Text and Text
I gave a few tips over the last weeks to help friends with processing files. Turned out that each time, UNICODE was involved.
Xavier had an issue with a malicious UDF file. I took a look with a binary editor:
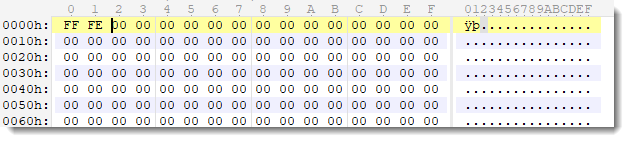
The first bytes, FF FE, reminded me of a BOM: a Byte Order Mark. FF FE or FE FF can be found at the start of UTF-16 text files. It indicates the endianness: little endian (screenshot) or big endian.
Command file confirmed the endianness:

The fact that it contains just null bytes is unusual, but then again, this is actually not a text file, but an UDF file that was probably opened and saved with a text editor.
Another friend had a problem having a an XML file parsed by a SIEM. It threw an unusual, obscure error. It turned out here too, that the file was UNICODE, while the SIEM expected an ASCII file.
When opening text files with an editor, it's often not trivial to determine the encoding of the file. And not everyone is comfortable using an hexadecimal error.
If you want a command-line tool, I recommend the file command.
For a GUI tool on Windows, you can use the free text editor Notepad++.
It displays the encoding of the displayed file in its status bar:
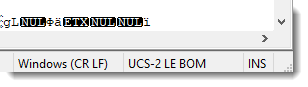
LE BOM tells us that the file contains a BOM and is little endian. UCS-2 (an ISO standard equivalent with UNICODE and the basis for UTF-16). And we get bonus information: the line separator is carriage return / linefeed (CR LF). This was something Xavier had to deal with too.
This editor can of course convert encodings:
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments