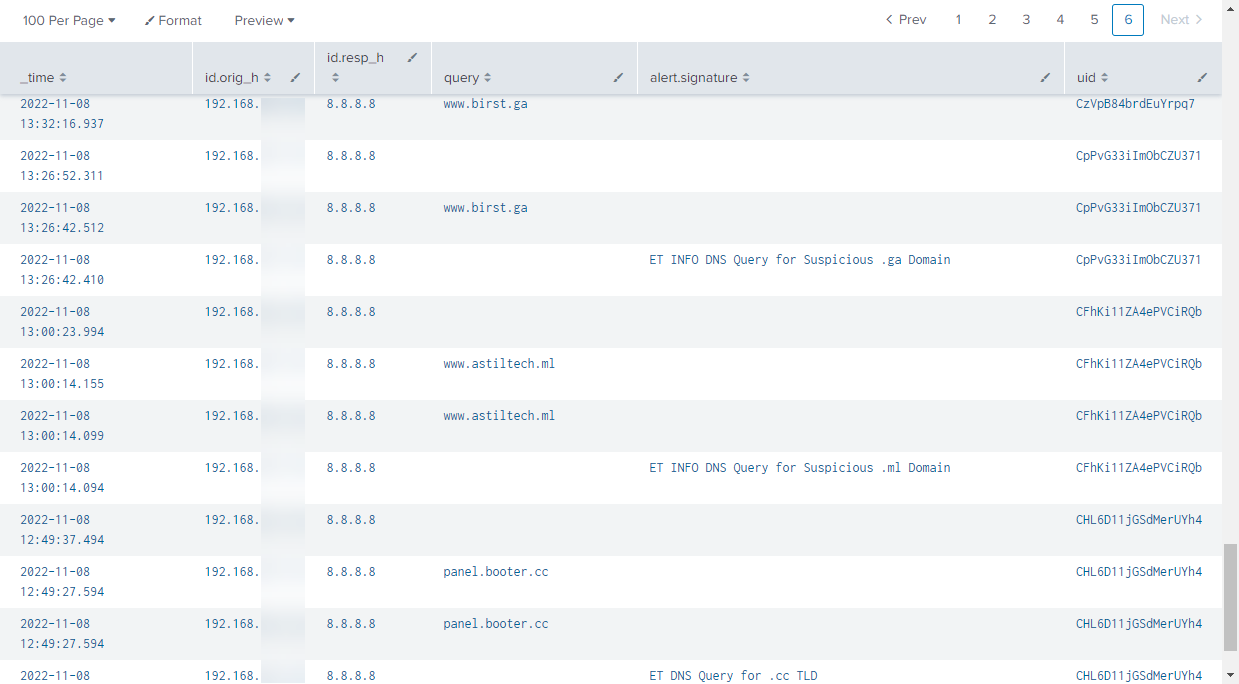
Figure 1: Suspicious Suricata Alerts
The source indicated that the alerts were coming from a dedicated internal firewall on my network, which is used to gather additional data on Honeypot attack traffic. The source ended up being my DShield honeypot. These alerts have come up before, but the amount was very unusual. Since this traffic wasn’t being shown in my standard web honeypot logs, I decided to look at local PCAP captures.
