Command Line Parsing - Are These Really Unique Strings?
There are occassions where data needs to cleaned prior to use. One example came to me while reviewing passwords submitted to one of my DShield honeypots. There appeared to be duplicate passwords, even when I attempted to export unique values from the command line.
# read cowrie JSON files in /logs/ directory
# cat /logs/cowrie.json.*
#
# select data where password key is present
# jq 'select(.password)'
#
# return password data in raw format (without quotes)
# jq -r .password
#
# sort the data alphabetically
# sort
#
# deduplicate the data and store in a text file
# uniq > 2023-08-15_unique_passwords_raw.txt
#
cat /logs/cowrie.json.* | jq 'select(.password)' | jq -r .password | sort | uniq > 2023-08-15_unique_passwords_raw.txt
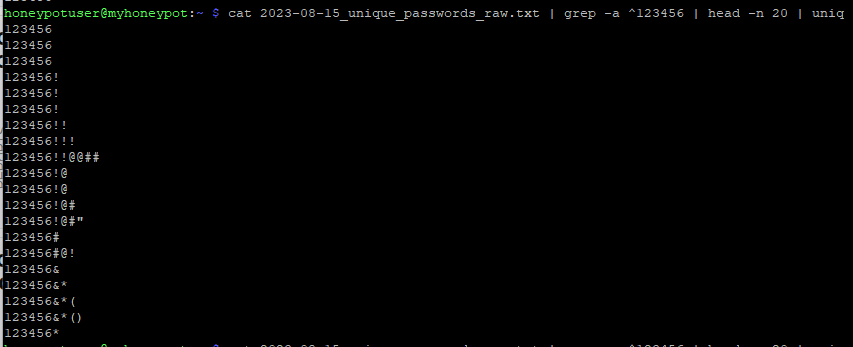
Figure 1: Output of exported data showing what appear to be duplicate values
In the example above, it would appear that "123456" is being displayed three times from the exported text, even when attempting to remove duplicates from the resulting file. Since the project being worked on involved comparing data using Python, it seemed like a good idea to use Python to compare these values.
import os
passwords = []
passwords_bytes = []
# read data from text file into passwords list
with open("2023-08-15_unique_passwords_raw.txt", "r", encoding="utf-8") as file:
for line in file:
passwords.append(line)
# read data from text file as bytes into passwords_bytes list
with open("2023-08-15_unique_passwords_raw.txt", "rb") as file:
for line in file:
passwords_bytes.append(line)
# print passwords begining with "123456"
for index, password in enumerate(passwords):
if password[:6] == "123456":
print(index, password, passwords_bytes[index])
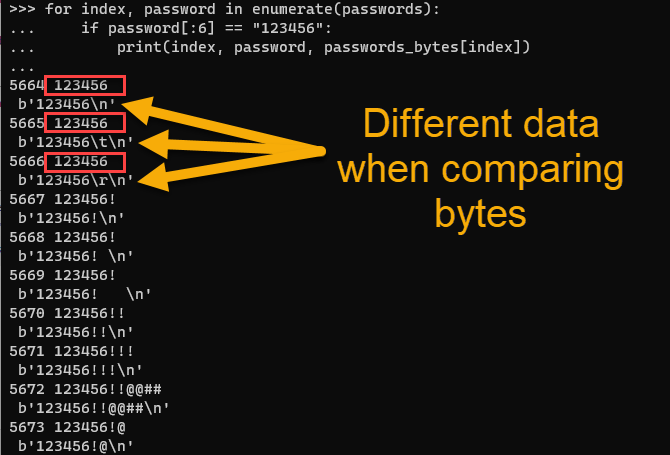
Figure 2: Comparing bytes data with Python shows additional formatting data
Now the differences between the data is clear when looking at the Python bytes values. This was not easy to recognize when using the "cat" defaults :
- \n - newline / line feed, this was anticipated in a text file with items per line
- \t - tab
- \r - carriage return (returns to the beginning of the same line)
There are also some "cat" [1] options to highlight the same information.
cat -A 2023-08-15_unique_passwords_raw.txt | grep -a ^123456 | head -n 20
123456$
123456^I$
123456^M$
123456!$
123456! $
123456! $
123456!!$
123456!!!$
123456!!@@##$
123456!@$
123456!@ $
123456!@#$
123456!@#"$
123456#$
123456#@!$
123456&$
123456&*$
123456&*($
123456&*()$
123456*$
Using the "A" option gives comparable output:
- $ - newlines
- ^I - tab
- ^M - carriage return
An additional option is to use the "od" command, which gives output just like the Python bytes output.
