Incident Response vs. Incident Handling
One of the things that comes ups frequently in discussion is the difference between incident response, and incident handling. Anyone who has had to deal with an incident has likely encountered this situation at least once. While attempting to work on analyzing what the #$%& happened you always have your senior executive and/or clients hanging over your shoulder constantly bugging you for more details. The containment plan needs to be worked out, someone needs to liaise with Legal/HR/PR, management wants an update, the technical staff need direction or assistance, teams need to be coordinated, everyone wants to be in the loop, lots of yelling is going on, external IRTs want to know why your network is attacking theirs, nobody can locate the backups, keeping track of activities, taking notes, and the list goes on… No wonder people regularly burn out during incidents! Incident handling is obviously not a solo sport.
The best line for this problem came from the hot wash (post incident debrief) of a major exercise, where one of the leads stood up to the table of senior executives, and calmly explained "No, no you will NOT go talking to the team. You will talk to me. Only me. It is my job to keep you off their backs so they can do actual work".
That is the difference between Incident Response, and Incident Handling. Incident Response is all of the technical components required in order to analyze and contain an incident. Incident Handling is the logistics, communications, coordination, and planning functions needed in order to resolve an incident in a calm and efficient manner. Yes, there are people who can fulfill either role, but typically not at the same time. The worse things get, the greater the requirement for the two different roles becomes.
These two functions are best performed by at least two different people, although in larger scale incidents this may need to be two leads who work closely together to coordinate the activities of two separate teams. In smaller environments ideally the Incident team should still always be two people, one responding, and the other taking notes and communicating with stakeholders.
It should also be noted that the skill sets for these two are different as well. Incident Response requires strong networking, log analysis, and forensics skills; incident handling strong communications and project management skills. These are complementary roles which allow the responders to respond, the team to work in a planned (or at least organized chaos) fashion and the rest of the world to feel that they have enough information to leave the team alone to work.
Thanks to a former colleague who helped me writing this.
Thoughts or feedback?
Update: Rex wrote in the following: US workers in emergency services (fire, police, ambulance, first aid), are trained in the Incident Command System: http://en.wikipedia.org/wiki/Incident_Command_System
which defines a number of important roles in handling an emergency incident.
Small teams won't have enough members to put one person in each role. Experience shows that the "hands-on" members *must be left alone*, even if you need to do on-the-spot recruitment to handle PR, crowd control, logistics, etc. Another key concept is "one person in charge per function" - one commander, one PR person, one chief medic, etc.
Maybe the IT security incident response/handling world should steal good ideas from people who deal with life-and-death emergencies. Soon, IT emergencies will be life-and-death emergencies.
Cheers,
Adrien de Beaupré
Intru-shun.ca Inc.
Some conficker lessons learned
These are the lessons learned from a conficker outbreak at an academic campus. Thanks for writing in Jason.
The outbreak was not due to a lack of patching. The vast majority of the machines that were compromised via the worm were managed machines and were in fact patched up to date - including the patch for MS08-067 - and have actively maintained anti-virus software installed.
As a refresher, recall that conficker propagates via number of methods:
- Removable media with auto-run.
- Leveraging the privileges of the currently logged in user.
- Exploiting un-patched vulnerabilities (MS08-067).
- Brute-forcing credentials.
While we cannot currently release all relevant details regarding the outbreak at the (name removed), we'd like to share a few of the lessons learned.
- Ensure that when an average user logs in it does not allow them to mount via RPC resources on other workstations in the domain. (i.e. When Alice logs into her workstation she cannot mount the Admin$ share on Bob's machine without being prompted for credentials.) Using the GPO [Computer ConfigurationWindows SettingsSecurity SettingsLocal PoliciesUser Rights AssignmentAccess this computer from the network] to limit RPC logins to workstations can be very helpful in this regard. see: <http://technet.microsoft.com/en-us/library/cc740196.aspx>
- Disable Auto-Run on all machines. This can also be accomplished via GPO.
- Ensure that all anti-virus software is very up-to-date and is enabled to "On-Access" scan for both the reading and writing of files.
- Ensure that all machines are patched for MS08-067, including vendor managed machines.
- Ensure that all privileged accounts have strong passwords. Apparently conficker is smart enough to enumerate accounts with elevated privileges such as Domain Admins. We observed conficker attempting to brute-force unique domain admin accounts.
- Monitor for 445/TCP scanning, particularly off-subnet scanning.
- Force all users to utilize a proxy to access the web.
We have yet to find a single virus removal tool that catches all payload dropped by conficker. As usual, reinstalling an infected system is the only way to ensure a return to a trusted platform.Hopefully this information can be useful to you and will help you limit any outbreaks of conficker that may appear on your campus.
Cheers,
Adrien de Beaupré
Intru-shun.ca Inc.