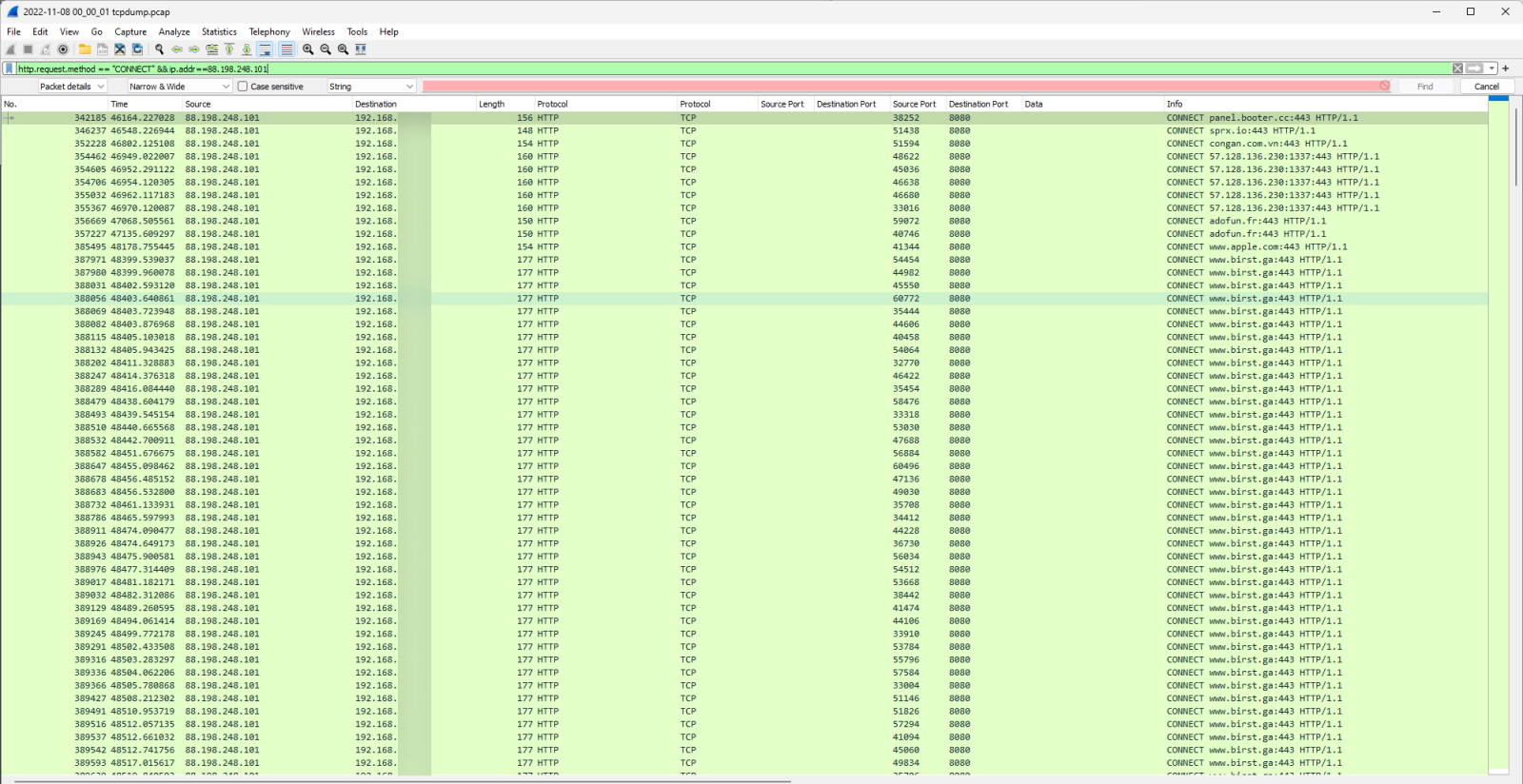
Figure 2: PCAP HTTP CONNECT Requests from Wireshark
The data showed a variety of HTTP CONNECT requests that were arriving at the honeypot. HTTP CONNECT requests are often used with proxy servers to open a connection to a desired destination [1]. Looking into any one of the streams didn’t give much additional information since the CONNECT requests were directing to encrypted HTTP connections.
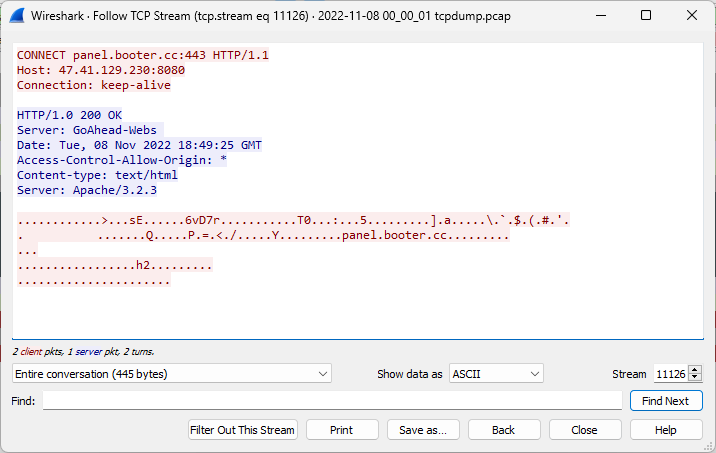
Figure 3: TCP Stream of HTTP CONNECT Request from Wireshark
There were Zeek and other data available to summarize this information but decided to pull together a python script to process the PCAP files. The goal was to understand the scale of these requests and the change over time.
