Making the most of your runbooks
To perform effective security incident handling, a standard model is often used. SANS through its GIAC GCIH affiliation certification teaches a six step model comprising of the following steps:
preparation, identification, containment, eradication, recovery and lessons learned.
Today, I want to look at preparation. Given that during the current economic climate we are all expected to do more with the same, or often less resource, now is the time to see how we can use preparation time to make our incident response skills slick, and effective whilst not raising operational costs.
As incident response teams mature from the chaos of the first incidents through to the slick teams we all hope they will become, optimizing the processes within the team is an important maturity step. The Capability Maturity Model defines these maturity steps as:
Ad-hoc, repeatable, defined, managed, and optimized.
The way to identify where your incident processes are up to in this model are to use some easily identifiable characteristics
- ad-hoc - Processes are undocumented and what process there is changes a lot
- repeatable - Documented, and may even give the same results, but little discipline in operating the process
- defined - Documentation is well defined and have been improved over time
- managed - metrics are embedded within the processes, and used to check the effectiveness of the processes
- optimizing - found to be focused on continual improvement of the process
Given that the standard way of documenting incident response processes is via the run book, lets look at some ways of improving the effectiveness of those processes.
1. Paper Based Run Books
If you don't have procedures, written down ones with steps etc, now is the time to start. Every time you perform an incident for which you dont have a run book, transpose your notes you took during the incident into a documented step by step action sheet as to what you do next time. It doesnt have to be a huge weighty tome of information, infact a single sheet process, with a page or two of notes on what the process steps do should be more than enough.
2. Using a Wiki rather than using paper
Incident teams work effectively by collaborating during an event, an onwards through the incident until the service is recovered. During the lessons learned process step of an incident, when you walk through and find what you did good at, and what sucked, this is the time to change your run books to address those issues. Having collaborative publishing as with a Wiki allows the whole team to discuss and propose changes to your run books via the Wiki and then you can move, with team agreement, from 1.0, to 2.0 of your run books. One thing to remember, make sure you have local, offline copies of your wiki on your incident response laptops so you can refer to the documentation if your website, or network is down, or compromised. Other points to consider on the choice of wiki software, and its configuration are:
- use SSL to encrypt the connections to the wiki
- turn off default read to the wiki
- create accounts for each of your incident team, and those needed to authorize changes to your procedures
3. Automating steps within the Wiki Run Book
This is the key step in making the most of your run books. If during an incident, for example an IDS alert against your corporate web site, you will need to perform some standard steps time and time again. Lets automate them, and define them within the Wiki run book.
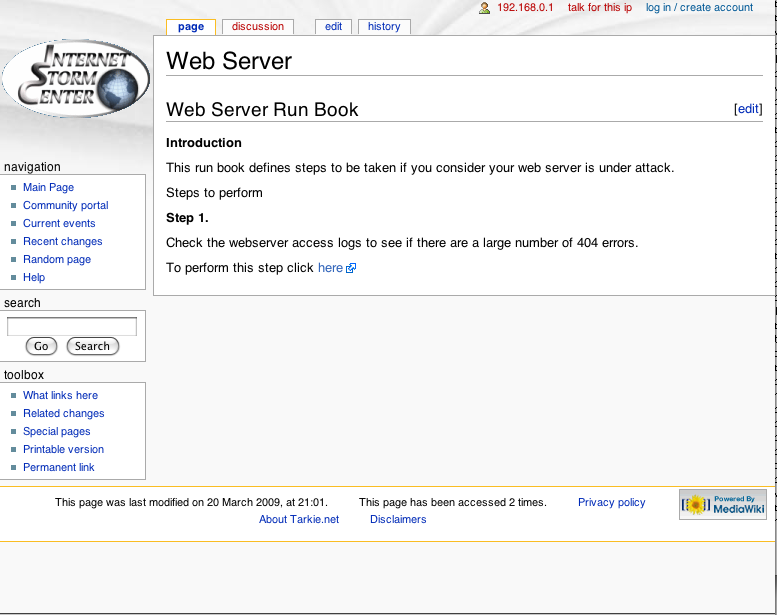
For example, grab todays web logs, and search them for entries for a particular IP address. Your run books should have this defined as a step, so on your wiki, have a link that pulls the logs, performs the grep, or other such search, and display the results for you on the web page.
