Apple Patches Everything: December 2025 Edition
Never release on a Friday. Unless you are Apple :) Apple released updates for all of its operating systems today. These updates were expected for this week, a second release candidate being released on Monday made me think that they may wait a week to push the final product. This is a "step update" for the operating systems, including various small feature updates. Across Apple's operating systems, the update fixes a total of 48 vulnerabilities. Two of the vulnerabilities are already actively exploited in targeted attacks.
Both exploited vulnerabilities affect WebKit and, with that, are exploitable by visiting a malicious webpage. WebKit is used by various software that displays HTML pages, not just Safari. The first vulnerability, CVE-2025-14174, is a use-after-free vulnerability. The second issue, CVE-2025-43529, allows for memory corruption. Apple does not state it in their brief advisories, but both issues can likely be used to execute arbitrary code. It is not clear if the vulnerabilities will also lead to sandbox escape.
In addition to the patches for the operating system, Apple also fixed its video processing tool "Compressor". The patched vulnerability allows for remote code execution by an attacker on the local network. Compressor is an add-on software that is not included in the OS install. I doubt many users aside from video editors have it installed.
| iOS 26.2 and iPadOS 26.2 | iOS 18.7.3 and iPadOS 18.7.3 | macOS Tahoe 26.2 | macOS Sequoia 15.7.3 | macOS Sonoma 14.8.3 | tvOS 26.2 | watchOS 26.2 | visionOS 26.2 |
|---|---|---|---|---|---|---|---|
| CVE-2024-8906: A download's origin may be incorrectly associated. Affects Safari Downloads |
|||||||
| x | |||||||
| CVE-2025-14174: Processing maliciously crafted web content may lead to memory corruption. Apple is aware of a report that this issue may have been exploited in an extremely sophisticated attack against specific targeted individuals on versions of iOS before iOS 26. CVE-2025-43529 was also issued in response to this report.. Affects WebKit |
|||||||
| x | x | x | x | x | x | ||
| CVE-2025-43320: An app may be able to bypass launch constraint protections and execute malicious code with elevated privileges. Affects AppleMobileFileIntegrity |
|||||||
| x | |||||||
| CVE-2025-43410: An attacker with physical access may be able to view deleted notes. Affects Notes |
|||||||
| x | |||||||
| CVE-2025-43416: An app may be able to access protected user data. Affects sudo |
|||||||
| x | x | x | |||||
| CVE-2025-43428: Photos in the Hidden Photos Album may be viewed without authentication. Affects Photos |
|||||||
| x | x | x | |||||
| CVE-2025-43463: An app may be able to access sensitive user data. Affects StorageKit |
|||||||
| x | x | ||||||
| CVE-2025-43475: An app may be able to access user-sensitive data. Affects MediaExperience |
|||||||
| x | |||||||
| CVE-2025-43482: An app may be able to cause a denial-of-service. Affects Audio |
|||||||
| x | x | x | |||||
| CVE-2025-43501: Processing maliciously crafted web content may lead to an unexpected process crash. Affects WebKit |
|||||||
| x | x | x | x | ||||
| CVE-2025-43509: An app may be able to access sensitive user data. Affects Networking |
|||||||
| x | x | x | |||||
| CVE-2025-43511: Processing maliciously crafted web content may lead to an unexpected process crash. Affects WebKit Web Inspector |
|||||||
| x | x | x | x | ||||
| CVE-2025-43512: An app may be able to elevate privileges. Affects Kernel |
|||||||
| x | x | x | x | ||||
| CVE-2025-43513: An app may be able to read sensitive location information. Affects MDM Configuration Tools |
|||||||
| x | x | x | |||||
| CVE-2025-43514: An app may be able to access protected user data. Affects Siri |
|||||||
| x | |||||||
| CVE-2025-43516: A user with Voice Control enabled may be able to transcribe another user's activity. Affects Voice Control |
|||||||
| x | x | x | |||||
| CVE-2025-43517: An app may be able to access protected user data. Affects Call History |
|||||||
| x | x | x | |||||
| CVE-2025-43518: An app may be able to inappropriately access files through the spellcheck API. Affects Foundation |
|||||||
| x | x | x | x | x | |||
| CVE-2025-43519: An app may be able to access sensitive user data. Affects AppleMobileFileIntegrity |
|||||||
| x | x | x | |||||
| CVE-2025-43521: An app may be able to access sensitive user data. Affects AppleMobileFileIntegrity |
|||||||
| x | x | ||||||