from scapy.all import *
from scapy.layers import http
from collections import Counter
import os
import time
def print_header(header_text):
print("\n\n")
print("{:>70s}".format("//////////////////////////////////////////////"))
print("{:>50s} {:>10s}".format(header_text, "Count"))
print("{:>70s}".format("//////////////////////////////////////////////"))
directory = os.getcwd()
csv_export = open("http_connect_info.csv","a")
csv_export.write("Epoch Time,Date,Source IP,Destination Port,HTTP CONNECT Path,HTTP CONNECT Host\n")
src_ips = []
dst_ports = []
connect_paths = []
connect_hosts = []
for filename in os.scandir(directory):
if ".pcap" in filename.path:
print("Processing file: " + filename.path)
for pkt in PcapReader(filename.path):
if pkt.haslayer(http.HTTPRequest):
if pkt.Method.decode() == "CONNECT":
src_ip = ""
dst_port = ""
connect_path = ""
connect_host = ""
if pkt[IP].src is not None:
src = pkt[IP].src
if pkt[IP].dport is not None:
dst_port = pkt[IP].dport
if pkt[IP].Path is not None:
connect_path = pkt[IP].Path.decode()
if pkt[IP].Host is not None:
connect_host = pkt[IP].Host.decode()
print(str(pkt.time) + ", " + time.strftime('%Y-%m-%d %H:%M:%S %z',time.localtime(float(pkt.time)))
+ ", " + src + ", " + str(dst_port) + ", " + connect_path + ", " + connect_host)
csv_export.write(str(pkt.time) + "," + time.strftime('%Y-%m-%d %H:%M:%S %z',time.localtime(float(pkt.time)))
+ "," + src + "," + str(dst_port) + "," + connect_path + "," + connect_host + "\n")
src_ips.append(src)
dst_ports.append(dst_port)
connect_paths.append(connect_path)
connect_hosts.append(connect_host)
src_ip_counts = Counter(src_ips)
dst_port_counts = Counter(dst_ports)
connect_paths = Counter(connect_paths)
connect_hosts = Counter(connect_hosts)
print("\n\n")
print_header("Source IP")
for each_item in src_ip_counts.most_common():
print("{:>50s} {:10d}".format(each_item[0], each_item[1]))
print_header("Destination Port")
for each_item in dst_port_counts.most_common():
print("{:>50d} {:10d}".format(each_item[0], each_item[1]))
print_header("HTTP Connect Path")
for each_item in connect_paths.most_common():
print("{:>50s} {:10d}".format(each_item[0], each_item[1]))
print_header("HTTP Connect Host")
for each_item in connect_hosts.most_common():
print("{:>50s} {:10d}".format(each_item[0], each_item[1]))
This script reviews all the *.pcap files in the current directory, prints out a basic summary of the HTTP CONNECT requests and also saves the data to a CSV file.
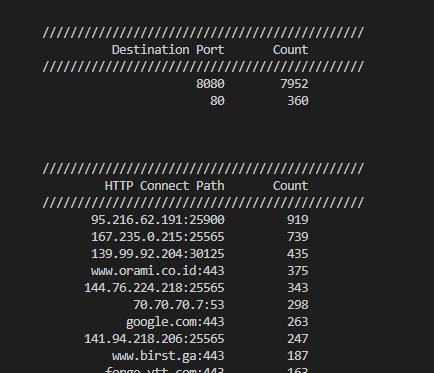
Figure 4: Destination Port and HTTP CONNECT Request Path Counts
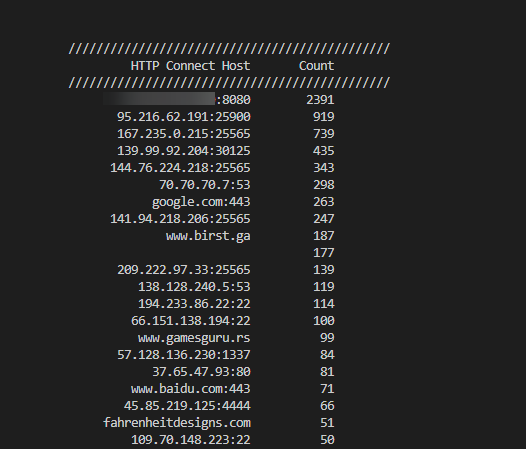
Figure 5: HTTP CONNECT Request Host Counts
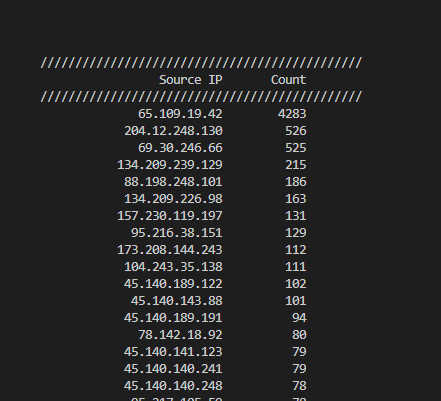
Figure 6: HTTP CONNECT Request Source IPs
For a small snapshot of a day or two, it was completed processing within an hour or so. I was curious how this compared to historic data. I ran the same script against 6 months of PCAPS. This took over a day to process. Using a tool such as Zeek [1] would likely be quicker to get this information. The http.log file of Zeek would have the information and a utility like zeek-cut [2] could help get the raw requests.
