Phishing PDF With Incremental Updates.
Someone asked me for help with this phishing PDF.
Taking a look with pdfid.py:
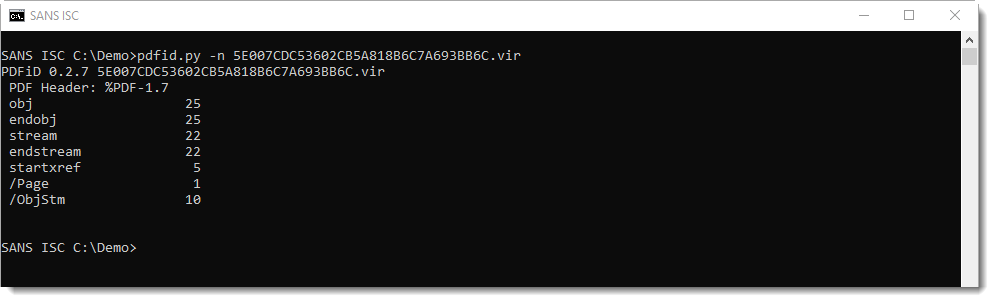
Nothing to see here, except Stream Objects (/ObjStm). When stream objects are detected, it's best to generate statistics (-a) with pdf-parser.py while parsing stream objects too (-O), like this:
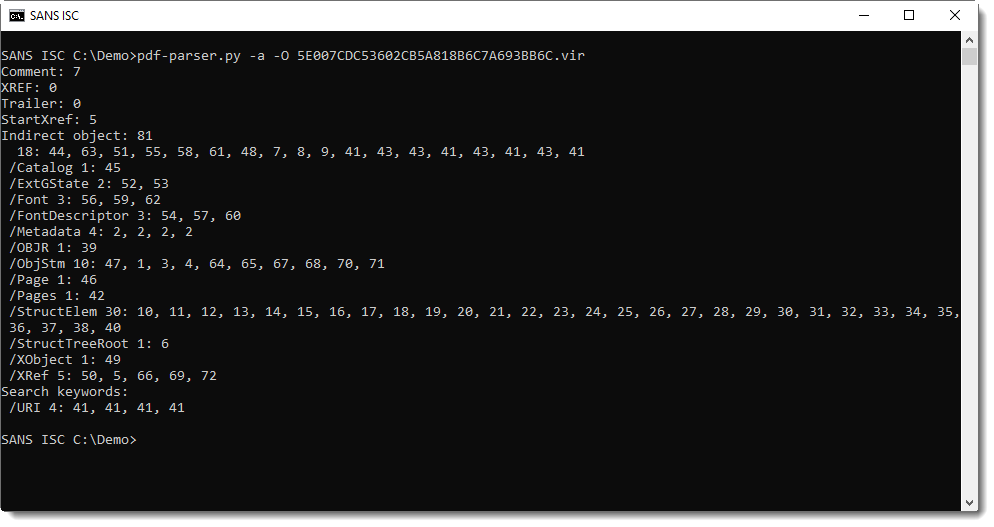
And here we see that this PDF contains URLs (/URI). Thus we can filter for URLs like this:
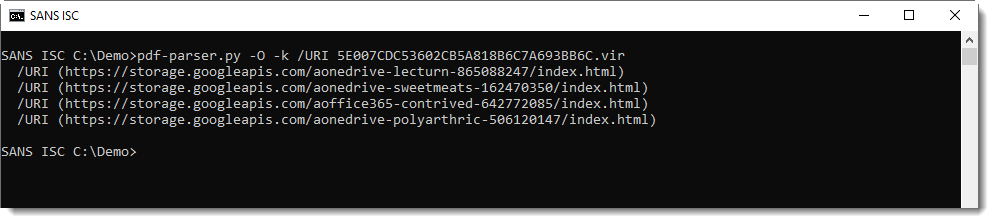
Now, this person that contacted me had figured this all out, but had a specific question: why 4 different URLs, when the rendered PDF shows only one link:
