Incident-response without NTP
While we patiently await the arrival of this month's patches from Microsoft (and everyone else who publishes today) I have a little thought experiment for you. We all know that the internet doesn't work too efficiently if DNS isn't working or present. NTP is just as critical for your security infrastructure. Without reliable clock synchronization, piecing together what happened during an incident can become extremely difficult.
Consider a hypothetical services network and DMZ: there's an external firewall, a couple of webservers, an inner firewall with a database server behind it. Let's also assume that something bad happened to the webservers a couple of months ago and you've been brought in as a consultant to piece together the order of events and figure out what the attacker did. The web administration team, and the database team, and the firewall team have all provided your request for logs and you've got them on your system of choice.
More About NTP
For a complete background on NTP I recommend: http://www.ntp.org/ntpfaq
There are two main types of clock error that we are concerned with in this example:
- Clock Skew also called Accuracy, determines how close a clock is to an official time reference.
- Clock Drift or the change in accuracy over time.
Common clock hardware is not very accurate; an error of 0.001% causes a clock to be off by nearly one second per day. We can expect most clocks to have one second of drift every 2 days. The oscillator used in computer clocks can be influenced by changes in local temperature, and the quality of the electricity feeding the system. Update: Joanne wrote in to point out that the accuracies that I've cited in this paragraph are an order of magnitude better than what one would expect in computer hardware. We'll see later in some example data how optimistic my values were.
Today's Challenge
How do you begin order the events between the systems? First I'll solicit general approaches via comments and email, later I'll summarize and provide some example data to illustrate the most popular/promising approaches.
Example Data
Let's take a look at what the web team and the firewall team sent to us.
Date Time Event Epoch
Web1:
1/1/1972 13:24:04 First Request from badguy 262990.55837962962963
1/1/1972 13:24:04 2nd Request from badguy 262990.55837962962963
1/1/1972 13:24:04 3rd Request from badguy 262990.55837962962963
1/1/1972 13:24:05 4th Request from badguy 262990.558391203703704
1/1/1972 13:24:09 5th Request from badguy 262990.5584375
Web 2:
1/1/1972 13:25:37 First Request from badguy 262990.559456018518519
1/1/1972 13:25:41 2nd Request from badguy 262990.559502314814815
1/1/1972 13:25:57 3rd Request from badguy 262990.5596875
1/1/1972 13:26:49 4th Request from badguy 262990.560289351851852
1/1/1972 13:26:59 5th Request from badguy 262990.560405092592593
1/1/1972 13:27:42 6th Request from badguy 262990.560902777777778
Firewall:
1/1/1972 7:00:41 Accept "tcp_80" "34153" "bad_guy_ip" "web1" 262990.292141203703704
1/1/1972 7:00:43 Accept "tcp_80" "34154" "bad_guy_ip" "web1" 262990.292164351851852
1/1/1972 7:00:45 Accept "tcp_80" "34155" "bad_guy_ip" "web1" 262990.2921875
1/1/1972 7:00:49 Accept "tcp_80" "34156" "bad_guy_ip" "web1" 262990.292233796296296
1/1/1972 7:00:52 Accept "tcp_80" "34157" "bad_guy_ip" "web1" 262990.292268518518518
1/1/1972 7:02:27 Accept "tcp_80" "59498" "bad_guy_ip" "web2" 262990.293368055555556
1/1/1972 7:02:31 Accept "tcp_80" "59499" "bad_guy_ip" "web2" 262990.293414351851852
1/1/1972 7:02:47 Accept "tcp_80" "59500" "bad_guy_ip" "web2" 262990.293599537037037
1/1/1972 7:03:39 Accept "tcp_80" "59501" "bad_guy_ip" "web2" 262990.294201388888889
1/1/1972 7:03:49 Accept "tcp_80" "59502" "bad_guy_ip" "web2" 262990.29431712962963
1/1/1972 7:04:32 Accept "tcp_80" "59503" "bad_guy_ip" "web2" 262990.294814814814815
I've merged added the epoch column since that will help some folks apply their favorite methods and trimmed the logs from the three systems down to the activity of one suspicious IP address.
My Naive Approach
My initial assumption is that we should be able to account for the bias between the clocks on sufficiently-small windows of time. We will not likely come up with a simple formula to correct several months-worth of logs. However, for critical periods, we should be able to knit together log events from multiple systems, identify the clock bias, and account for it in the ultimate investigative timeline. So my approach is to pick a small time-frame of events, pick a system to be the reference point, tie events together manually a bit, and plot it out to see if there is a simple linear relationship, or if we have other issues.
Immediately we see that there's clearly a timezone difference between the web team and the firewall team, that's not a big deal at the moment. Initially we may feel in luck that the firewall can act as a semi-reliable observer to compare the attack against web1 and web2. Maybe fortune will continue and we can simply shift the times a little to account for clock skew. The event was only a few seconds so the window should be small enough that drift should be undetectable, right?
