Continuous Monitoring for Random Strings
Greeting ISC readers. Mark Baggett here. Back in August I released a tool called freq.py that will help to identify random characters in just about any string by looking at the frequency of occurrence of character pairs. It can be used to successfully identify randomly generated host names in DNS packets, SSL certificates and other text based logs. I would encourage you to read the original blog for full details on the tool. You can find the original post here:
For our click averse reader, here is the TLDR version.
- You build frequency tables based on normal artifacts in your environment. For more accurate measurements you should create a separate frequency table for each type of artifact. For example, you might create a separate frequency table for:
- DNS Host names that are normally seen for your environment
- Names of files on your file server
- Host names inside of SSL certificates
- URLs for a specific Web Application
- * Insert any string you want to measure here *
- You measure strings observed in your environment against your "normal" frequency tables and any strings with character frequency pairs that are different that your frequency tables will have low scores.
freq.py and freq.exe are command line tools designed to measure a single string. It wasn’t designed for high speed continuous monitoring. If you tried to use freq.py to measure everything coming out of your SecurityOnion sensor, integrate it into Bro logs or do any enterprise monitoring it would be overwhelmed by the volume of requests and fail miserably. Justin Henderson contacted me last week and pointed out the problem. To resolve this issue I am releasing freq_server.py.
Freq_server.py is a multithreaded web based API that will allow you to quickly query your frequency tables. The server isn’t intended to replace freq.py. Instead, after building a frequency table of normal strings in your environment with freq.py, you start a server up to allow services to measure various strings against that table. You can run multiple servers to provide access to different frequency tables. When starting the server you must provide a TCP port number and a frequency table. Here is the help for the program:
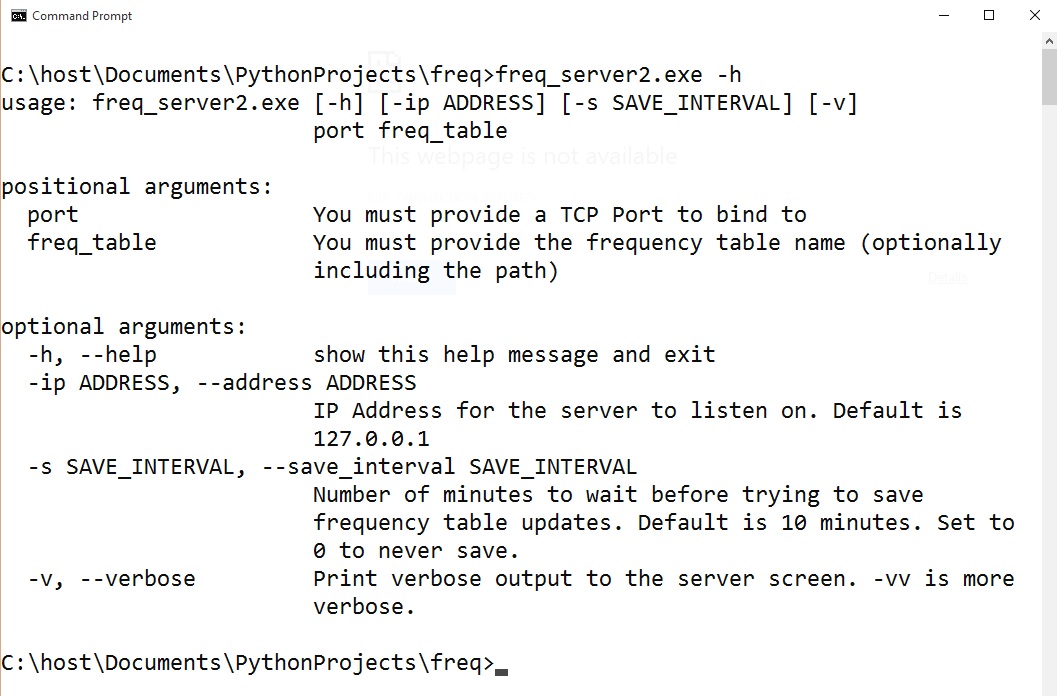
Once the server is started you can use anything capable of making a web request to measure a string. If you make an invalid request the server will provide you with documentation on the API syntax:
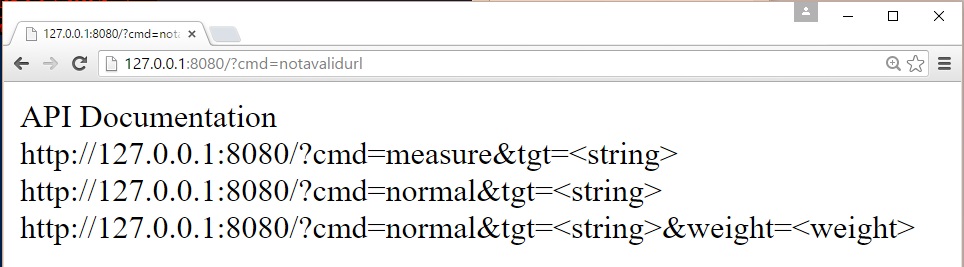
Although the API supports both measuring and updating tables, I recommend only using the measure command. If you need to update tables I recommend using freq.py. There are a couple of reasons for this. First, you should only use screened, known good data when building your frequency tables. Second, every time the frequency tables are updated the server will flush its cache so you should expect there to be a performance hit. Between each request to the web server the server will check to see if you hit Control-C and if you did it will clean up the threads and save the updates to the frequency tables before quiting.