An item that stood out when looking at the data was that recent HTTP CONNECT requests had greatly increased this month and especially in the last week.
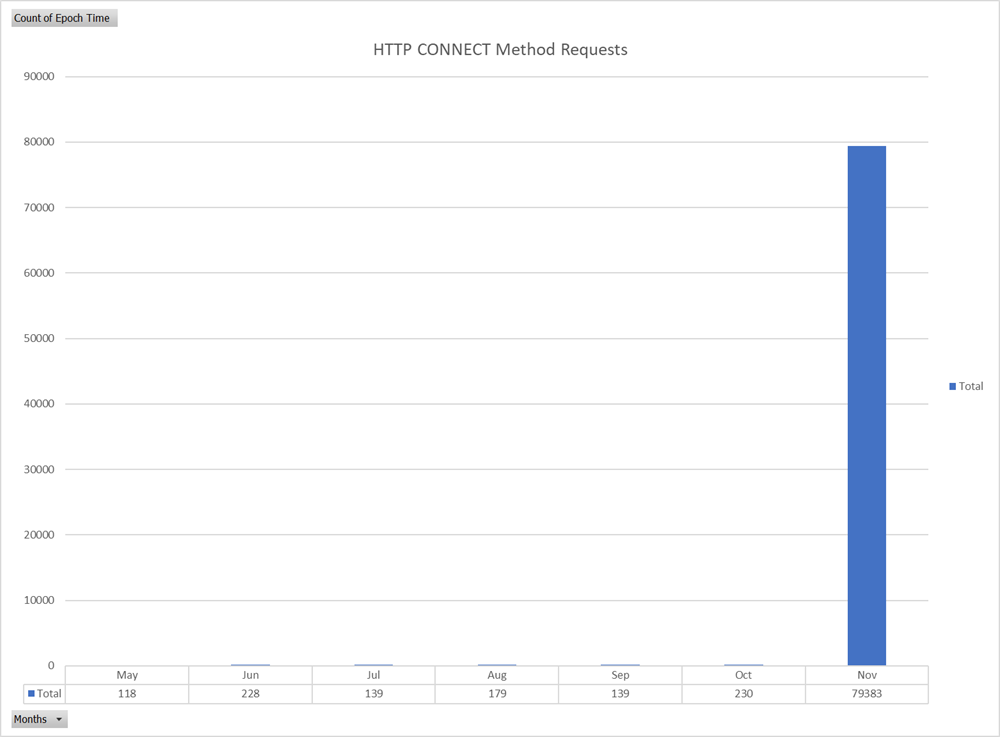
Figure 7: Graph of HTTP CONNECT Method Requests by Month Since May 2022
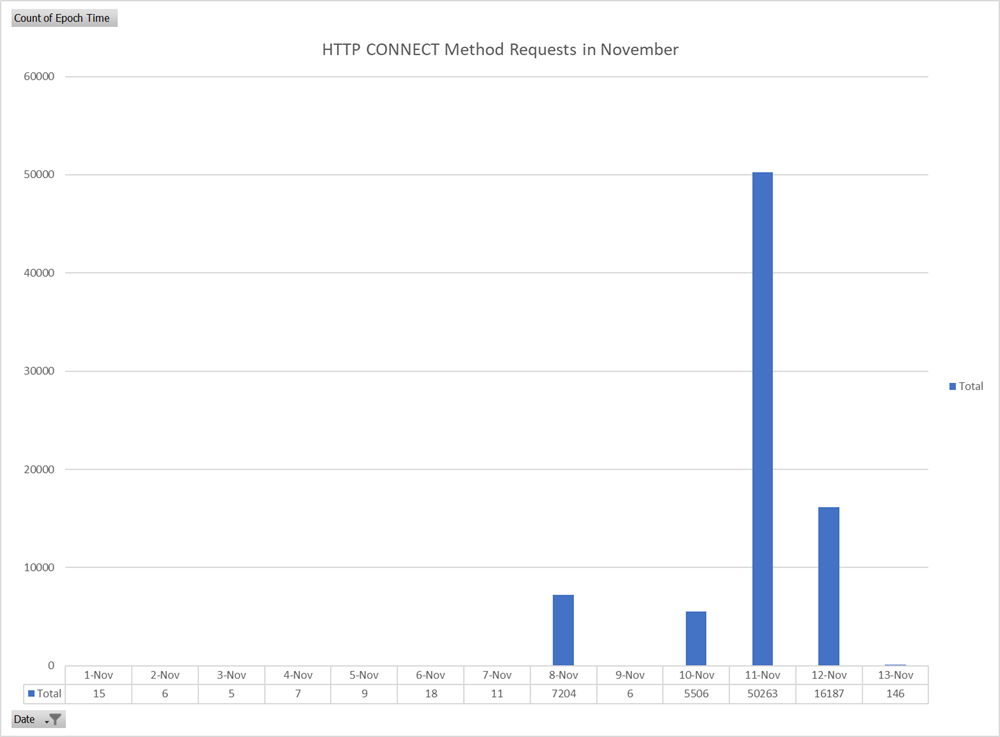
Figure 8: Graph of HTTP CONNECT Method Requests by Day in November 2022
Top 10 HTTP CONNECT Path Ports
| HTTP CONNECT Path Port | Count |
|---|---|
| 443 | 64681 |
| 27115 | 7876 |
| 25565 | 1871 |
| 25900 | 919 |
| 30125 | 529 |
| 22 | 483 |
| 30120 | 468 |
| 3389 | 467 |
| 80 | 446 |
| 53 | 417 |
Top 10 HTTP CONNECT Source IP Addresses
| HTTP CONNECT Source IP | Count |
|---|---|
| 142[.]202[.]242[.]113 | 16164 |
| 69[.]30[.]246[.]66 | 11354 |
| 204[.]12[.]248[.]130 | 10902 |
| 65[.]109[.]19[.]42 | 9740 |
| 209[.]222[.]97[.]249 | 6747 |
| 69[.]30[.]243[.]18 | 3729 |
| 172[.]93[.]100[.]135 | 3557 |
| 142[.]202[.]243[.]109 | 2667 |
| 104[.]251[.]122[.]239 | 1759 |
| 167[.]99[.]176[.]180 | 1537 |
Top 10 HTTP CONNECT Paths
| HTTP CONNECT Path | Count |
|---|---|
| 28sex[.]com:443 | 16357 |
| 109[.]237[.]111[.]71:27115 | 7876 |
| beo555[.]co:443 | 4620 |
| beo333[.]com:443 | 4442 |
| h5[.]xhlax[.]com:443 | 3764 |
| www[.]korims[.]com:443 | 3119 |