No, something's not right. If we compare the elapsed time of the event for web1 and web2 using the firewall as a frame of reference. While the firewall and web2 agree that it was visited over 2 minutes and 5 seconds, web1 records an elapsed time of 5 seconds, while the firewall indicates 11 between the first accept and the last accept.
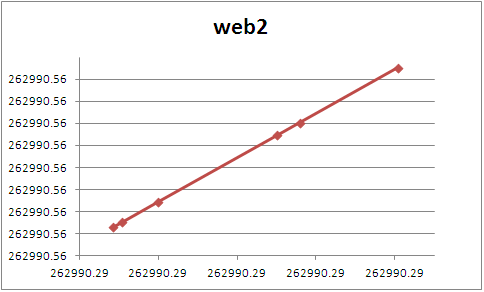
Let's plot out the times from the web server vs. the time noted by the firewall. Ideally we should see something of a straight line with a slope of one and a zero-intercept of zero. In this case, we're hoping for a slope near one, and a zero-intercept that will help identify the timezone used by the firewall or the webservers.

How about a closer look at those two:
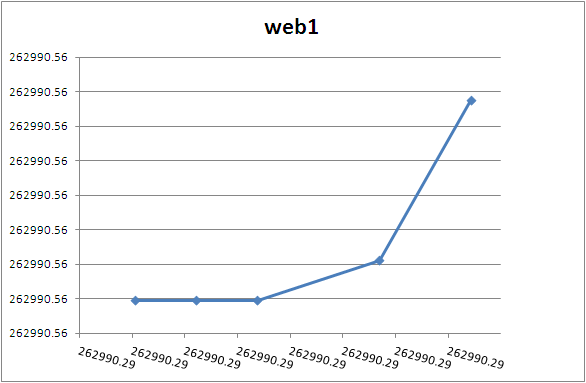
Web 1 recorded the first few probes as happening in the same second. Over time though (draw a line between the first and last event) and it's a bit more in agreement with web2.
A Side Note About the Comments
The comments strayed off-topic pretty quickly today, but there are some nice gems in there about deploying and monitoring NTP. They're worth a look.


Comments
n3kt0n
May 8th 2012
1 decade ago
John
May 8th 2012
1 decade ago
Finally, all of our servers' clocks are monitored via nagios (I just recently uploaded a nagios plugin to exchange.nagios.org for comparing a local clock against multiple NTP servers and reporting the average offset - search for "sgichk" if you want it). For servers whose logs are most critical (email relays, DNS servers, etc) nagios throws an alarm if they're clocks are off by a fraction of a second. Less critical systems we don't throw an alarm unless the clock is off by a few seconds and/or unless the clock is off for a lengthier period of time.
Lastly, Linux VMs can be a pain to keep their clocks in sync. You may need to boot with special kernel tweaks and/or special options set in ntp.conf (vmware has a whole page about this). And what vmware needs is dependent from one flavor/version of linux to another. (whether or not one uses VDR seems to play a role too)
Brent
May 8th 2012
1 decade ago
Another possibility is using something like syslog-ng on a centralized server to automagically adjust the times on syslog data coming from a server with a different timezone to the timezone of the centralized server.
Basically, the ideal is to have all of your logged events using times in the same timezone so you don't have to do the mental arithmetic while looking at logs for different servers/devices/services during a crisis. Whether this is done by making all the systems have the same timezone or tweaking the software writing the logs to write events using the same timezone (or some other mechanism) is up to you.
Brent
May 8th 2012
1 decade ago
In reality, what Windows does when DST comes into effect, is add one hour to the local timezone.
Hence a timestamp that was written at 23:30 local _winter_ time may appear to have taken place the next day if you look at it in summertime.
See for example http://ask-leo.com/why_do_file_timestamps_compare_differently_every_time_change.html
Bitwiper
May 8th 2012
1 decade ago
Joshua
May 9th 2012
1 decade ago
Second, 1/1/1972 was a long time ago. I thought Tim Berners Lee was responsible for developing the first web servers at CERN in the early 90s. Wikipedia places it on Aug 6, 1991. So perhaps the records you are getting are a bit suspect. The epoch values are also a little strange - if those are supposed to be Unix epoch timestamps, those should be for Sun Jan 4 01:03:10 1970 or thereabouts, which is even earlier. Hell, all of this even predates the TCP/IP specifications. If y'all are using time machines, you should be aware that they have a tendency to wreak havoc with NTP!
Third, if you have servers in different timezones, it's possible they are also geographically separated. Since you have a single firewall, there could be routing delay issues that further complicate things. I support machines (luckily not servers, just workstations) that are on the other end of satellite links with 600ms latency. Under heavy congestion, I regularly see ping values in the 3 to 5 second range. That could cause some log skew!
Anonymous
May 9th 2012
1 decade ago
I am fond of using SSH brute force scans to sync, I'll pull those out of the logs and see how that pans out...
KL
May 9th 2012
1 decade ago
For web server logs or Windows Event Logs (or really any delimited text-file with a time column), you could work something out with Microsoft's LogParser. Seriously, LogParser is an incredibly useful tool for all sorts of log manipulation and extraction.
Jason
May 9th 2012
1 decade ago