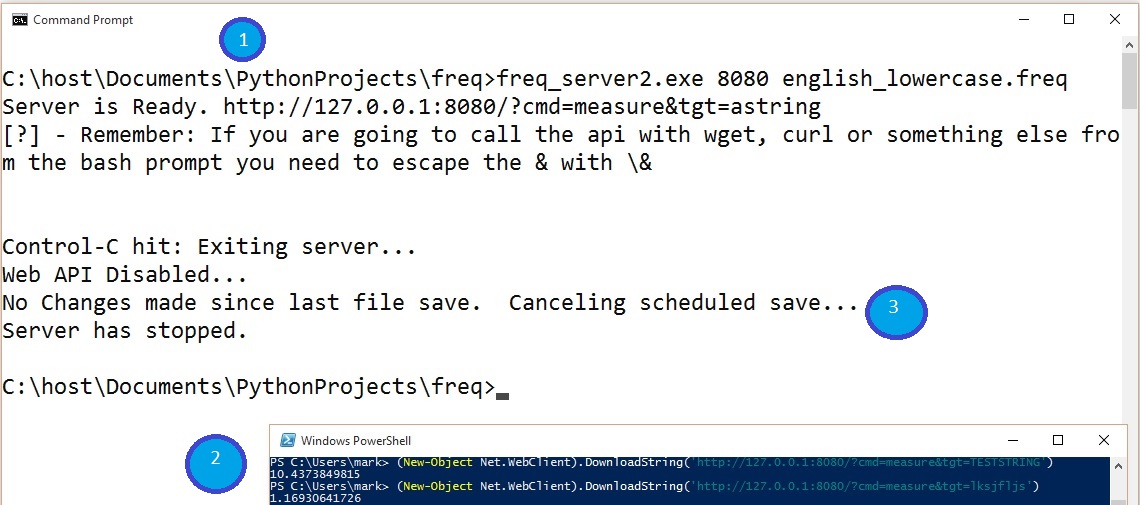
Here is an example of starting the server (Step 1) and measuring some strings using Powershell’s (New Object Net.WebClient). DownloadString(“http://127.0.0.1/?cmd=measure&tgt=astring”) (Step 2) and stopping the server by hitting CONTROL-C (Step 3).
Powershell is awesome, but there are lots of ways to query the server. You could simply use wget or curl from a bash prompt. Here is an example of using wget to query the API:

Notice that, in this case, we have to escape the & with the backslash. This can also be integrated into your SEM and enterprise monitoring systems. Justin Henderson, GSE #108 and enterprise defender extraordinaire, has already done some testing integrating this into his infrastructure and he was kind enough to share those results. I’ll let him share that with you… Justin?
By Justin Henderson @SecurityMapper
When I first saw freq.py I instantly saw the potential for large scale frequency analysis using enterprise logs. To make the story short, I finally found some free time and attempted to put freq.py to use during log ingestion and that’s when we discovered it didn’t like being called constantly. After sharing what I was trying to do with Mark he whipped out his mad awesome python skills and next thing you know I’m doing a beta of freq_server.py.
