When Good Patches go Bad - a DNS tale that didn't start out that way
I recently had a client call me, the issue that day was "the VPN is down". What it turned out to be was that RADIUS would not start, because some other application had port UDP/1645 (one of the common RADIUS ports) open. Since he didn't have RADIUS, no VPN connections could authenticate.
So, standard drill, we ran "netstat -naob", to list out which application was using which port, and found that DNS was using that port. Wait, What, DNS? DNS doesn't use that port, does it? When asked, what port does DNS use, what you'll most often hear is "UDP/53", or more correctly, "TCP/53 and UDP/53", but that is only half the story. When a DNS server makes a request (in recursive lookups for example), it opens an ephemeral port, some port above 1024 as the source, with UDP/53 or TCP/53 as it's destination.
So, ok, that all makes sense, but what was DNS doing, opening that port when the service starts during the server boot-up sequence? The answer to that is, Microsoft saw the act of opening the outbound ports as a performance issue that they should fix. Starting with DNS Server service security update 953230 (MS08-037), DNS now reserves 2500 random UDP ports for outbound communication
What, you say? Random, as in picked randomly, before other services start, without regard for what else is installed on the server Yup. But surely they reserve the UDP ports commonly seen by other apps, or at least UDP ports used by native Microsoft Windows Server services? Nope. The only port that is reserved by default is UDP/3343 - ms-cluster-net - which is as the name implies, used by communications between MS Cluster members.
So, what to do? Luckily, there's a way to reserve the ports used by other applications, so that DNS won't snap them up before other services start. First, go to the DNS server in question, make sure that everything is running, and get the task number that DNS.EXE is currently using:
C: >tasklist | find "dns.exe"
dns.exe 1816 Console 0 19,652 K
In this case, the task number is 1816. Then, get all the open UDP ports that *aren't* using 1816
C: >netstat -nao -p UDP | find /v " 1816"
Active Connections
Proto Local Address Foreign Address State PID
UDP 0.0.0.0:42 *:* 860
UDP 0.0.0.0:135 *:* 816
UDP 0.0.0.0:161 *:* 3416
UDP 0.0.0.0:445 *:* 4
UDP 0.0.0.0:500 *:* 512
UDP 0.0.0.0:1050 *:* 1832
UDP 0.0.0.0:1099 *:* 2536
You may want to edit this list, some of them might be ephemeral ports. If there's any question about what task is using which port, you can hunt them down by running:
taskilst | find "tasknumber"
or, run "netstat -naob" - - i find this a bit less useful since the task information is spread across multiple lines.
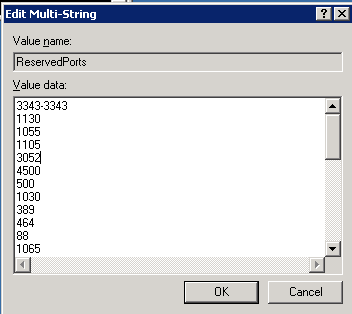
Finally, with a list of ports we want to reserve, we go to the registry with REGEDT32, to HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesTcpipParametersReservedPorts
.png)
Update the value for this entry with the UDP ports that you've decided to reserve:
Finally, back to the original issue, RADIUS now starts and my client's VPN is running. We also added a second RADIUS back in - - the second RADIUS server had been built when the VPN went in, but had since mysteriously disappeared. But that's a whole 'nother story ...
If you've had a patch (recent or way back in the day) "go bad on you", we'd like to hear about it, please use our comment form. Patches with silly design decisions, patches that crashed your server or workstation, patches that were later pulled or re-issued, they're all good stories - - after they're fixed that is !
A final note:
Opening outbound ports in advance is indeed a good way to get a performance boost on DNS, if you have, say 30,000 active users hitting 2 or 3 servers. But since most organizations don't have that user count, a more practical approach to reserving ports would be to simply wait for queries, and not release the outbound ports as outbound requests leave the server, until the count is at the desired number. Maybe reserving ports should wait until the server has been up for some period of time, say 20 minutes, to give all the other system services a chance to start and get their required resources. Another really good thing to do would be to make the port reservation activity an OPTION in the DNS admin GUI, not the DEFAULT.
In Server 2008, the ephemeral port range for reservations is 49152-65535, so the impact of this issue is much less. You can duplicate this behaviour in Server 2003 by adjusting the MaxUserPort registry entry (see the MS documents below for details on this)
References:
http://support.microsoft.com/kb/956188
http://support.microsoft.com/kb/812873
http://support.microsoft.com/kb/832017
===============
Rob VandenBrink
Metafore
Putting all of Your Eggs in One Basket - or How NOT to do Layoffs
The recent story about Jason Cornish, a disgruntled employee of pharmaceutical company Shionogi is getting a lot of attention this week. In a nutshell, he resigned after a dispute with management, and was kept on as a consultant for a few months after.