| CVE-2025-43522: An app may be able to access user-sensitive data. Affects AppleMobileFileIntegrity |
|||||||
| x | x | ||||||
| CVE-2025-43523: An app may be able to access sensitive user data. Affects AppleMobileFileIntegrity |
|||||||
| x | |||||||
| CVE-2025-43526: On a Mac with Lockdown Mode enabled, web content opened via a file URL may be able to use Web APIs that should be restricted. Affects Safari |
|||||||
| x | |||||||
| CVE-2025-43527: An app may be able to gain root privileges. Affects StorageKit |
|||||||
| x | x | ||||||
| CVE-2025-43529: Processing maliciously crafted web content may lead to arbitrary code execution. Apple is aware of a report that this issue may have been exploited in an extremely sophisticated attack against specific targeted individuals on versions of iOS before iOS 26. CVE-2025-14174 was also issued in response to this report.. Affects WebKit |
|||||||
| x | x | x | x | x | x | ||
| CVE-2025-43530: An app may be able to access sensitive user data. Affects Settings |
|||||||
| x | x | x | x | ||||
| CVE-2025-43531: Processing maliciously crafted web content may lead to an unexpected process crash. Affects WebKit |
|||||||
| x | x | x | x | x | x | ||
| CVE-2025-43532: Processing malicious data may lead to unexpected app termination. Affects Foundation |
|||||||
| x | x | x | x | x | x | x | x |
| CVE-2025-43533: A malicious HID device may cause an unexpected process crash. Affects Multi-Touch |
|||||||
| x | x | x | x | x | |||
| CVE-2025-43535: Processing maliciously crafted web content may lead to an unexpected process crash. Affects WebKit |
|||||||
| x | x | x | x | ||||
| CVE-2025-43536: Processing maliciously crafted web content may lead to an unexpected process crash. Affects WebKit |
|||||||
| x | x | x | |||||
| CVE-2025-43538: An app may be able to access sensitive user data. Affects Screen Time |
|||||||
| x | x | x | x | x | x | ||
| CVE-2025-43539: Processing a file may lead to memory corruption. Affects AppleJPEG |
|||||||
| x | x | x | x | x | x | x | x |
| CVE-2025-43541: Processing maliciously crafted web content may lead to an unexpected Safari crash. Affects WebKit |
|||||||
| x | x | x | x | ||||
| CVE-2025-43542: Password fields may be unintentionally revealed when remotely controlling a device over FaceTime. Affects FaceTime |
|||||||
| x | x | x | x | x | |||
| CVE-2025-46276: An app may be able to access sensitive user data. Affects Messages |
|||||||
| x | x | x | x | x | x | x | |
| CVE-2025-46277: An app may be able to access a user's Safari history. Affects Screen Time |
|||||||
| x | x | x | |||||
| CVE-2025-46278: An app may be able to access protected user data. Affects Game Center |
|||||||
| x | |||||||
| CVE-2025-46279: An app may be able to identify what other apps a user has installed. Affects Icons |
|||||||
| x | x | x | x | x | x | ||
| CVE-2025-46281: An app may be able to break out of its sandbox. Affects File Bookmark |
|||||||
| x | |||||||
| CVE-2025-46282: An app may be able to access sensitive user data. Affects WebKit |
|||||||
| x | |||||||
| CVE-2025-46283: An app may be able to access sensitive user data. Affects CoreServices |
|||||||
| x | |||||||
| CVE-2025-46285: An app may be able to gain root privileges. Affects Kernel |
|||||||
| x | x | x | x | x | x | x | x |
| CVE-2025-46287: An attacker may be able to spoof their FaceTime caller ID. Affects Calling Framework |
|||||||
| x | x | x | x | x | x | x | |
| CVE-2025-46288: An app may be able to access sensitive payment tokens. Affects App Store |
|||||||
| x | x | x | x | ||||
| CVE-2025-46289: An app may be able to access protected user data. Affects AppSandbox |
|||||||
| x | x | x | |||||
| CVE-2025-46291: An app may bypass Gatekeeper checks. Affects LaunchServices |
|||||||
| x | |||||||
| CVE-2025-46292: An app may be able to access user-sensitive data. Affects Telephony |
|||||||
| x | x | ||||||
--
Johannes B. Ullrich, Ph.D. , Dean of Research, SANS.edu
Twitter|
Abusing DLLs EntryPoint for the Fun
In the Microsoft Windows ecosystem, DLLs (Dynamic Load Libraries) are PE files like regular programs. One of the main differences is that they export functions that can be called by programs that load them. By example, to call RegOpenKeyExA(), the program must first load the ADVAPI32.dll. A PE files has a lot of headers (metadata) that contain useful information used by the loader to prepare the execution in memory. One of them is the EntryPoint, it contains the (relative virtual) address where the program will start to execute.