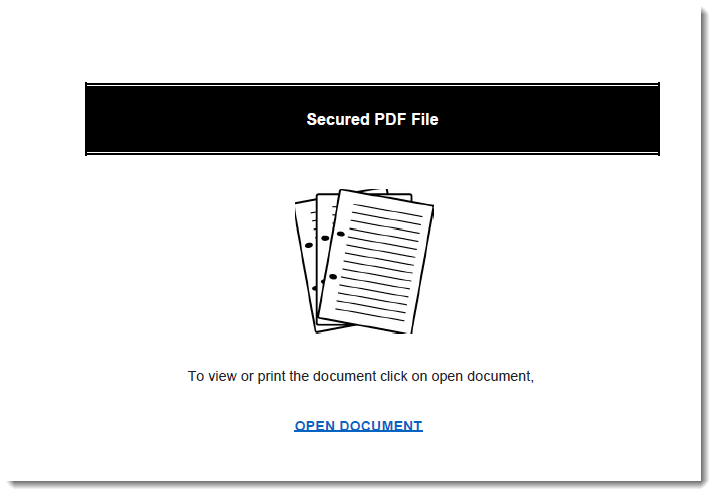
The reason is incremental updates. An incremental update is an update to a PDF (a modification) by appending a modified copy of all objects to be updated, while leaving the original objects intact. Incremental updates are delimited by %%EOF: this can be detected with pdfid.py option -e:
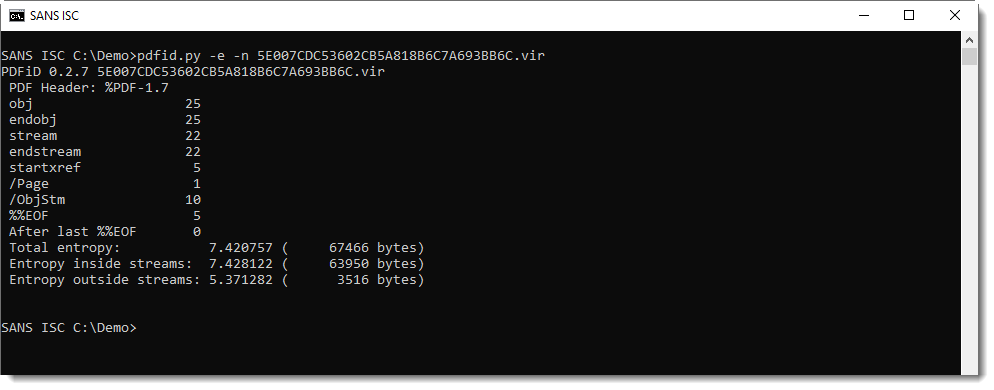
Option -e provides extra information, for example a counter for string %%EOF.
We can see that %%EOF appears 5 times here, hence it's likely that there are several incremental updates in this PDF.