For example, should you want to pull all 404 errors from your web site, you could have a link as shown in the picture below:
And this could result in
193.225.244.201 - - [10/Mar/2009:20:53:24 +0000] "GET /sql/phpMyAdmin-2.10.0-beta1/main.php HTTP/1.0" 404 234 "-" "-" 193.225.244.201 - - [10/Mar/2009:20:53:24 +0000] "GET /sql/phpMyAdmin-2.10.0-rc1/main.php HTTP/1.0" 404 232 "-" "-" 193.225.244.201 - - [10/Mar/2009:20:53:24 +0000] "GET /sql/phpMyAdmin-2.10.0.1/main.php HTTP/1.0" 404 230 "-" "-" 193.225.244.201 - - [10/Mar/2009:20:53:24 +0000] "GET /sql/phpMyAdmin-2.10.0.2/main.php HTTP/1.0" 404 230 "-" "-" 193.225.244.201 - - [10/Mar/2009:20:53:25 +0000] "GET /sql/phpMyAdmin-2.10.0/main.php HTTP/1.0" 404 228 "-" "-" 193.225.244.201 - - [10/Mar/2009:20:53:25 +0000] "GET /sql/phpMyAdmin-2.10.1-rc1/main.php HTTP/1.0" 404 232 "-" "-" 193.225.244.201 - - [10/Mar/2009:20:53:25 +0000] "GET /sql/phpMyAdmin-2.10.1/main.php HTTP/1.0" 404 228 "-" "-" 193.225.244.201 - - [10/Mar/2009:20:53:25 +0000] "GET /sql/phpMyAdmin-2.10.2-rc1/main.php HTTP/1.0" 404 232 "-" "-"
4. Producing evidence of run book adherence
In larger organizations the auditing of adherence to the steps performed during an incident will be expected, and indeed checked. So, again using your automated run book methodology, use tick boxes, radio buttons, etc, to show where decisions are made, and what choices were made during an incident. These can be logged and presented as audit evidence later on. If you have a team spread across multiple sites/countries, etc, then you could use a communications server, such as IRC, Jabber, etc, to allow people to talk about the event and then save the logs. If audit ask for decision points during an event, and where they are recorded, show them your logs. Of course, if your using communication servers, implement SSL on them, and deny access in the clear.
5. MI
Management information during an incident should describe the effectiveness of the process. Time to respond, time to step through the four steps of the incident handling process which are used during an incident. Using the automated run books method will speed up key functions within your response and allow you to demonstrate that you true are doing more for less!
Finally, if you have any tips on improving your run books, pass them along and I'll update this diary over the weekend. I am on duty again on Monday, so I'll ensure that those few of you who don't read us over the weekend are not left out!
Stealthier then a MBR rootkit, more powerful then ring 0 control, it?s the soon to be developed SMM root kit.
Joanna Rutkowska founder and CEO of Invisible Things Lab along with
Rafal Wojtczuk has released a paper on attacking SMM memory via Intel
CPU cache Poisoning. They did not release an SMM rootkit as some people
stated they would. What was released includes “totally harmless” shell code according to Ms
Rutkowska’s blog. Here is a reference to the paper.
http://invisiblethingslab.com/resources/misc09/smm_cache_fun.pdf
“System Management Mode (SMM) is the most privileged CPU operation
mode on x86/x86_64 architectures. It can be thought of as of "Ring -2"
as the code executing in SMM has more privileges than even hardware
hypervisors (VT), which are colloquially referred to as if operating in "Ring
-1".
She goes on to explain how the protection of SMM can be trivially
circumvented in just over a half page of text ending with “And that’s it!”
A talk was given today at CanSecWest on this paper by Loic Duflot of SGDN/ Central Directorate of Information Systems Security. http://cansecwest.com/agenda.html
Latest on Conficker
The researchers at SRI International updated their Conficker paper today. This is by far one of the best analysis of the Conficker malware. More malware information is available at SRI's Malware Resource Center.
Another good Conficker article was published in the New York Times today; you have to subscribe to read it but the subscription is free. Be sure to also read the NYT article about the Conficker Cabal, the group of experts working behind the scenes to bring the Conficker botnet under control.
We've got more information on Conficker in a previous diary (be sure to follow the links back to the earlier diaries about Conficker.) Also, lots of information on how to protect yourself is in this diary.
Marcus H. Sachs
Director, SANS Internet Storm Center


Comments