| www[.]serruriervaud[.]ch:443 | 1872 |
| share[.]nuox[.]top:443 | 1730 |
| 18[.]140[.]35[.]119:443 | 1464 |
| keokeo[.]top:443 | 1144 |
Python can be a great way to programmatically extract data from a PCAP and use that data for other purposes, such as data enrichment or summarization. It was an easy way, if other tools were unavailable, to easily summarize HTTP requests. For larger pools of data, using other tools such as Zeek can also be extremely useful.
The HTTP CONNECT requests may have been an attempt to relay traffic through the honeypot and hide the original source of the request. It is also possible that the traffic may have been funneled through multiple proxy endpoints to make identification of the source difficult to identify. Allowing HTTP CONNECT on internet facing resources can potentially expose internal network resources or assist in the forwarding of malicious traffic. A majority of the HTTP CONNECT requests were directed at port TCP 8080 (99.5%) with the remaining aimed at TCP 80.
[1] https://www.rfc-editor.org/rfc/rfc9110.html#name-connect
[2] https://docs.zeek.org/en/master/about.html
[3] https://docs.zeek.org/en/v3.0.14/examples/logs/index.html
--
Jesse La Grew
Handler


Comments
Only a small correction: src_ip=pkt[IP].src.
Spiros
Nov 15th 2022
3 years ago