PDF documents & URLs: update
I've written before about PDFs with URLs used in social engineering attacks (TL;DR: nowadays, it's more likely you'll receive a malicious PDF that just contains a malicious URL, than a PDF with malicious code).
Since then, I've had a couple of questions about such PDFs where the URL is stored indirectly. Let me give you an example.
I'm using pdfid.py to do a first check of the pdf (I'm using option -n to suppress counters that are equal to 0):
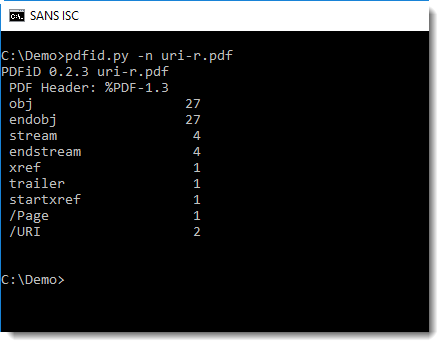
You can see that name /URI appears twice: this is a strong indication that the PDF contains a URL.
Let's extract the values for name /URI with pdf-parser.py:
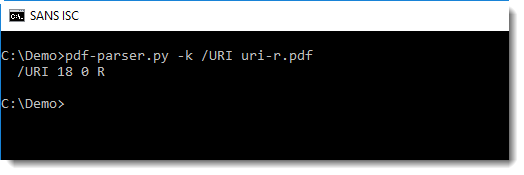
Instead of extracting the URL, we see that value "18 0 R" was extracted. 18 0 R is a reference to an object with id 18 and version 0.
pdf-parser's option -o can be used to look at this object:
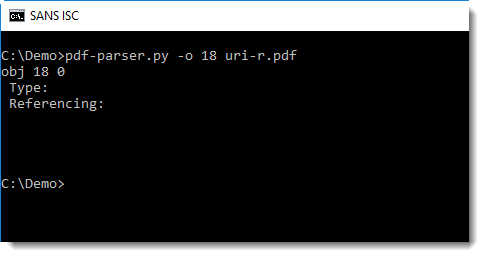
By default, pdf-parser displays the dictionary of an object, but not the data. To view this data, use option -w:
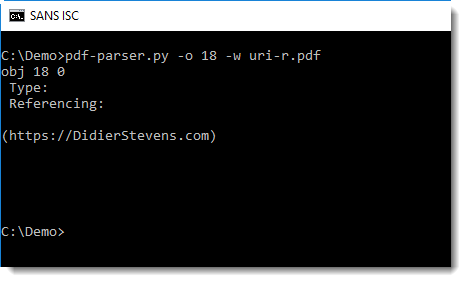
Now we can see that object 18 is just a string: the URL we wanted to extract.
Didier Stevens
Microsoft MVP Consumer Security
blog.DidierStevens.com DidierStevensLabs.com


Comments