Does it matter if iptables isn't running on my honeypot?
I've been working on comparing data from different DShield [1] honeypots to understand differences when the honeypots reside on different networks. One point of comparison is malware submitted to the honeypots. During a review of the summarized data, I noticed that one honeypot was an outlier in terms of malware captured.
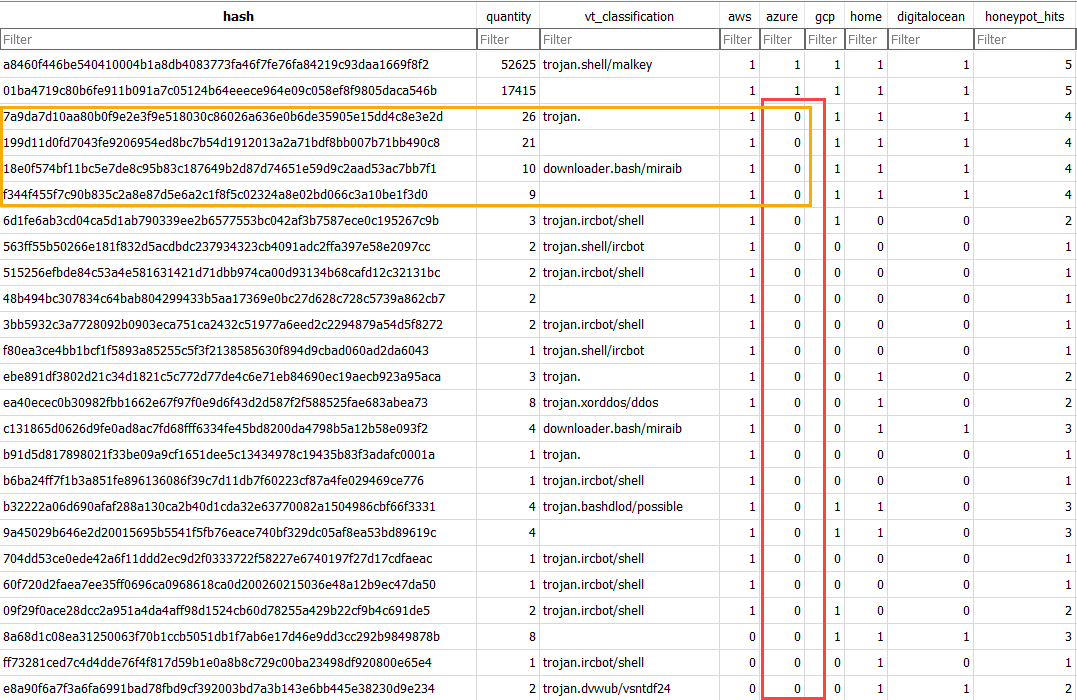
Figure 1: Highlighted differences for one honeypot and malware uploaded or downloaded to it.
A honeypot in Azure [2] had only seen two files:
- a8460f446be540410004b1a8db4083773fa46f7fe76fa84219c93daa1669f8f2 [3]
- 01ba4719c80b6fe911b091a7c05124b64eeece964e09c058ef8f9805daca546b [4]
In addition, there were four files seen for all the honeypots except for the Azure honeypot:
- 7a9da7d10aa80b0f9e2e3f9e518030c86026a636e0b6de35905e15dd4c8e3e2d [5]
- 199d11d0fd7043fe9206954ed8bc7b54d1912013a2a71bdf8bb007b71bb490c8 [6]
- 18e0f574bf11bc5e7de8c95b83c187649b2d87d74651e59d9c2aad53ac7bb7f1 [7]
- f344f455f7c90b835c2a8e87d5e6a2c1f8f5c02324a8e02bd066c3a10be1f3d0 [8]
Another unusual item was the reported network ports showing activity.
.png)
Figure 2: Highlighted ports for Azure honeypot, demonstrating gaps in port activity reported by other honeypots.
Looking into the logs, I noticed that the local firewall logs were not updated since January 2024. Outside of filtering traffic to the normal administrative SSH port (port 12222), the iptables firewall also provides NAT redirected ports to add surface area to the honeypot.

Figure 3: Highlighted ports only made available due to iptables NAT redirection rules (port 22, port 23, port 2323, port 80, port 8080, port 7547, port 5555, port 9000)
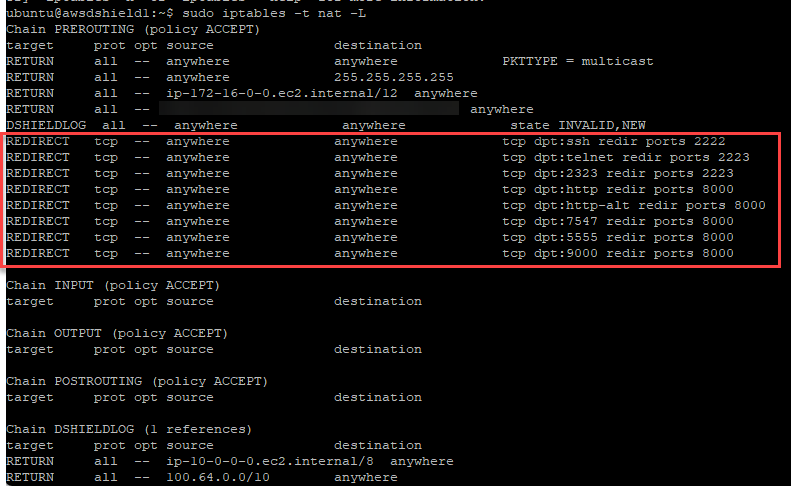
Figure 4: Example iptables rules for honeypot, highlighting NAT rules
This required setting up another honeypot to make sure similar data was being collected. Since I recalled having some issues setting up the Azure honeypot originally, I decided to use a different operating system. The honeypot was originally set up with Linux (ubuntu 20.04). After trying Linux (debian 11), I had issues with iptables being properly configured after a completed install as well. When using Linux (debian 12), the installation of the honeypot completed and iptables rules were configured correctly.
So, did the change in attack surface change the malware found on the new honeypot?
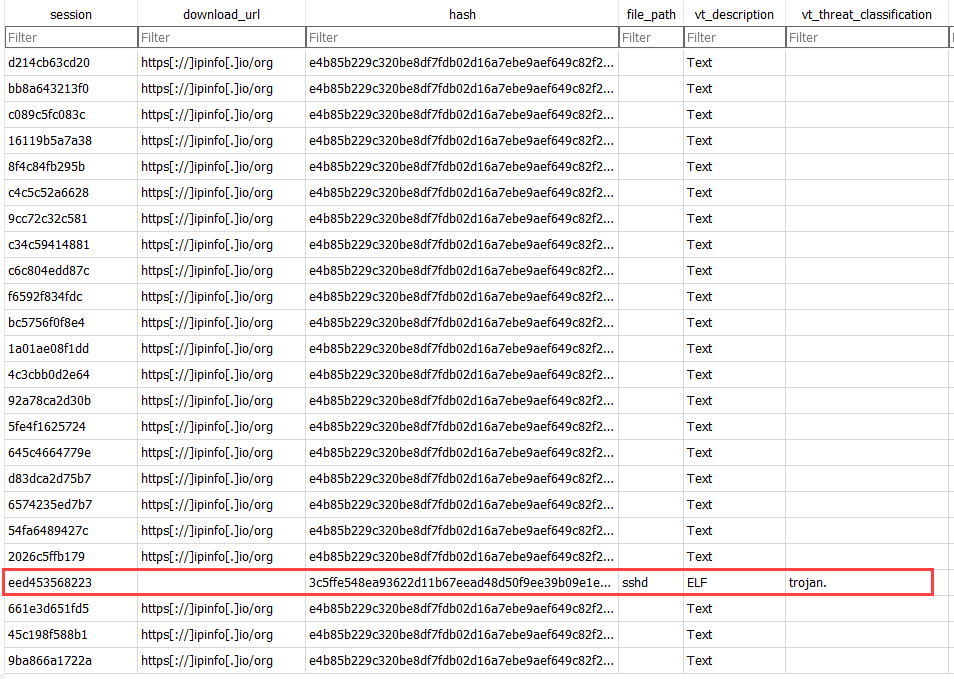
Figure 5: New malware highlighted that was submitted to an Azure honeypot with functioning iptables that contained proper NAT redirection rules.
It does appear that the change in ports did impact data received. It only took a few days of waiting. The firewall logs of the new Azure honeypot showed only activity fo TCP port 22 for the IP address registered for the cowrie [10] session, which without iptables would have not been available for attack.
honeypotuser@azurehp2:/logs$ zcat /var/log/dshield.log*.gz | grep "49.87.111.198" | awk '{print $18}'
DPT=22
DPT=22
DPT=22
DPT=22
DPT=22
Having iptables properly configured can help protect the administrative port, but will also impact data received. The changed attack surface in my case meant not seeing some attacks that may only be looking for SSH over TCP port 22. Having iptables functioning properly also means having firewall log data to analyze.
[1] https://isc.sans.edu/honeypot.html
[2] https://azure.microsoft.com/
[3] https://www.virustotal.com/gui/file/a8460f446be540410004b1a8db4083773fa46f7fe76fa84219c93daa1669f8f2
[4] https://www.virustotal.com/gui/file/01ba4719c80b6fe911b091a7c05124b64eeece964e09c058ef8f9805daca546b
[5] https://www.virustotal.com/gui/file/7a9da7d10aa80b0f9e2e3f9e518030c86026a636e0b6de35905e15dd4c8e3e2d
[6] https://www.virustotal.com/gui/file/199d11d0fd7043fe9206954ed8bc7b54d1912013a2a71bdf8bb007b71bb490c8
[7] https://www.virustotal.com/gui/file/18e0f574bf11bc5e7de8c95b83c187649b2d87d74651e59d9c2aad53ac7bb7f1
[8] https://www.virustotal.com/gui/file/f344f455f7c90b835c2a8e87d5e6a2c1f8f5c02324a8e02bd066c3a10be1f3d0
[9] https://www.virustotal.com/gui/file/3c5ffe548ea93622d11b67eead48d50f9ee39b09e1e813747883d1528569ffd1
[10] https://github.com/cowrie/cowrie
--
Jesse La Grew
Handler

Comments