The story then goes that he logged into the network remotely (ie - VPN'd in using his legitimate credentials), then logged into a "secret vSphere console" (I'd call "foul" on that one - there would be no reason to have a "secret" console - my guess is he used the actual corporate vCenter console or used a direct client against ESX, which you can download from any ESX server, so he had rights there as well) then proceeded to delete a large part of the company infrastructure (88 servers in the story I read). The company was offline for "a number of days", and Jason is now facing charges.
This diary isn't about the particulars of this case, it's much more of a common occurrence than you might think. We'll talk a bit about what to do, a bit about what NOT to do, and most important, we'd love to hear your insights and experiences in this area.
First of all, my perspective ...
Separation of duties is super-critical. Unless you are a very small shop, your network people shouldn't have your windows domain admin account, and vice versa. In a small company this can be a real challenge - if you've only got 1 or two people in IT, we generally see a single password that all the admins have. Separation of duties is simple to do in vmWare vSphere - for instance, you can limit the ability to create or delete servers to the few people who should have that right. If you have web administrators or database administrators who need access to the power button, you can give them that and ONLY that.
Hardening your infrastructure is also important. Everything from Active Directory to vSphere to Linux have a "press the enter key 12 times" default install. Unfortunately, in almost all cases, this leaves you with a single default administrator account on every system, with full access to everything. Hardening hosts will generally work hand-in-hand with separation of duties, in most cases the default / overall administator credentials are left either unused or deleted. In the case of network or virtual infrastructure, you'll often back-end it to an enterprise directory, often Active Directory via LDAP (or preferably LDAPs), Kerberos or RADIUS. This can often be a big help if you have audits integrated into your change control process (to verify who made a particular change, or to track down who made an unauthorized change)
HR processes need to be integrated with IT. This isn't news to most IT folks. They need to know when people are hired to arrange for credentials and hardware. But much more important, IT needs to be involved in termination. They need to collect the gear, revoke passwords and the like, in many cases during the exit interview. When an IT admin is layed off, fired or otherwise terminated, it's often a multi-person effort to change all the passwords - domain admin credentials, passwords for local hosts, virtual infrastructure admins, and the myriad of network devices (routers, switches, firewalls, load balancers, etc). If you've integrated your authentication back to a common directory, this can be a very quick process (delete or disable one account). In this case, a known disgruntled employee was kept on after termination as a consultant with admin rights. You would think that if HR as aware of this, or any corporate manager knew of it for that matter, that common sense would kick in, and the red flags would be going up well before they got to the point of recovering a decimated infrastructure. Yea, I know the proverb about common sense not being so common, but still ....
Backups are important. It's ironic that I'm spelling this out in the diary adjacent to the one on the fallout from the 2003 power outage where we talk about how far we've come in BCP (Business Continuity Planing), but it's worth repeating. Being out for "a number of days" is silly in a virtual environment - it should be *easy* to recover, that's one of the reasons people virtualize. It's very possible, and very often recommended, that all servers in a virtual infrastructure (Hyper-V, XEN, vmWare, KVM whatever), be imaged off to disk each day - the ability and APIs for this are available in all of them. The images are then spooled off to tape, which is a much slower process. This would normally mean that if a server is compromised or in this case deleted, you should be able to recover that server in a matter of minutes (as fast as you can spin the disks). This assumes that you have someone left in the organization that knows how to do this (see the next section).
Don't give away the keys. Organizations need to maintain a core level of technical competancy. This may seem like an odd thing for me to say (I'm a consultant), but you need actual employees of the company who "own" the passwords, and have the skills to do backups, restores, user creation, all those core business IT tasks that are on the checklist of each and every compliance regulation. In a small shop, it's common for IT to give consultants their actual administrative credentials, but it's much more common these days to get named accounts so that activity can be tracked, these accounts are often time limited either for a single day or the duration of the engagement.
I'd very much like to see a discussion on this - what processes do you have in place, or what processes have you seen in other organizations to deal with IT "root level" users - how are they brought on board, how are they controlled day-to-day, and how are things handled as they leave the organization? I'm positive that I've missed things, please help fill in the blanks !
If I'm off-base on any of my recommendations or comments above, by all means let me know that too !
===============
Rob VandenBrink
Metafore


Comments