Coming back to this result, all URIs are in objects with index 41: this too is an indication of incremental updates (objects keep their index number when copied & modified via incremental updates):
The second instance of object 41 is separated from the first instance of object 41 by %%EOF: this means that the second instance is an incremental update. It's a copy of the first instance, with a modified /URI.
And the same goes for the third and fourth instances:
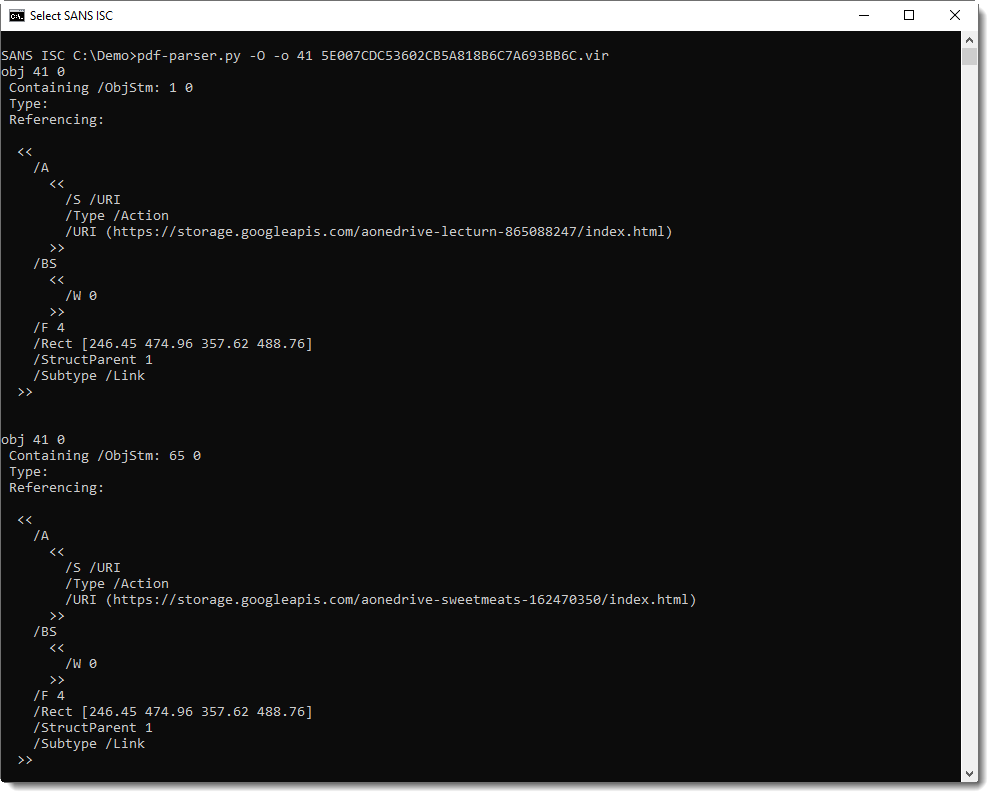
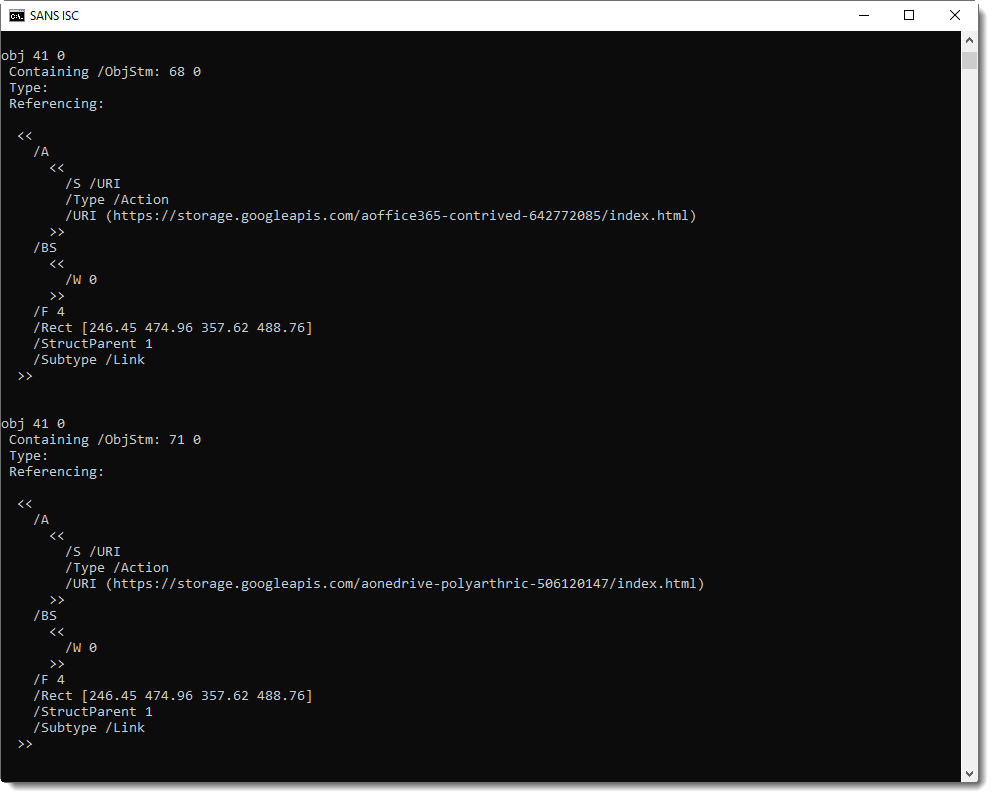
That is the technical explanation: this PDF documents contains several URLs, with only one active, and this is achieved via incremental updates.