In my environment I am using Elasticsearch, Logstash, and Kibana, or ELK for short, as my log collection, storage, and reporting. Logstash is the component that is ingesting logs and parsing them. As a result, I added a call to freq_server.py in the configuration files for any logs I want to do frequency analysis with. Below is an example of how I’m making a call to freq_server.py from within a bro DNS configuration on Logstash:

The full configuration file can be found in GitHub and is called bro_dns.conf. To see this file or many others visit it at https://github.com/SMAPPER/Logstash-Configs.
The initial testing of freq_server.py went off without a hitch. I did a burn in test of over 4 million DNS records running through freq_server.py in about 36 hours and it worked and remained stable. Now with all this data it is easy to look for random generated domains.
For example, logs with low scores (more likely to be random) look like:
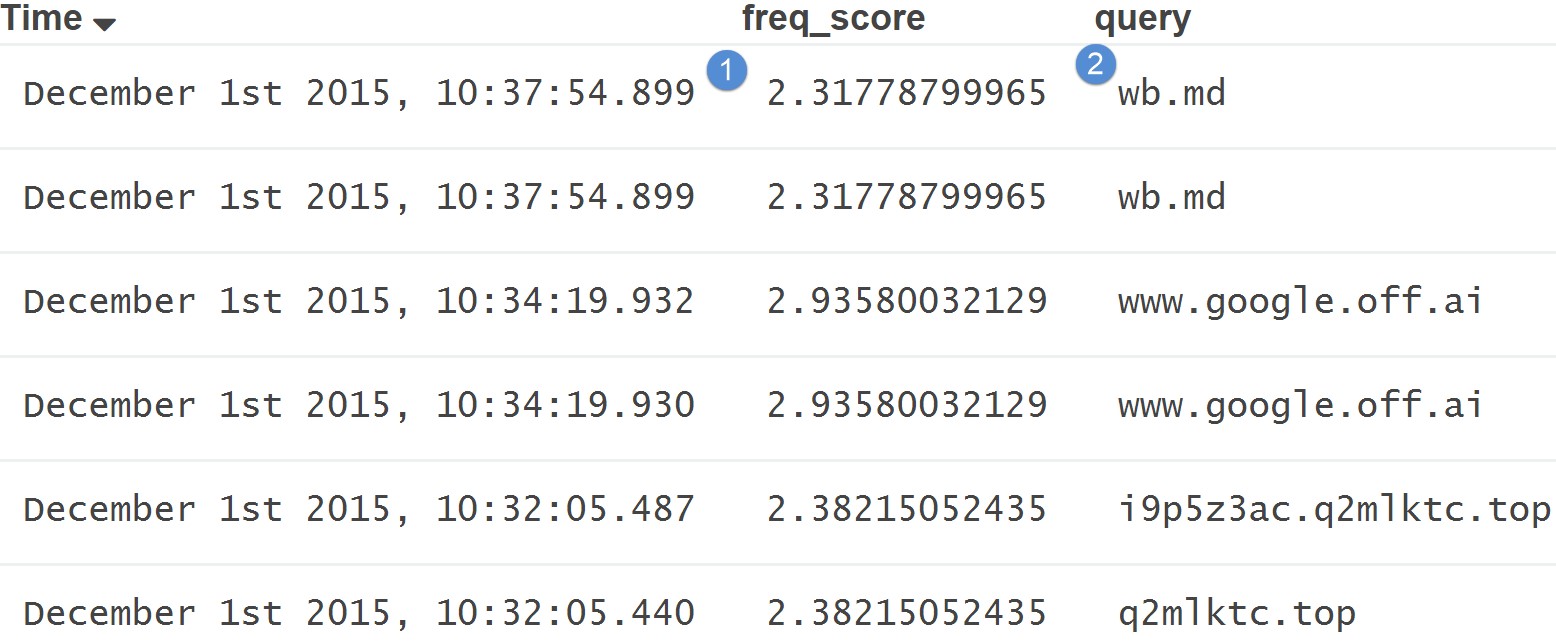
While logs with high scores or data that looks “normal” look like:
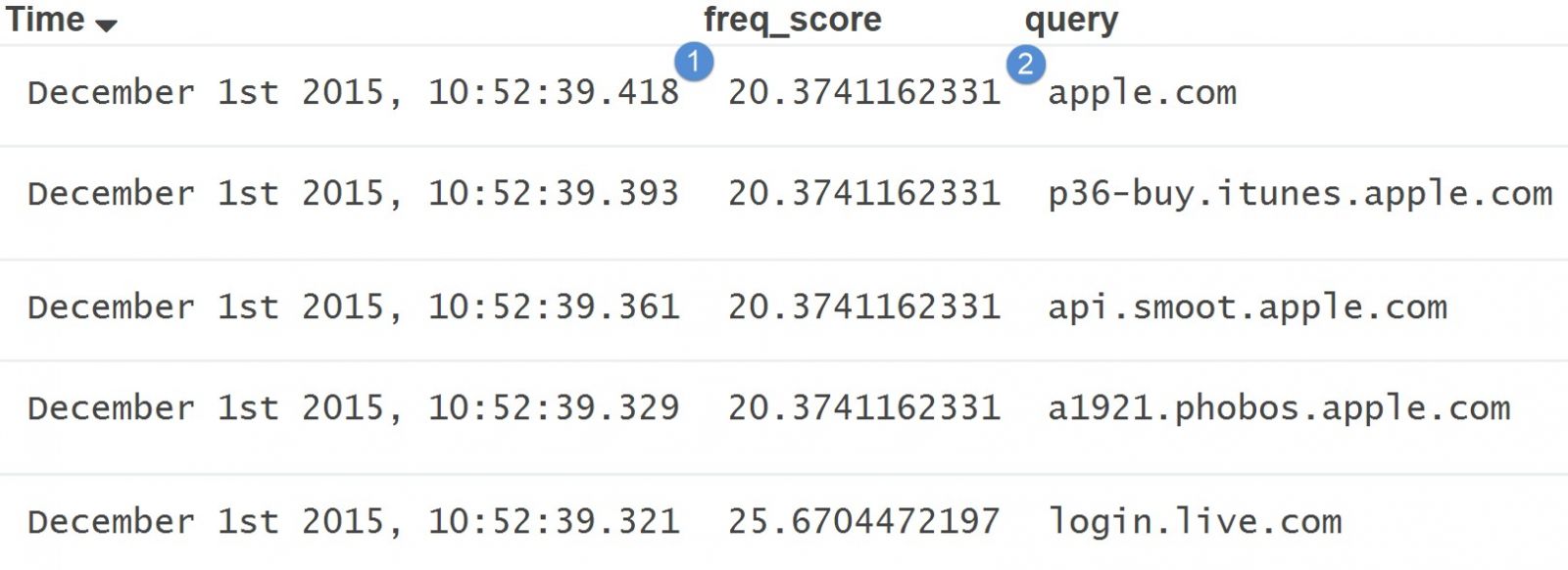
As you can see, based on my frequency tables, apple.com falls within an expected frequency score while things like i9p5z3ac.q2mlktc.top are considered random based on my frequency tables.
Now think of the real world use cases for this… Let’s take the example of malware exploiting a system and calling down a payload such as Meterpreter. The malware may be pulled down from a web server using a random domain name, URL path, and/or filename. At this point we as defenders should have DNS