In case of a DLL, there is also an entry point called logically the DLLEntryPoint. The code located at this address will be executed when the library is (un)loaded. The function executed is called DllMain()[1] and expects three parameters:
BOOL WINAPI DllMain( _In_ HINSTANCE hinstDLL, _In_ DWORD fdwReason, _In_ LPVOID lpvReserved );
The second parmeter indicates why the DLL entry-point function is being called:
- DLL_PROCESS_DETACH (0)
- DLL_PROCESS_ATTACH (1)
- DLL_THREAD_ATTACH (2)
- DLL_THREAD_DETACH (3)
Note that this function is optional but it is usually implemented to prepare the environment used by the DLL like loading resources, creating variables, etc... Microsoft recommends also to avoid performing sensitive actions at that location.
Many maware are deployed as DLLs because it's more challenging to detect. The tool regsvr32.exe[2] is a classic attack vector because it helps to register a DLL in the system (such DLL will implement a DllRegisterServer() function). Another tool is rundll32.exe[3] that allows to call a function provided by a DLL:
C:\> rundll32.exe mydll.dll,myExportedFunction
When a suspicious DLL is being investigated, the first reflex of many Reverse Engineers is to look at the exported function(s) but don't pay attention to the entrypoint. They look at the export table:
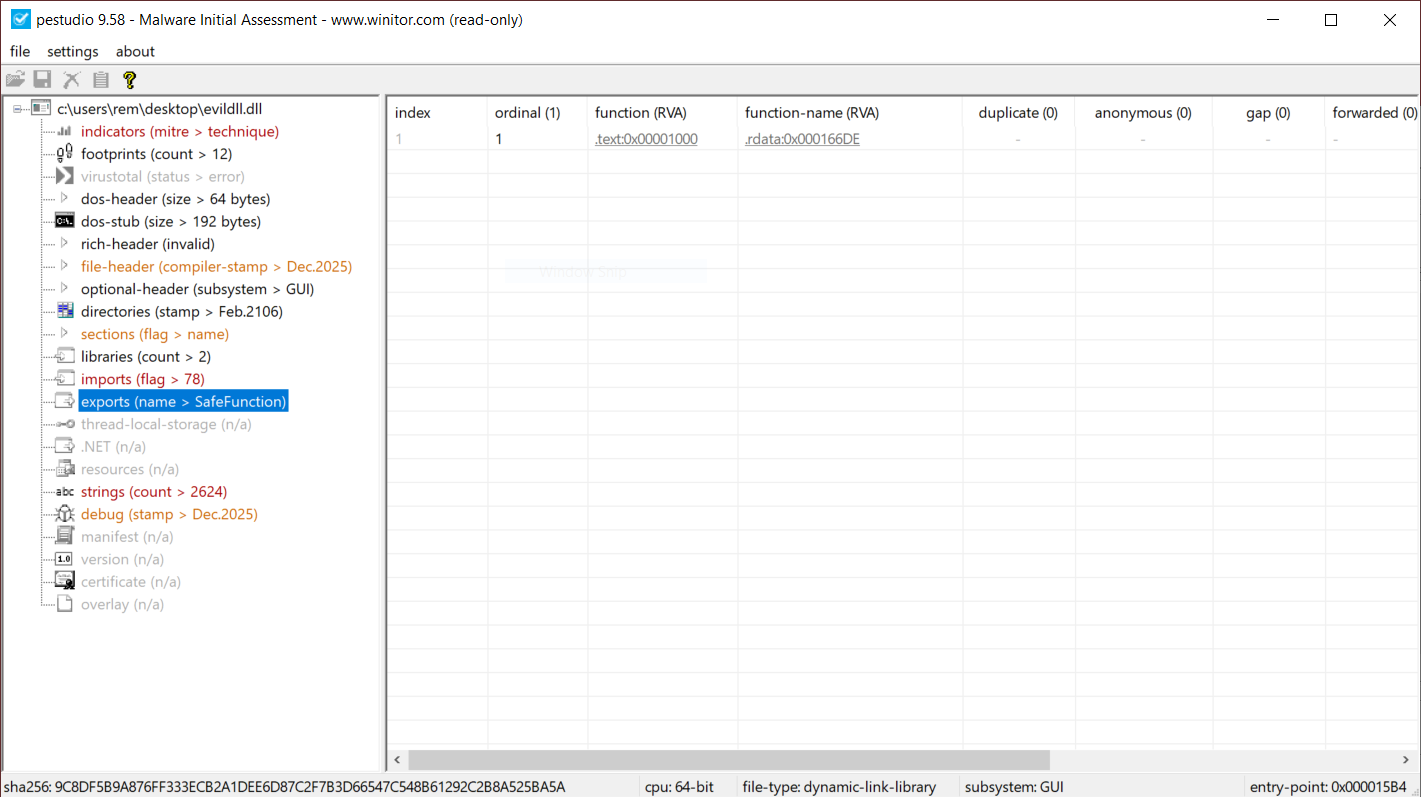
This DllMain() is a very nice place where threat actors could store malicious code that will probably remains below the radar if you don’t know that this EntryPoint exists. I wrote a proof-of-concept DLL that executes some code once loaded (it will just pop up a calc.exe). Here is the simple code:
// evildll.cpp
#include <windows.h>
#pragma comment(lib, "user32.lib")
extern "C" __declspec(dllexport) void SafeFunction() {
// Simple exported function
MessageBoxA(NULL, "SafeFunction() was called!", "evildll", MB_OK | MB_ICONINFORMATION);
}
BOOL APIENTRY DllMain(HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved) {
switch (ul_reason_for_call) {
case DLL_PROCESS_ATTACH:
{
// Optional: disable thread notifications to reduce overhead
DisableThreadLibraryCalls(hModule);
STARTUPINFOA si{};
PROCESS_INFORMATION pi{};
si.cb = sizeof(si);
char cmdLine[] = "calc.exe";
BOOL ok = CreateProcessA(NULL, cmdLine, NULL, NULL, FALSE, 0, NULL, NULL, &si, &pi);
if (ok) {
CloseHandle(pi.hThread);
CloseHandle(pi.hProcess);
} else {
// optional: GetLastError() handling/logging
}
break;
}
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
And now, a simple program used to load my DLL:
// loader.cpp
#include <windows.h>
#include <stdio.h>
typedef void (*SAFEFUNC)();
int main()
{
// Load the DLL
HMODULE hDll = LoadLibraryA("evildll.dll");
if (!hDll)
{
printf("LoadLibrary failed (error %lu)\n", GetLastError());
return 1;
}
printf("[+] DLL loaded successfully\n");
// Resolve the function
SAFEFUNC SafeFunction = (SAFEFUNC)GetProcAddress(hDll, "SafeFunction");
if (!SafeFunction)
{
printf("GetProcAddress failed (error %lu)\n", GetLastError());
FreeLibrary(hDll);
return 1;
}
printf("[+] SafeFunction() resolved\n");
// Call the function
SafeFunction();
// Unload DLL
FreeLibrary(hDll);
return 0;
}
Let's compile the DLL, the loader and execute it:
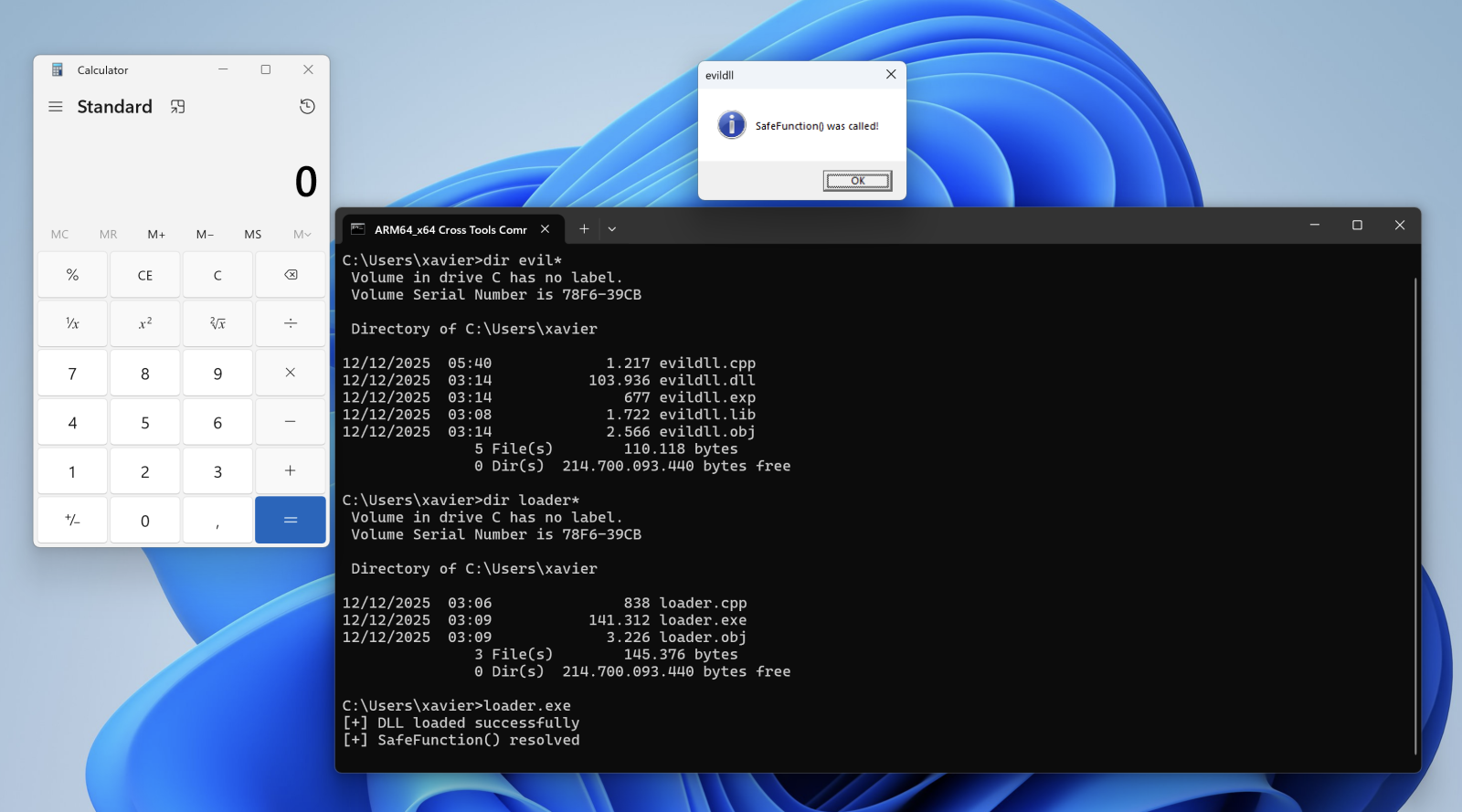
When the DLL is loaded with LoadLibraryA(), the calc.exe process is spawned automatically, even if no DLL function is invoked!
Conclusion: Always have a quick look at the DLL entry point!
[1] https://learn.microsoft.com/en-us/windows/win32/dlls/dllmain
[2] https://attack.mitre.org/techniques/T1218/010/
[3] https://attack.mitre.org/techniques/T1218/011/
Xavier Mertens (@xme)
Xameco
Senior ISC Handler - Freelance Cyber Security Consultant
PGP Key


Comments