Strange Windows Event Log entry
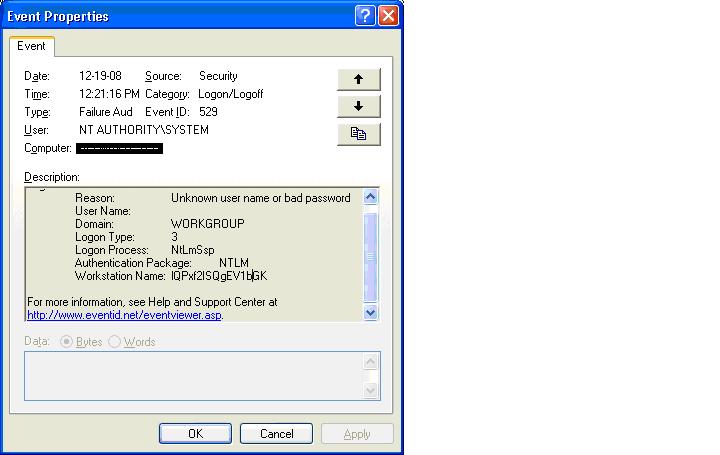
Checking our Bigbrother monitor we noticed some Security Event Log entries that seemed to indicate someone was knocking on the door, usually not very strange.. The strange part came when the same Workstation Name (Name = "lQPxf2ISQgEV1bGK") was presented from several different IP addresses.
Event Log Entry Example from 2003 (IP Changed to protect the ..)
security: failure - 2009/04/16 10:32:10 - Security (529) - NT AUTHORITY_SYSTEM
"Logon Failure: Reason: Unknown user name or bad password User Name: Domain: WORKGROUP
Logon Type: 3 Logon Process: NtLmSsp Authentication Package: NTLM Workstation
Name: lQPxf2ISQgEV1bGK Caller User Name: - Caller Domain: - Caller Logon ID:
- Caller Process ID: - Transited Services: - Source Network Address: 192.168.163.101
Source Port: 0"
-----
2008:
security: failure - 2009/04/16 10:31:44 - Microsoft-Windows-Security-Auditing (4625) - n/a
"The description for Event ID ( 4625 ) in Source ( Microsoft-Windows-Security-Auditing
) cannot be found. The local computer may not have the necessary registry
information or message DLL files to display messages from a remote computer. You
may be able to use the /AUXSOURCE= flag to retrieve this description_ see Help
and Support for details. The following information is part of the event: S-1-0-0_
-_ -_ 0x0_ S-1-0-0_ _ WORKGROUP_ 0xc000006d_ %%2313_ 0xc0000064_ 3_ NtLmSsp
_ NTLM_ lQPxf2ISQgEV1bGK_ -_ -_ 0_ 0x0_ -_ 192.168.163.101_ 1413."
Repeated over a few times on but with different Source Address.
Further searching on google with the strange Workstation name brings up other hits with the same name... none of which answer my question as it seems noone has yet tied the name to different IP addresses - they were visited from only the one source perhaps. 1st noticed this strange name at the beginning of March - but thought nothing of it as it all came from the same source address - and assumed it really was the workstation name. It wasn't until recently that it appeared from several IPs at the same time. This Event Log Entry appears on multiple (10-15) servers.
Hopefully an astute reader has already investigated or can share theories as to the source. Thanks Julian for writing in!
Update1: Shawn writes:
Here is a copy of one of the event log entries that we saw during an incident in December involving a worm that spread via MS08-067 (not conficker). These entries were found in the event log, and it I reasoned that it was a symptom of the server service being "crashed" by the exploit. The malware called itself vmwareservice.exe and installed as a service, in c:windowssystem.
Update2: Ed writes:
Regarding the recent diary post about the strange log entries, I can describe this in exacting detail. Just last week a customer was hit with new malware, which was a repackage of many different viruses, trojans, and bots. One of the spreading mechanism used the same exploit as Conficker, and the strange client hostname you mention is the same one we see in our forensic examples.
The spreading mechanism does not assume vulnerability to MS08-067, first attempting some brute force attacks before moving on to exploiting the vulnerability. It then dumps malware onto the target system's disk, most notably a file called svhost.exe which then executes as NETWORK SERVICE (as well as each user who logs in, thanks to a registry autorun). This executable then begins scanning the local subnet as well as network addresses close to the local network's value on port 445, and uses the same exploit/infection method.
In all cases we see the same garbage host ID in the event log. Some of the relevant filenames in the malwarwe we have seen are:
svhost.exe (MS08-067 exploiter and malware dropper)
sysdrv32.sys
[x]3.scr (same md5 hash as svhost.exe)
<numbers 1 through ~83>.scr (same md5 hash as svhost.exe)
stnetlib.dll (a downloader)
Things to look for in logs are the 445 connections bouncing off your internal Firewall interfaces, connection attempts on port 976 outbound (IRC) and also connection attempts outbound on port 80 (I can't remember the IP address right now). We're not sure at the moment which malware came first - it's the chicken and egg syndrome - but forensics continues. McAfee and Symantec both have signatures for most (if not all) of these files now.
Cheers,
Adrien de Beaupré
Intru-shun.ca Inc.


Comments