logs, proxy logs, and possibly file metadata logs from something like Bro. After the payload is launched it commonly will create a service with a randomly generated name and then delete this service. At this point we additionally have a Windows event log with a random service name and a Windows event log on the deletion of that service.
Now I’m not saying the stars will always align…. but with frequency analysis we now have four sources to test for entropy or randomness. That now is four sources where one attack could have possibly been discovered. And the use cases could just go on…
To sum it all up, thanks and a big shout out to Mark for first creating freq.py and now freq_server.py. It’s another step in the right direction for defense.
Thanks Justin!
To Download a copy of freq.py and freq_server.py follow this link here to my github page:
https://github.com/MarkBaggett/MarkBaggett/tree/master/freq
Does freq_server.py fall short of something you need it to do? Send me an email and I'll see if I can make it work for you. Or come check out my Python class and learn how to adopt the code yourself!. SEC573 Python for Penetration testers covers topics every defender can use to protect their network. Non-programmers are welcome! We will start with the essentials and teach you to code.
Come check out Python in Orlando Florida, Berlin Germany or Canberra Australia!! For dates and details click here.
https://www.sans.org/course/python-for-pen-testers
Follow me on Twitter at @MarkBaggett
Follow Justin at @securitymapper
So what do you think? Leave me a comment.


Comments