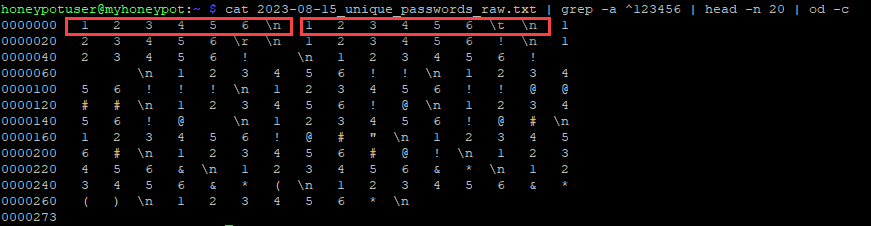
Figure 3: Output of "od" command showing extra string formatting
Some of this data data can also be removed easily. An example from the terminal to remove tabs and carriage returns:
cat 2023-08-15_unique_passwords_raw.txt | grep -a ^123456 | head -n 20 | tr -d "\t" | tr -d "\r" | uniq
123456
123456!
123456!
123456!
123456!!
123456!!!
123456!!@@##
123456!@
123456!@
123456!@#
123456!@#"
123456#
123456#@!
123456&
123456&*
123456&*(
123456&*()
123456*
Knowing a bit more on exactly what was happening also helped me compare the data in a different way.
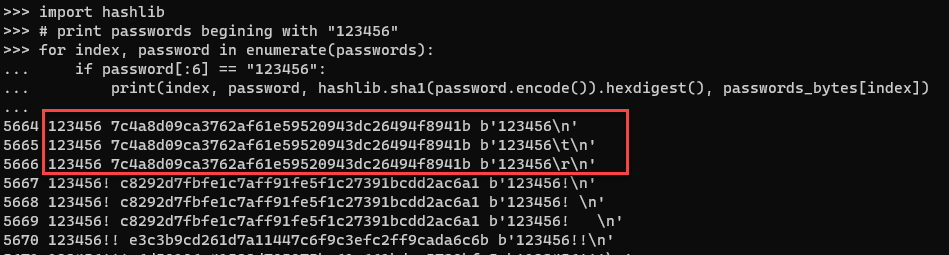
Figure 4: Password hashes of data compared with passwords in Python bytes
My original goal was to hash all of the unique honeypot passwords that I have collected and compare them with data in HaveIBeenPwned [3]. Upon reviewing the data in more detail, another option presented itself. The bytes data could also be used directly with hashlib.
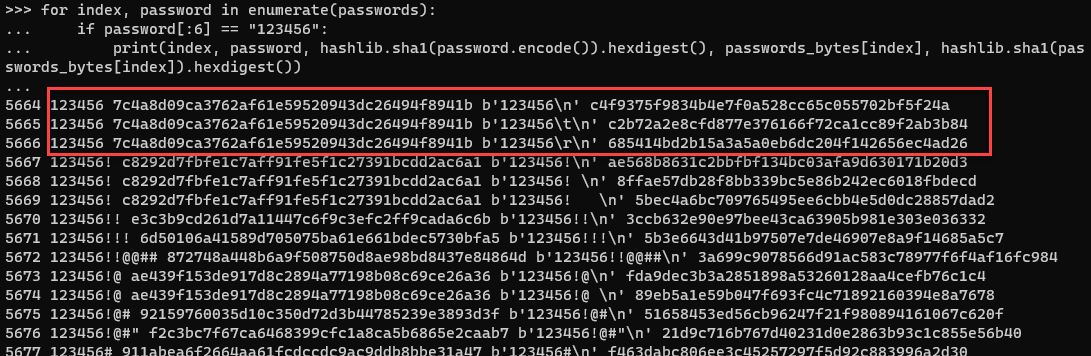
Figure 5: Comparison of password hashes when using utf-8 or bytes data from a text file of passwords
This is not ideal since the newlines are undesired, but it gives another path when processing the data. Just a good reminder that while values look unique, they may not be. It's helpful to explore data and see if any data cleaning is necessary. In my case, more cleaning is needed.
[1] https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/
[2] https://www.cyberciti.biz/faq/how-to-remove-carriage-return-in-linux-or-unix/
[3] https://haveibeenpwned.com/Passwords
--
Jesse La Grew
Handler


Comments