But why is this happening at all? My hypothesis: this malware author is reusing the same PDF for different phishing campaigns, and is not aware that his tool creates incremental updates (as opposed to normal updates, where objects are modified in-place). One element to support this hypothesis, is the fact that the metadata (object 2) is also modified via these incremental updates:
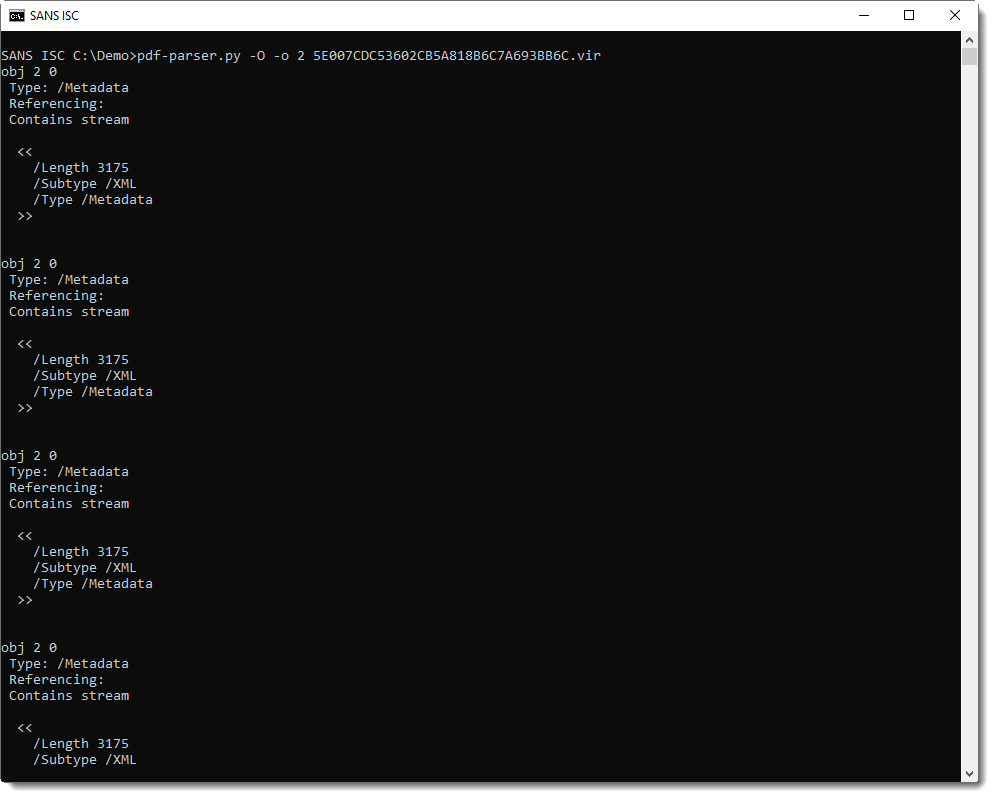
Here is the content of the XML metadata of the first instance of object 2:
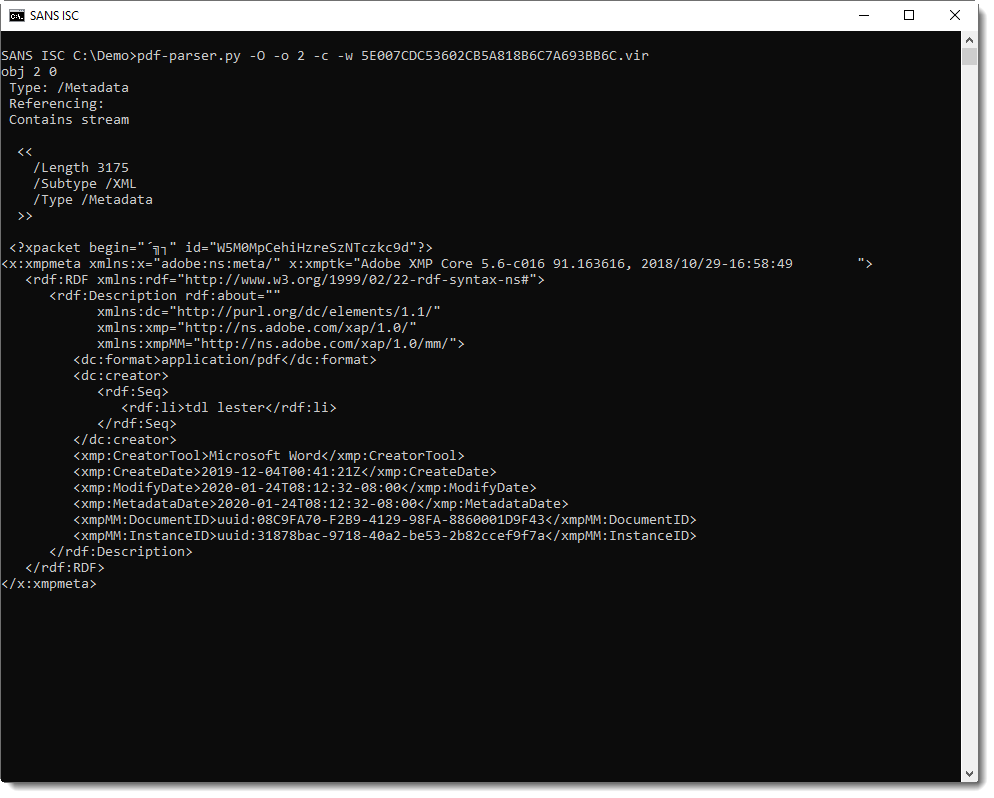
According to this metadata, the PDF document is created with Microsoft Word, by "tdl lester", and we have creation and modification timestamps in ISO format. I can extract these with my tool re-search.py:
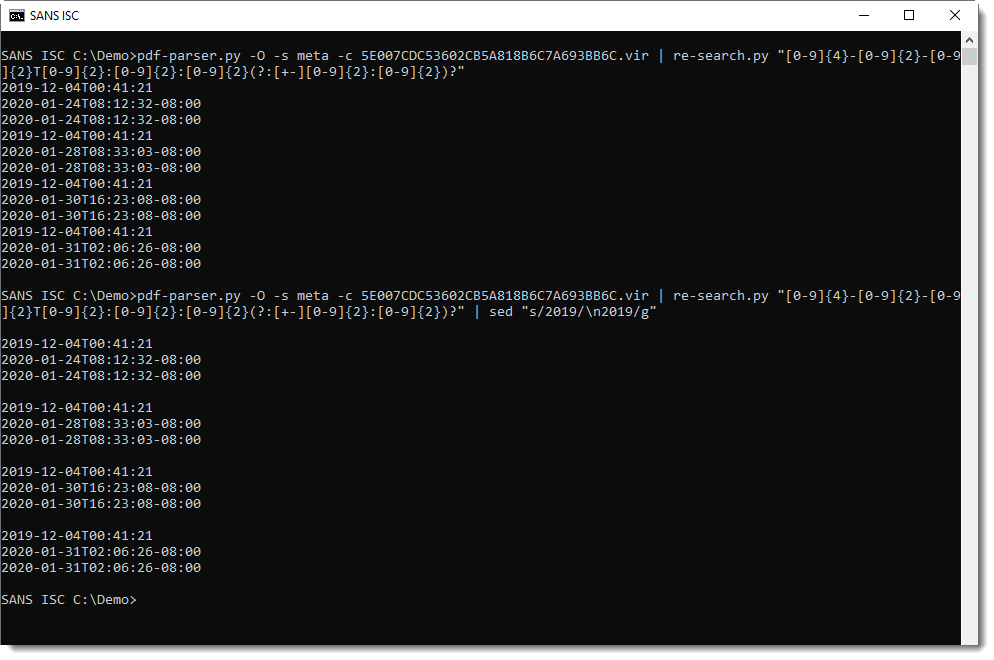
These timestamps show that this was modified on 4 different dates. The last date, January 31st 2020 corresponds to the submission on VirusTotal. I was not able to find the other documents on VirusTotal, neighter via ISO timestamps nor via hashes of the original PDFs (original PDFs can be easily recovered from "incremental update" PDFs: remove all bytes after a %%EOF element).
But I was able to find 27 PDFs on VirusTotal by searching for "tdl lester", which I will analyze later.
My answer to the question "why does this PDF contain 4 URLs, with only one active?": this PDF contains incremental updates, the malware author is reusing the same document for different phishing campaigns, and the inactive URLs you see are from prior phishing campaigns.
One last remark concerning the metadata: the ISO modification timestamps have a UTC timezone of -08:00. The Pitcairn Islands are part of that TZ. Imagine that this phishing PDF document was created by a descendant of a Bounty mutineer ...
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments